Otimizando Inferência de Modelos de Linguagem em Escala
Aplicações modernas de IA enfrentam um desafio crescente: fornecer respostas rápidas e econômicas através de modelos de linguagem grandes, particularmente ao processar documentos extensos ou conversas com múltiplas mensagens. O problema surge quando a inferência de modelos de linguagem se torna cada vez mais lenta e cara à medida que o comprimento do contexto aumenta, com latência crescendo exponencialmente e custos elevados a cada interação.
Essa ineficiência ocorre porque esses modelos precisam recalcular os mecanismos de atenção para todos os tokens anteriores toda vez que geram um novo token. Essa redundância cria sobrecarga computacional significativa e alta latência em sequências longas.
Entendendo o Cache KV e o Roteamento Inteligente
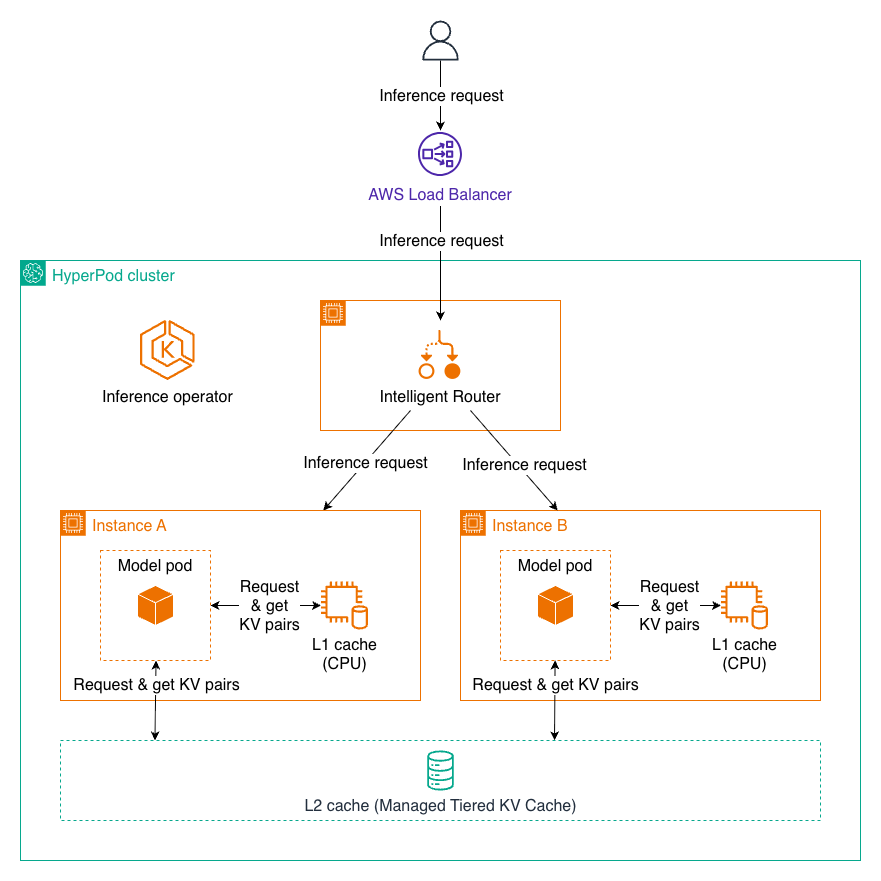
O cache KV (par chave-valor) resolve esse gargalo armazenando e reutilizando os vetores de chave-valor de cálculos anteriores, reduzindo drasticamente a latência de inferência e o tempo até o primeiro token (TTFT, ou Tempo até o Primeiro Token).
O roteamento inteligente complementa essa abordagem ao direcionar requisições com prompts compartilhados para a mesma instância de inferência, maximizando a eficiência do cache KV. Quando uma nova requisição chega, o sistema a envia para uma instância que já processou o mesmo prefixo, permitindo reutilizar os dados em cache e acelerar o processamento.
No entanto, configurar e gerenciar o framework correto para cache KV e roteamento inteligente em escala produção é complexo e requer ciclos experimentais longos. A AWS anunciou que o Amazon SageMaker HyperPod agora oferece essas capacidades através do Operador de Inferência HyperPod, simplificando significativamente essa implementação.
Capacidades Principais do Cache KV Escalonado Gerenciado
Arquitetura em Dois Níveis
O cache KV escalonado gerenciado funciona através de uma arquitetura em dois níveis, otimizada para diferentes padrões de acesso:
Cache L1 (Local): Reside na memória da CPU de cada nó de inferência e oferece acesso extremamente rápido. O cache gerencia automaticamente alocação de memória e políticas de despejo para otimizar o conteúdo armazenado em cache de maior valor.
Cache L2 (Distribuído): Opera como uma camada de cache distribuída abrangendo todo o cluster, permitindo compartilhamento de cache entre múltiplas instâncias de modelo. A AWS oferece dois backends para o cache L2:
- Cache KV Escalonado Gerenciado (recomendado): Uma solução de memória disagregada do HyperPod que oferece escalabilidade excelente para pools de terabytes, baixa latência, otimização de rede AWS, design consciente de GPU com suporte zero-copy e eficiência de custos em escala.
- Redis: Simples de configurar, funciona bem para cargas de trabalho pequenas e médias, com rico ecossistema de ferramentas e integrações.
Quando uma requisição chega, o sistema primeiro verifica o cache L1 para pares KV necessários. Se encontrados, são utilizados imediatamente com latência mínima. Se não encontrados em L1, o sistema consulta o cache L2. Se localizados lá, os dados são recuperados e opcionalmente promovidos para L1 para acesso mais rápido no futuro. Apenas se os dados não existirem em nenhum cache, o sistema executa o cálculo completo, armazenando os resultados em ambas as camadas para reutilização futura.
Estratégias de Roteamento Inteligente
O roteamento inteligente oferece quatro estratégias configuráveis para otimizar a distribuição de requisições conforme as características da carga de trabalho:
- Roteamento Ciente de Prefixo (padrão): Mantém uma estrutura de árvore rastreando quais prefixos estão em cache em quais endpoints, oferecendo desempenho geral robusto. Ideal para conversas multi-turno, bots de atendimento ao cliente com saudações padrão e geração de código com importações comuns.
- Roteamento Ciente de KV: Oferece gerenciamento de cache mais sofisticado através de um controlador centralizado que rastreia localizações de cache e trata eventos de despejo em tempo real. Excele em threads de conversas longas, fluxos de trabalho de processamento de documentos e sessões estendidas de programação onde eficiência máxima de cache é crítica.
- Roteamento Round-robin: Abordagem mais simples, distribuindo requisições uniformemente entre workers. Melhor para cenários onde requisições são independentes, como trabalhos de inferência em lote, chamadas de API stateless e testes de carga.
Impacto em Cenários do Mundo Real
As otimizações delivram benefícios tangíveis para aplicações práticas. Equipes jurídicas analisando contratos de 200 páginas agora recebem respostas instantâneas para perguntas de acompanhamento em vez de aguardar mais de 5 segundos por consulta. Chatbots de saúde mantêm fluxo de conversa natural através de diálogos com pacientes de 20+ turnos. Sistemas de atendimento ao cliente processam milhões de requisições diárias com desempenho superior e custos de infraestrutura reduzidos.
Essas otimizações tornam análise de documentos, conversas multi-turno e aplicações de inferência de alta taxa de transferência viáveis economicamente em escala empresarial.
Implementando Cache KV Escalonado Gerenciado
Pré-requisitos
Antes de começar, você precisará:
- Um cluster HyperPod criado com Amazon EKS (Elastic Kubernetes Service) como orquestrador
- Status do cluster verificado como
InService - Operador de inferência verificado e em execução
Para criar um cluster, acesse o console SageMaker AI, navegue para HyperPod Clusters e selecione Gerenciamento de Cluster. Escolha criar um novo cluster orquestrado por Amazon EKS. Para detalhes de configuração do cluster, consulte a documentação sobre criação de um cluster SageMaker HyperPod com orquestração Amazon EKS.
Se estiver usando um cluster EKS existente, você precisará configurar seus clusters HyperPod para implantação de modelo e instalar manualmente o operador de inferência.
Configurando o Manifesto de Implantação
Você pode habilitar essas funcionalidades adicionando configurações ao seu arquivo CRD (Definição de Recurso Customizado) InferenceEndpointConfig. Para um exemplo completo, visite o repositório de exemplos da AWS no GitHub.
O arquivo de configuração define variáveis de ambiente e especificações de cache. Para o cache L1, você habilita a cache na memória local. Para o cache L2, você especifica o backend (armazenamento em camadas ou Redis). A configuração de roteamento inteligente permite que você escolha a estratégia que melhor se ajusta a seu padrão de carga de trabalho.
O seguinte exemplo mostra a estrutura básica de configuração:
apiVersion: inference.sagemaker.aws.amazon.com/v1
kind: InferenceEndpointConfig
metadata:
name: ${NAME}
namespace: ${NAMESPACE}
spec:
modelName: ${MODEL_NAME}
instanceType: ${INSTANCE_TYPE}
replicas: 1
kvCacheSpec:
enableL1Cache: true
enableL2Cache: true
l2CacheSpec:
l2CacheBackend: "tieredstorage"
intelligentRoutingSpec:
enabled: true
routingStrategy: prefixawareApós preparar o manifesto, aplique a configuração e verifique o status dos pods. O sistema criará automaticamente pods de worker para modelo e um roteador inteligente para gerenciar distribuição de requisições.
Monitoramento e Observabilidade
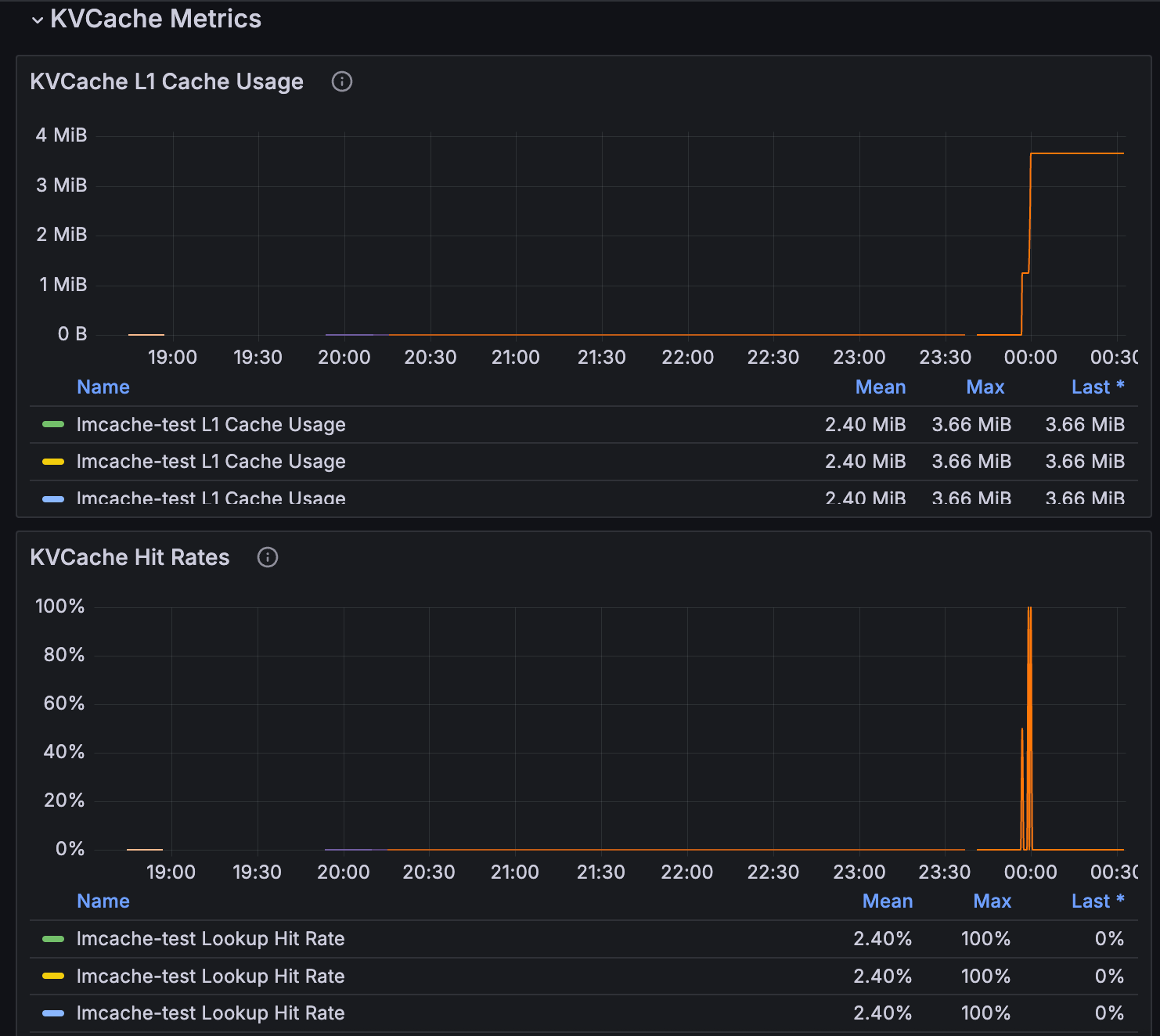
Você pode monitorar as métricas do cache KV gerenciado e roteamento inteligente através dos recursos de observabilidade do SageMaker HyperPod. Para informações detalhadas, consulte o artigo sobre aceleração do desenvolvimento de modelos de fundação com observabilidade de um clique no Amazon SageMaker HyperPod.
As métricas de cache KV estão disponíveis no painel de inferência e incluem uso de cache L1, taxas de acerto, eficiência de roteamento e latência de requisição, fornecendo visibilidade completa sobre o desempenho da sua implantação.
Resultados de Desempenho
A AWS conduziu testes abrangentes para validar melhorias de desempenho em implantações reais de LLM. Os testes utilizaram o modelo Llama-3.1-70B-Instruct implantado em 7 réplicas em instâncias p5.48xlarge (cada uma equipada com oito GPUs NVIDIA), sob padrão de tráfego de carga constante.

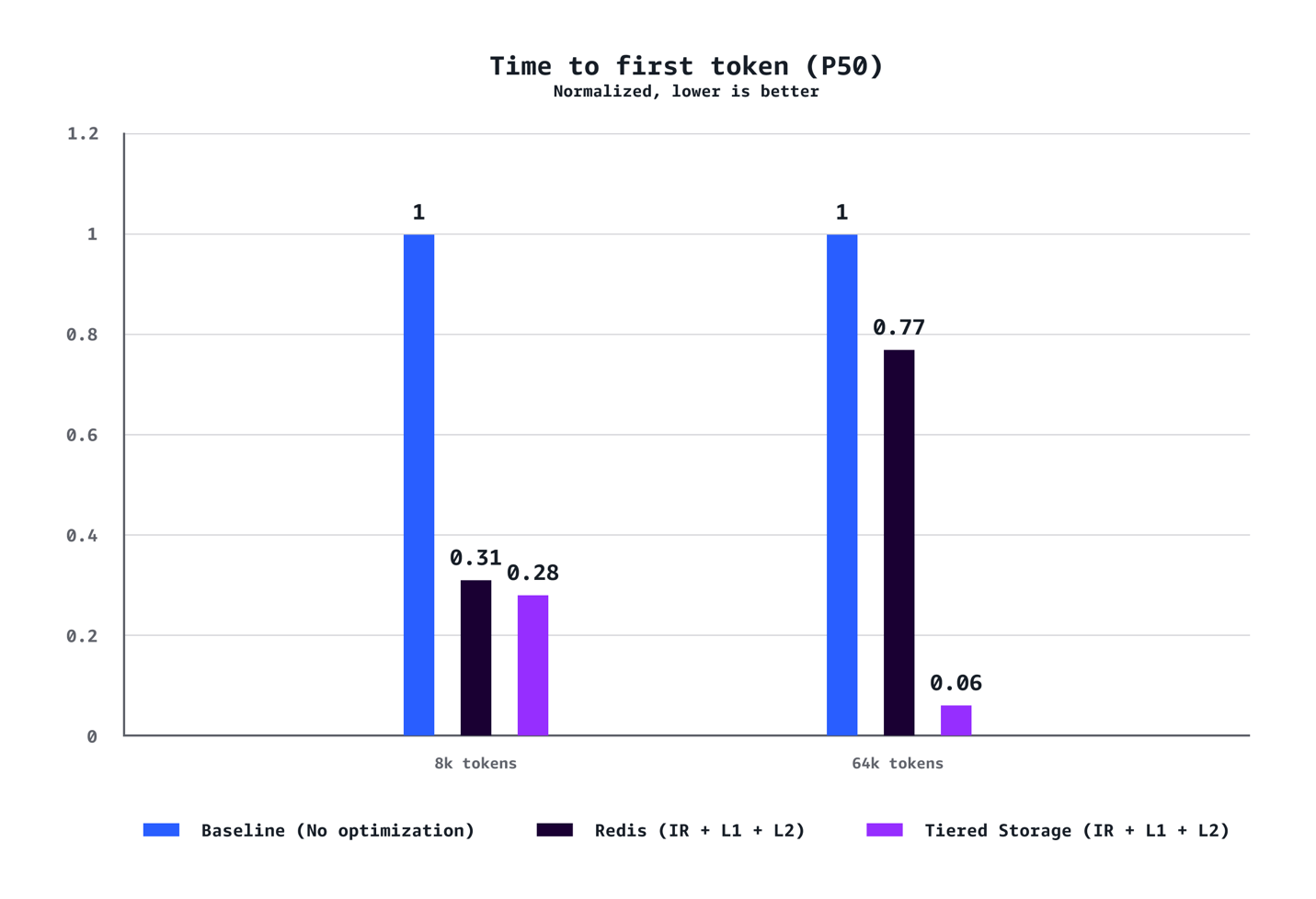
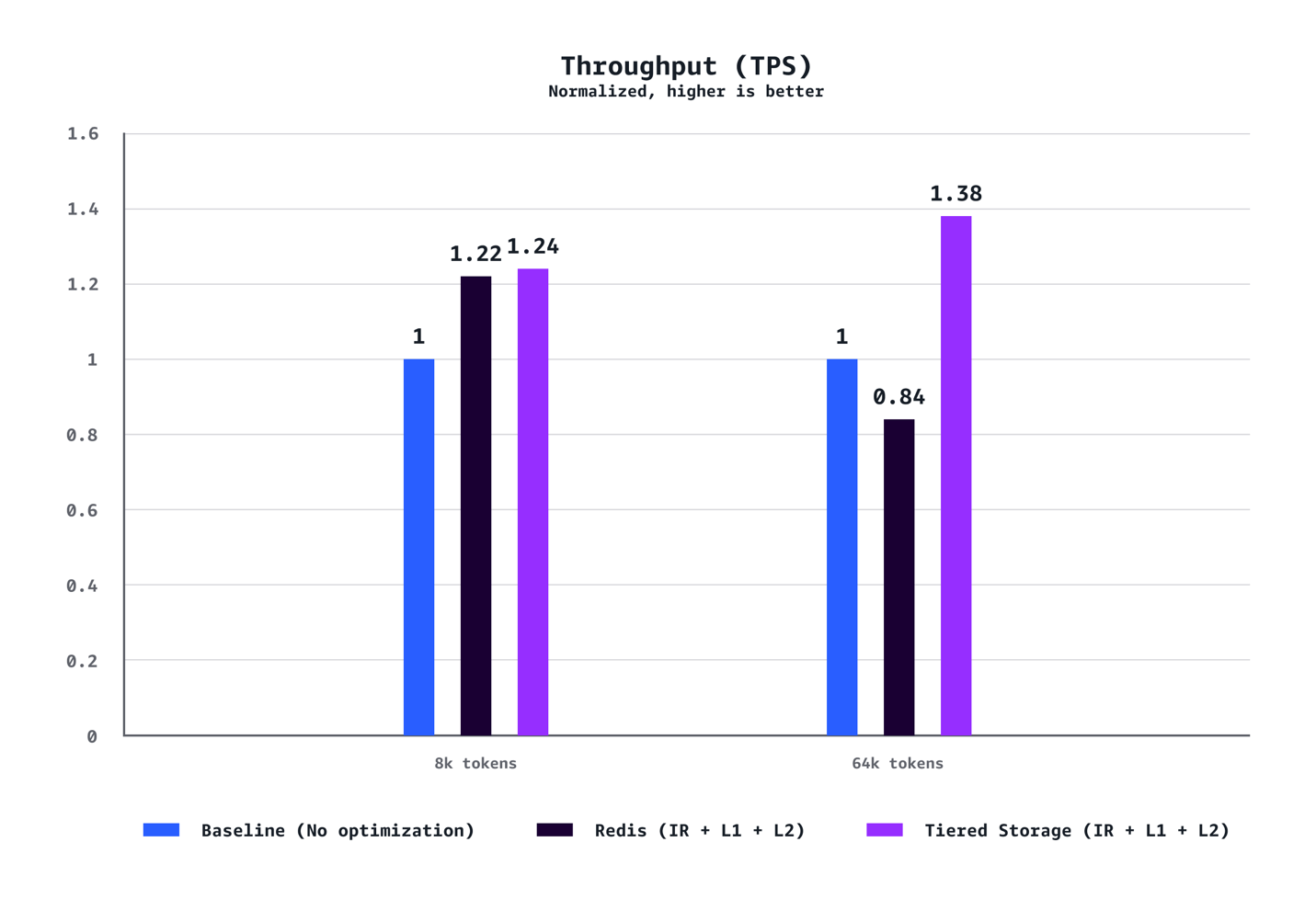
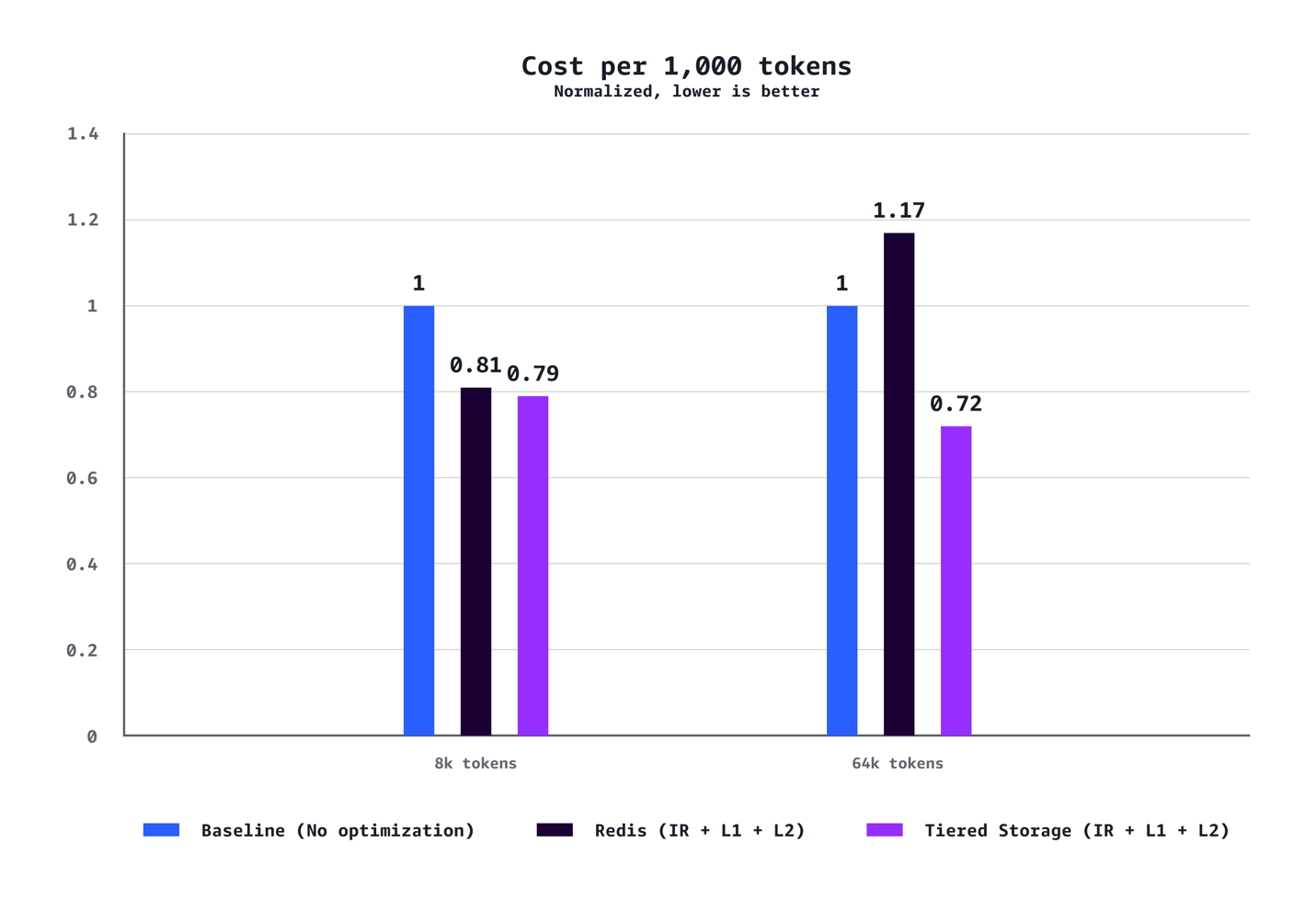
Para contextos médios (8k tokens): O sistema alcançou redução de 40% no tempo até o primeiro token no P90, redução de 72% no P50, aumento de 24% na taxa de transferência e redução de 21% em custos comparado às configurações baseline sem otimização.
Para cargas de trabalho com contextos longos (64k tokens): Os benefícios são ainda mais pronunciados, com redução de 35% no TTFT no P90, redução de 94% no P50, aumento de 38% na taxa de transferência e economia de 28% em custos.
Os ganhos em otimização aumentam dramaticamente com o comprimento do contexto. Enquanto cenários de 8k tokens demonstram melhorias sólidas em todas as métricas, cargas de trabalho de 64k tokens experimentam ganhos transformadores que fundamentalmente mudam a experiência do usuário.
Os testes também confirmaram que o armazenamento em camadas gerenciado pela AWS superou consistentemente o cache L2 baseado em Redis em todos os cenários. O backend de armazenamento em camadas ofereceu melhor latência e taxa de transferência sem o overhead operacional de gerenciar infraestrutura Redis separada, tornando-o a escolha recomendada para a maioria das implantações.
Diferentemente de otimizações tradicionais que exigem compromissos entre custo e velocidade, essa solução oferece ambos simultaneamente.
Começando
Você pode começar hoje adicionando essas configurações às suas implantações de modelo HyperPod nas regiões AWS onde o SageMaker HyperPod está disponível. Para saber mais, visite a documentação do SageMaker HyperPod nas regiões AWS onde está disponível ou consulte o guia de primeiros passos de implantação de modelo.
Fonte
Managed Tiered KV Cache and Intelligent Routing for Amazon SageMaker HyperPod (https://aws.amazon.com/blogs/machine-learning/managed-tiered-kv-cache-and-intelligent-routing-for-amazon-sagemaker-hyperpod/)
Leave a Reply