Colaboração em tempo real para resposta a incidentes
A AWS Security Incident Response agora oferece integração com o Slack, a plataforma colaborativa baseada em nuvem amplamente utilizada por times de tecnologia. Essa integração possibilita que equipes de segurança se preparem, respondam e se recuperem de eventos de segurança de maneira mais ágil e eficiente, mantendo os fluxos de notificação e comunicação já existentes nas organizações.
Funcionalidades da integração bidirecional
A integração oferece sincronização bidirecional completa: os times podem criar e atualizar casos tanto no console do Security Incident Response quanto no Slack, com replicação automática de dados entre as plataformas. Cada caso de incidente de segurança é representado como um canal dedicado no Slack, enquanto comentários e anexos são sincronizados instantaneamente.
Essa abordagem garante que os responders tenham acesso imediato às informações críticas do caso e possibilita colaboração mais eficiente, independentemente da ferramenta que cada membro do time prefira utilizar. A integração facilita o engajamento mais rápido dos times de segurança, acelerando os tempos de resposta ao adicionar automaticamente os observadores do Security Incident Response ao canal correspondente no Slack.
Arquitetura modular e extensibilidade
A solução está disponível como código aberto no repositório GitHub, permitindo que clientes e parceiros personalizem e estendam a funcionalidade conforme suas necessidades específicas. A integração utiliza o EventBridge, o que possibilita que as organizações continuem usando suas ferramentas existentes de gerenciamento de incidentes de segurança e notificações, enquanto aproveitam as capacidades do AWS Security Incident Response.
Graças à arquitetura modular, há também orientações sobre como utilizar assistentes de Inteligência Artificial, como o Amazon Q Developer ou similares, que facilitam a adição de novos alvos de integração além do Slack.
Como começar
Para iniciar o uso da integração do Security Incident Response com Slack, as organizações podem acessar o repositório GitHub da AWS. A documentação técnica para Slack fornece detalhes de implementação, enquanto o Guia do Usuário do serviço oferece informações completas sobre o AWS Security Incident Response.
A AWS anunciou uma melhoria importante no serviço Artifact: agora é possível acessar diretamente versões anteriores de relatórios de conformidade sem necessidade de contatar o suporte ou representantes da conta. Esse recurso de autoatendimento foi desenvolvido para ajudar clientes a gerenciar de forma mais eficiente sua documentação de conformidade, especialmente em momentos críticos como auditorias e avaliações de fornecedores, quando é frequente a necessidade de apresentar evidências históricas de conformidade.
Como acessar as versões anteriores
Para utilizar esse novo recurso, é necessário contar com a permissão IAM artifact:ListReportVersions, que já está incluída na política gerenciada AWSArtifactReportsReadOnlyAccess. Se você não conseguir visualizar versões anteriores de relatórios no console do Artifact, será necessário entrar em contato com o administrador da sua conta AWS para solicitar essa permissão.
Uma vez autorizado, o processo é simples: acesse o console do Artifact, navegue até a página de relatórios e selecione qualquer relatório para visualizar suas versões disponíveis. Você poderá consultar relatórios de conformidade anteriores, como SOC, ISO e C5.
Disponibilidade e cobertura histórica
A disponibilidade de versões anteriores varia conforme o programa de conformidade. Alguns relatórios oferecem histórico de vários anos anteriores, enquanto outros possuem cobertura histórica mais limitada. O recurso está disponível, no momento, nas regiões US East (N. Virginia) e AWS GovCloud (US-West).
Implementação prática
Para organizações que conduzem avaliações periódicas de conformidade, essa funcionalidade representa uma redução significativa no tempo administrativo. Em vez de depender de processos manuais ou do suporte técnico para acessar documentação anterior, as equipes agora podem consultar o histórico completo de forma autônoma e imediata através da interface do console.
Próximos passos
Para aprofundar seu conhecimento sobre como acessar versões anteriores de relatórios de conformidade, consulte a documentação técnica do Artifact. Para informações gerais sobre o AWS Artifact, visite a página oficial do serviço.
Imagine que sua empresa acaba de colocar em produção seu primeiro aplicativo de IA generativa. Os resultados iniciais são promissores, mas conforme você planeja expandir a solução para outros departamentos, surgem questões críticas: como garantir consistência em políticas de segurança? Como evitar vieses nos modelos? Como manter controle à medida que as aplicações de IA se multiplicam?
A realidade é que muitas organizações enfrentam esses mesmos desafios. Uma pesquisa de líderes empresariais em 38 países envolvendo mais de 750 executivos revelou tanto desafios quanto oportunidades ao construir uma estratégia de governança. Embora as organizações estejam comprometendo recursos significativos — a maioria planeja investir mais de 1 milhão de dólares em IA responsável — obstáculos de implementação persistem. Mais de 50% dos respondentes apontam lacunas de conhecimento como a barreira primária, enquanto 40% citam incerteza regulatória.
Porém, há uma luz no fim do túnel. Empresas com programas estabelecidos de IA responsável relatam benefícios substanciais: 42% observam melhor eficiência operacional, enquanto 34% experimentam aumento de confiança dos consumidores. Esses dados demonstram por que uma gestão robusta de riscos é fundamental para desbloquear todo o potencial da IA.
IA Responsável: Não é Negociável Desde o Primeiro Dia
A AWS, através de seu centro de inovação em IA generativa, tem observado que organizações com resultados mais sólidos incorporam governança em sua essência desde o início. Essa visão alinha-se com o compromisso da AWS com desenvolvimento responsável de IA, evidenciado pelo lançamento recente do framework AWS Well-Architected para IA Responsável, um guia abrangente para implementar práticas responsáveis ao longo de todo o ciclo de vida do desenvolvimento.
O centro de inovação tem aplicado consistentemente esses princípios abraçando uma filosofia de “responsabilidade por design”, delimitando cuidadosamente casos de uso e seguindo orientações validadas cientificamente. Essa abordagem resultou na criação da solução AI Risk Intelligence (AIRI), que transforma essas melhores práticas em controles de governança automatizados e acionáveis — tornando a implementação de IA responsável tanto alcançável quanto escalável.
Quatro Estratégias para Deployments Seguros de IA Generativa
Com base na experiência de ajudar mais de mil organizações em diversos setores e geografias, aqui estão estratégias-chave para integrar controles robustos de governança e segurança no desenvolvimento, revisão e deployment de aplicações de IA através de um processo automatizado e contínuo.
1. Adotar uma Mentalidade de Governança por Design
No centro de inovação, trabalham diariamente com organizações na vanguarda da adoção de IA generativa e agentic. Um padrão consistente emerge: enquanto a promessa da IA generativa seduz líderes de negócios, eles frequentemente enfrentam dificuldades em traçar um caminho rumo a uma implementação responsável e segura. As organizações que alcançam resultados mais impressionantes estabelecem uma mentalidade de governança por design desde o início — tratando gerenciamento de riscos de IA e considerações de IA responsável como elementos fundamentais, não como checkboxes de conformidade.
Essa abordagem transforma governança de uma barreira percebida em uma vantagem estratégica para inovar mais rapidamente, mantendo controles apropriados. Ao incorporar governança no próprio processo de desenvolvimento, essas organizações conseguem escalar suas iniciativas de IA com maior confiança e segurança.
2. Alinhar Tecnologia, Negócios e Governança
A missão principal do centro de inovação é ajudar clientes a desenvolver e implementar soluções de IA que atendam às necessidades empresariais, aproveitando otimamente os serviços da AWS. Porém, exploração técnica deve caminhar lado a lado com planejamento de governança. Pense nisto como coordenar uma orquestra — você não dirigiria uma sinfonia sem compreender como cada instrumento funciona e como harmonizam juntos. Similarmente, uma governança efetiva de IA exige compreensão profunda da tecnologia subjacente antes de implementar controles.
O centro ajuda organizações a estabelecer conexões claras entre capacidades tecnológicas, objetivos de negócios e requisitos de governança desde o início, garantindo que esses três elementos trabalhem em conjunto.
3. Integrar Segurança como Base da Governança
Após estabelecer uma mentalidade de governança por design e alinhar objetivos de negócios, tecnologia e governança, o próximo passo crucial é a implementação. A experiência mostra que segurança serve como o ponto de entrada mais efetivo para operacionalizar governança abrangente de IA. Segurança não apenas oferece proteção vital, mas também suporta inovação responsável construindo confiança na fundação de sistemas de IA.
A abordagem enfatizada pelo centro de inovação privilegia segurança-por-design ao longo de toda a jornada de implementação, desde proteção básica de infraestrutura até detecção sofisticada de ameaças em workflows complexos. Para suportar essa abordagem, a AWS oferece capacidades como o AWS Security Agent, que automatiza validação de segurança ao longo do ciclo de vida do desenvolvimento. Esse agente fronteiriço realiza revisões de segurança customizadas e testes de penetração baseados em padrões definidos centralmente, ajudando organizações a escalar sua expertise em segurança para acompanhar a velocidade de desenvolvimento.
Essa abordagem focada em segurança ancora um conjunto mais amplo de controles de governança. O framework AWS de IA Responsável unifica justiça, explicabilidade, privacidade e segurança, segurança, controlabilidade, veracidade e robustez, governança e transparência em uma abordagem coerente. Conforme sistemas de IA se integram profundamente aos processos empresariais e tomada de decisão autônoma, automatizar esses controles mantendo supervisão rigorosa torna-se crucial para escalar com êxito.
4. Automatizar Governança em Escala Corporativa
Com os elementos fundamentais em lugar — mentalidade, alinhamento e controles de segurança — organizações precisam de um meio para escalar sistematicamente seus esforços de governança. É aqui que a solução AIRI entra. Em vez de criar novos processos, ela operacionaliza os princípios e controles discutidos através de automação, em uma abordagem faseada. A arquitetura da solução integra-se perfeitamente aos workflows existentes através de um processo em três etapas: entrada do usuário, avaliação automatizada e insights acionáveis.
A solução analisa tudo, desde código-fonte até documentação de sistemas, usando técnicas avançadas como processamento automatizado de documentos e avaliações baseadas em modelos de linguagem para conduzir avaliações abrangentes de risco. Mais importante, ela realiza testes dinâmicos de sistemas de IA generativa, verificando consistência semântica e vulnerabilidades potenciais enquanto se adapta aos requisitos específicos de cada organização e padrões industriais.
Da Teoria à Prática
A verdadeira medida de uma governança de IA efetiva é como ela evolui com uma organização mantendo padrões rigorosos em escala. Quando implementada com êxito, governança automatizada permite que times se concentrem em inovação, confiantes de que seus sistemas de IA operam dentro de guardrails apropriados.
Um exemplo compelling vem da colaboração com Ryanair, o maior grupo de companhias aéreas da Europa. Enquanto escalam em direção a 300 milhões de passageiros até 2034, a Ryanair precisava de governança de IA responsável para sua aplicação de tripulação de cabine, que fornece ao pessoal de frente linhas informações operacionais cruciais. Usando Amazon Bedrock, o centro de inovação conduziu uma avaliação alimentada por IA. Isso estabeleceu gerenciamento de risco transparente e baseado em dados onde riscos eram previamente difíceis de quantificar — criando um modelo de governança de IA responsável que a Ryanair agora pode expandir por toda sua carteira de IA.
Essa implementação demonstra o impacto mais amplo de governança sistemática de IA. Organizações usando esse framework reportam consistentemente caminhos acelerados para produção, redução de trabalho manual e capacidades aprimoradas de gerenciamento de risco. Mais importante ainda, alcançaram forte alinhamento entre funções, desde times de tecnologia até legal e segurança — todos trabalhando a partir de objetivos claros e mensuráveis.
Uma Fundação para Inovação
Governança de IA responsável não é uma restrição — é um catalisador. Ao incorporar governança na urdidura do desenvolvimento de IA, organizações podem inovar com confiança, sabendo que possuem controles para escalar segura e responsavelmente. O exemplo acima demonstra como governança automatizada transforma frameworks teóricos em soluções práticas que impulsionam valor comercial mantendo confiança.
Para aprender mais, consulte as informações sobre o centro de inovação em IA generativa da AWS e como estão ajudando organizações de diferentes tamanhos implementar IA responsável para complementar seus objetivos empresariais.
Em dezembro de 2025, a AWS anunciou a abertura de uma nova localização de AWS Direct Connect dentro da CMC Tower em Hanói, Vietnã. Este é o primeiro ponto de presença do serviço Direct Connect no país e marca uma expansão significativa da infraestrutura da AWS na região do Sudeste Asiático.
A partir dessa localização, é possível estabelecer acesso privado e direto a todas as regiões públicas da AWS (com exceção daquelas localizadas na China), ao AWS GovCloud, bem como às AWS Local Zones. Isso abre novas possibilidades para empresas vietnamitas e da região que buscam conectividade otimizada com a infraestrutura de nuvem global da AWS.
Capacidades e Velocidades de Conexão
A localização em Hanói oferece opções de conectividade em múltiplas velocidades. Os clientes podem contratar conexões dedicadas de 1 Gbps, 10 Gbps e 100 Gbps conforme suas necessidades. Para as conexões de maior capacidade (10 Gbps e 100 Gbps), a AWS disponibiliza criptografia MACsec, garantindo camadas adicionais de segurança para dados em trânsito.
Entendendo o AWS Direct Connect
O serviço AWS Direct Connect funciona como um intermediário que estabelece uma conexão física e privada entre a infraestrutura da AWS e os ambientes locais dos clientes — que podem ser datacenters, escritórios ou ambientes de colocação. Diferentemente das conexões convencionais pela internet pública, as conexões via Direct Connect proporcionam uma experiência de rede mais consistente e previsível, com menor latência e maior confiabilidade.
Expansão Global da Rede de Direct Connect
A nova localização em Hanói se integra à rede global da AWS Direct Connect, que agora conta com mais de 149 localizações espalhadas pelo mundo. Essa expansão contínua reflete o compromisso da AWS em trazer conectividade de alta qualidade para regiões emergentes e mercados em crescimento.
Para obter mais informações sobre todas as localizações disponíveis do Direct Connect em todo o mundo, os usuários podem consultar a seção dedicada nos detalhes do produto. Além disso, há um guia de primeiros passos disponível para quem deseja aprender como adquirir e implantar o serviço Direct Connect.
O GuardDuty Extended Threat Detection conseguiu correlacionar sinais em múltiplas fontes de dados e elevar uma descoberta de sequência de ataque com severidade crítica. Utilizando capacidades avançadas de inteligência de ameaças e mecanismos de detecção existentes, o GuardDuty identificou proativamente essa campanha em andamento e alertou rapidamente os clientes sobre a ameaça.
A Amazon Web Services (AWS) está compartilhando descobertas relevantes e orientação de mitigação para ajudar clientes a tomar medidas apropriadas. É importante notar que essas ações não exploram uma vulnerabilidade em um serviço AWS, mas exigem credenciais válidas que um usuário não autorizado utiliza de forma indevida. Embora essas ações ocorram no domínio do cliente do modelo de responsabilidade compartilhada, a AWS recomenda passos que clientes podem adotar para detectar, prevenir ou reduzir o impacto dessa atividade.
Entendendo a campanha de mineração
A campanha de mineração de criptomoedas detectada recentemente empregou uma técnica inovadora de persistência projetada para interromper a resposta a incidentes e estender operações de mineração. A campanha contínua foi inicialmente identificada quando engenheiros de segurança do GuardDuty descobriram técnicas de ataque semelhantes sendo usadas em múltiplas contas de clientes AWS, indicando uma campanha coordenada visando clientes que usam credenciais IAM comprometidas.
Operando a partir de um provedor de hospedagem externo, o ator de ameaça rapidamente enumerou quotas de serviço do Amazon EC2 e permissões de IAM antes de implantar recursos de mineração em EC2 e ECS. Dentro de 10 minutos após o ator de ameaça obter acesso inicial, mineradores de criptomoedas estavam operacionais.
Uma técnica chave observada nesse ataque foi o uso de ModifyInstanceAttribute com desativação de terminação de API definida como verdadeira, forçando as vítimas a reativar a terminação de API antes de excluir os recursos impactados. Desabilitar proteção de terminação de instância adiciona considerações extra para capacidades de resposta a incidentes e pode interromper controles de remediação automatizados.
O uso scripted do ator de ameaça de múltiplos serviços de computação, combinado com técnicas de persistência emergentes, representa um avanço nas metodologias de persistência de mineração de criptomoedas que equipes de segurança devem estar cientes. As múltiplas capacidades de detecção do GuardDuty identificaram com sucesso a atividade maliciosa através de inteligência de ameaças de domínio/IP do EC2, detecção de anomalias e sequências de ataque EC2 do Extended Threat Detection. O GuardDuty Extended Threat Detection conseguiu correlacionar sinais como uma descoberta AttackSequence:EC2/CompromisedInstanceGroup.
Indicadores de compromisso
Equipes de segurança devem monitorar os seguintes indicadores para identificar essa campanha de mineração de criptomoedas. Como atores de ameaça frequentemente modificam suas táticas e técnicas, esses indicadores podem evoluir ao longo do tempo:
Imagem de contêiner maliciosa: A imagem Docker Hub yenik65958/secret, criada em 29 de outubro de 2025, com mais de 100.000 pulls, foi usada para implantar mineradores de criptomoedas em ambientes containerizados. Essa imagem maliciosa continha um binário SBRMiner-MULTI para mineração de criptomoedas. Essa imagem específica foi removida do Docker Hub, mas atores de ameaça podem implantar imagens semelhantes sob nomes diferentes.
Automação e ferramentas: Padrões de user agent do AWS SDK for Python (Boto3) indicando scripts de automação baseados em Python foram usados em toda a cadeia de ataque.
Domínios de mineração de criptomoedas: asia[.]rplant[.]xyz, eu[.]rplant[.]xyz e na[.]rplant[.]xyz.
Padrões de nomenclatura de infraestrutura: Grupos de auto scaling seguiam convenções de nomes específicas: SPOT-us-east-1-G*-* para instâncias spot e OD-us-east-1-G*-* para instâncias on-demand, onde G indica o número do grupo.
Análise da cadeia de ataque
A campanha de mineração de criptomoedas seguiu uma progressão de ataque sistemática em múltiplas fases.
O ataque começou com credenciais de usuário IAM comprometidas possuindo privilégios tipo administrador a partir de uma rede e localização anômala, acionando descobertas de detecção de anomalias do GuardDuty. Durante a fase de descoberta, o atacante sistematicamente explorou ambientes AWS do cliente para entender quais recursos poderia implantar. Eles verificaram quotas de serviço do Amazon EC2 (GetServiceQuota) para determinar quantas instâncias podiam lançar, depois testaram suas permissões chamando a API RunInstances múltiplas vezes com a flag DryRun habilitada.
A flag DryRun foi uma tática de reconhecimento deliberada que permitiu ao ator validar suas permissões de IAM sem realmente lançar instâncias, evitando custos e reduzindo sua pegada de detecção. Essa técnica demonstra que o ator de ameaça estava validando sua capacidade de implantar infraestrutura de mineração de criptomoedas antes de agir. Organizações que não usam tipicamente flags DryRun em seus ambientes devem considerar monitorar esse padrão de API como um indicador de aviso antecipado de compromisso.
O ator de ameaça chamou duas APIs para criar roles de IAM como parte de sua infraestrutura de ataque: CreateServiceLinkedRole para criar uma role para grupos de auto scaling e CreateRole para criar uma role para AWS Lambda. Eles então anexaram a política AWSLambdaBasicExecutionRole à role Lambda. Essas duas roles foram integrais aos estágios de impacto e persistência do ataque.
Impacto no Amazon ECS
O ator de ameaça primeiro criou dezenas de clusters ECS em todo o ambiente, às vezes excedendo 50 clusters ECS em um único ataque. Depois chamou RegisterTaskDefinition com uma imagem Docker Hub maliciosa yenik65958/secret:user. Com a mesma string usada para criação de cluster, o ator então criou um serviço, usando a definição de tarefa para iniciar mineração de criptomoedas em nós AWS Fargate de ECS.
O seguinte é um exemplo de parâmetros de solicitação de API para RegisterTaskDefinition com alocação máxima de CPU de 16.384 unidades:
A imagem maliciosa (yenik65958/secret:user) foi configurada para executar run.sh após ser implantada. O run.sh executa mineração com algoritmo randomvirel usando pools de mineração: asia|eu|na[.]rplant[.]xyz:17155. A flag nproc –all indica que o script deve usar todos os núcleos de processador.
Impacto no Amazon EC2
O ator criou dois templates de lançamento (CreateLaunchTemplate) e 14 grupos de auto scaling (CreateAutoScalingGroup) configurados com parâmetros de scaling agressivos, incluindo tamanho máximo de 999 instâncias e capacidade desejada de 20.
O seguinte é um exemplo de parâmetros de solicitação de CreateLaunchTemplate mostrando UserData sendo fornecido, instruindo as instâncias a começar mineração de criptomoedas:
O ator de ameaça criou grupos de auto scaling usando tanto Instâncias Spot quanto On-Demand para aproveitar quotas de serviço do Amazon EC2 e maximizar consumo de recursos. Os grupos Spot Instance direcionaram instâncias de GPU e aprendizado de máquina (ML) de alto desempenho (g4dn, g5, g5, p3, p4d, inf1), configuradas com alocação on-demand de 0% e estratégia otimizada para capacidade, definidas para escalar de 20 a 999 instâncias.
Os grupos On-Demand Instance direcionaram instâncias de computação, memória e uso geral (c5, c6i, r5, r5n, m5a, m5, m5n), configurados com alocação on-demand de 100%, também definidos para escalar de 20 a 999 instâncias. Após esgotar quotas de auto scaling, o ator lançou diretamente instâncias EC2 adicionais usando RunInstances para consumir a quota de instância EC2 restante.
Persistência
Uma técnica interessante observada nessa campanha foi o uso do ator de ameaça de ModifyInstanceAttribute em todas as instâncias EC2 lançadas para desabilitar terminação de API. Embora proteção de terminação de instância previna terminação acidental da instância, isso adiciona considerações extras para capacidades de resposta a incidentes e pode interromper controles de remediação automatizados.
O seguinte exemplo mostra parâmetros de solicitação de API para ModifyInstanceAttribute:
Após todas as cargas de trabalho de mineração serem implantadas, o ator criou uma função Lambda com configuração que desvia autenticação de IAM e cria um endpoint Lambda público. O ator de ameaça então adicionou uma permissão à função Lambda que permite ao principal invocar a função. Os seguintes exemplos mostram parâmetros de solicitação CreateFunctionUrlConfig e AddPermission:
Para prevenir criação de URLs Lambda públicas, organizações podem implantar políticas de controle de serviço (SCPs) que negam criação ou atualização de URLs Lambda com AuthType de “NONE”:
A abordagem multilayer de detecção do GuardDuty provou ser altamente eficaz na identificação de todos os estágios da cadeia de ataque usando inteligência de ameaças, detecção de anomalias e as capacidades recentemente lançadas de Extended Threat Detection para EC2 e ECS.
Você pode habilitar o plano de proteção foundational do GuardDuty para receber alertas sobre campanhas de mineração de criptomoedas como a descrita neste artigo. Para potencializar ainda mais as capacidades de detecção, recomenda-se fortemente habilitar GuardDuty Runtime Monitoring, que estenderá cobertura de descobertas para eventos de nível de sistema em Amazon EC2, Amazon ECS e Amazon Elastic Kubernetes Service (Amazon EKS).
Descobertas do GuardDuty para EC2
Descobertas de inteligência de ameaças para Amazon EC2 fazem parte do plano de proteção foundational do GuardDuty, que alertará sobre comportamentos de rede suspeitos envolvendo suas instâncias. Esses comportamentos podem incluir tentativas de força bruta, conexões com domínios maliciosos ou de criptografia e outros comportamentos suspeitos. Usando inteligência de ameaças de terceiros e inteligência de ameaças interna, incluindo defesa ativa de ameaças e MadPot, o GuardDuty fornece detecção sobre os indicadores neste artigo através das seguintes descobertas: CryptoCurrency:EC2/BitcoinTool.B e CryptoCurrency:EC2/BitcoinTool.B!DNS.
Descobertas do GuardDuty para IAM
As descobertas IAMUser/AnomalousBehavior abrangendo múltiplas categorias de tática (PrivilegeEscalation, Impact, Discovery) demonstram a capacidade de aprendizado de máquina do GuardDuty em detectar desvios do comportamento normal do usuário. No incidente descrito neste artigo, as credenciais comprometidas foram detectadas porque o ator de ameaça as usou a partir de uma rede e localização anômala e chamou APIs que eram incomuns para as contas.
Runtime Monitoring do GuardDuty
O GuardDuty Runtime Monitoring é um componente importante para correlação de sequência de ataque Extended Threat Detection. O Runtime Monitoring fornece sinais de nível de host, como visibilidade do sistema operacional, e estende cobertura de detecção analisando logs de nível de sistema indicando execução de processo malicioso a nível de host e contêiner, incluindo execução de programas de mineração de criptomoedas em suas cargas de trabalho.
Lançado na re:Invent 2025, a descoberta AttackSequence:EC2/CompromisedInstanceGroup representa uma das mais recentes capacidades Extended Threat Detection no GuardDuty. Esse recurso usa algoritmos de inteligência artificial e aprendizado de máquina para correlacionar automaticamente sinais de segurança em múltiplas fontes de dados a fim de detectar padrões de ataque sofisticados de grupos de recursos de EC2. Embora AttackSequences para EC2 estejam incluídas no plano de proteção foundational do GuardDuty, recomenda-se fortemente habilitar Runtime Monitoring. O Runtime Monitoring fornece insights e sinais chave de ambientes de computação, possibilitando detecção de atividades suspeitas de nível de host e melhorando correlação de sequências de ataque. Para sequências de ataque AttackSequence:ECS/CompromisedCluster, Runtime Monitoring é obrigatório para correlacionar atividade de nível de contêiner.
Recomendações de monitoramento e remediação
Para proteger contra ataques semelhantes de mineração de criptomoedas, clientes AWS devem priorizar controles fortes de gestão de identidade e acesso. Implemente credenciais temporárias em vez de chaves de acesso de longa duração, aplique autenticação multifator (MFA) para todos os usuários e aplique privilégio mínimo aos principais de IAM limitando acesso apenas às permissões necessárias.
Você pode usar AWS CloudTrail para registrar eventos em serviços AWS e consolidar logs em uma única conta para disponibilizá-los às equipes de segurança acessarem e monitorarem. Para saber mais, consulte Recebendo arquivos de log CloudTrail de múltiplas contas na documentação do CloudTrail.
Confirme que o GuardDuty está habilitado em todas as contas e regiões com Runtime Monitoring habilitado para cobertura abrangente. Integre o GuardDuty com AWS Security Hub e Amazon EventBridge ou ferramentas de terceiros para habilitar fluxos de trabalho de resposta automatizados e remediação rápida de descobertas de alta severidade. Implemente controles de segurança de contêiner, incluindo políticas de varredura de imagem e monitoramento para solicitações de alocação de CPU incomuns em definições de tarefa ECS. Finalmente, estabeleça procedimentos específicos de resposta a incidentes para ataques de mineração de criptomoedas, incluindo passos documentados para lidar com instâncias com terminação de API desabilitada—uma técnica usada por esse atacante para complicar esforços de remediação.
Organizações empresariais estão rapidamente evoluindo de experimentos com IA generativa para implantações em produção e soluções de IA agentic complexas. Esse movimento traz novos desafios em escalabilidade, segurança, governança e eficiência operacional. A série de posts introduz GenAIOps, que aplica princípios de DevOps a soluções de IA generativa, com implementação demonstrada através de aplicações alimentadas pelo Amazon Bedrock, um serviço gerenciado que oferece uma seleção de modelos de fundação (FMs) líderes da indústria.
Por anos, empresas implementaram com sucesso práticas DevOps no ciclo de vida de aplicações, otimizando integração contínua, entrega e implantação de soluções tradicionais. Conforme progridem em sua adoção de IA generativa, descobrem que as práticas DevOps convencionais não são suficientes para gerenciar cargas de IA em escala. Enquanto DevOps tradicional enfatiza colaboração entre equipes e lida com sistemas determinísticos e previsíveis, a natureza não-determinística e probabilística das saídas de IA exige uma abordagem diferente.
Benefícios do GenAIOps
GenAIOps ajuda as organizações em diversos aspectos:
Confiabilidade e mitigação de riscos: Defende contra alucinações, lida com não-determinismo e permite atualizações seguras de modelos com guardrails, pipelines de avaliação e monitoramento automatizado.
Escala e desempenho: Dimensiona para centenas de aplicações mantendo baixa latência e consumo eficiente de custos.
Melhoria contínua e excelência operacional: Constrói ambientes consistentes, reutiliza e versiona ativos de IA generativa, gerencia ciclo de vida de contexto e modelos.
Segurança e conformidade: Robustez em diferentes níveis — modelos, dados, componentes, aplicações e endpoints, abordando ataques de injeção de prompt, vazamento de dados e acesso não autorizado.
Controles de governança: Estabelece políticas claras e responsabilidade sobre dados sensíveis e propriedade intelectual, alinhando com requisitos regulatórios.
Otimização de custos: Otimiza utilização de recursos e gerencia risco de gastos excessivos.
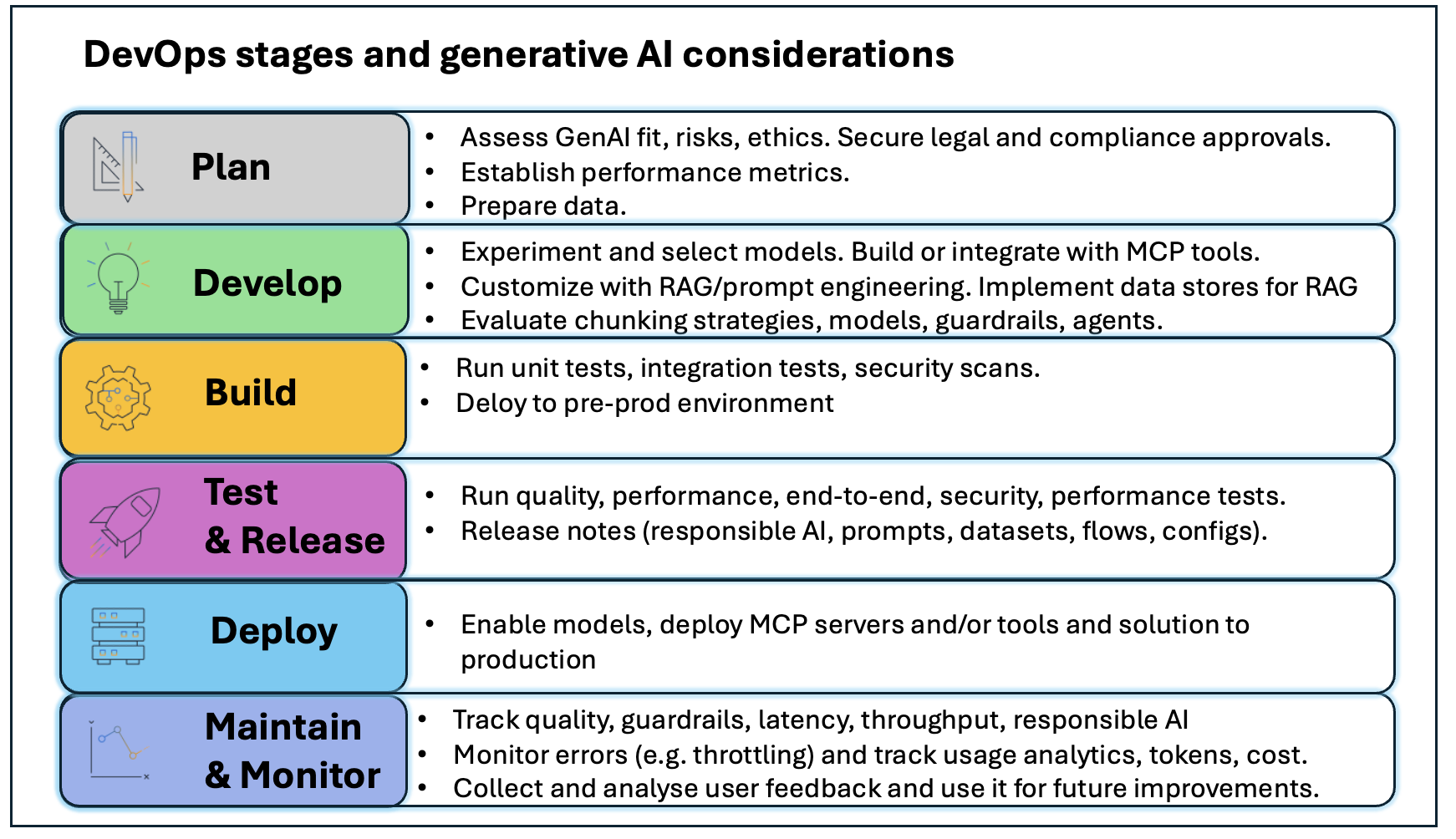
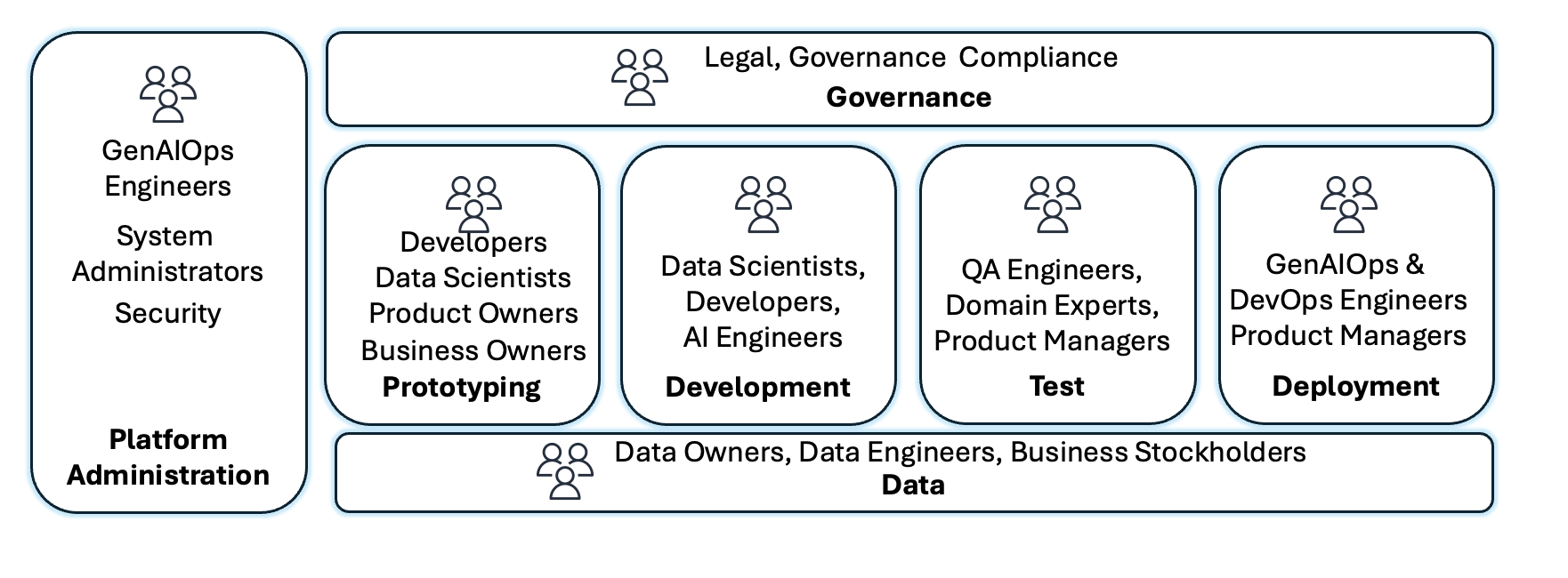
A implementação de GenAIOps expande papéis e processos para enfrentar desafios únicos associados à IA generativa. Proprietários de produto definem e priorizam casos de uso, estabelecem datasets de prompt de referência e validam adequação através de prototipagem rápida. Equipes GenAIOps e de plataforma padronizam infraestrutura de conta e provisionam ambientes para consumo de modelos, personalização, armazenamento de embeddings e orquestração de componentes, configurando pipelines de Integração Contínua/Entrega Contínua (CI/CD) com infraestrutura como código.
Equipes de segurança implementam defesa em profundidade com controles de acesso, protocolos de criptografia e guardrails, monitorando continuamente ameaças emergentes. Especialistas em risco, legal, governança e ética estabelecem frameworks de IA responsável e alcançam alinhamento regulatório. Equipes de dados coletam, preparam e mantêm datasets de alta qualidade. Engenheiros de IA e cientistas de dados desenvolvem código de aplicação, implementam técnicas de engenharia de prompt e constroem fluxos com intervenção humana.
Organizações novas em IA generativa começam com alguns projetos de prova de conceito (POCs) para demonstrar valor. Recursos são limitados e pequenos grupos de adotantes antecipados lideram. Governança é informal, com reuniões espontâneas com equipes legais. A arquitetura DevOps deve servir como baseline, com contas separadas para desenvolvimento, pré-produção e produção, isolamento de ambientes, e controle de custos por ambiente.
Implementação prática em quatro passos
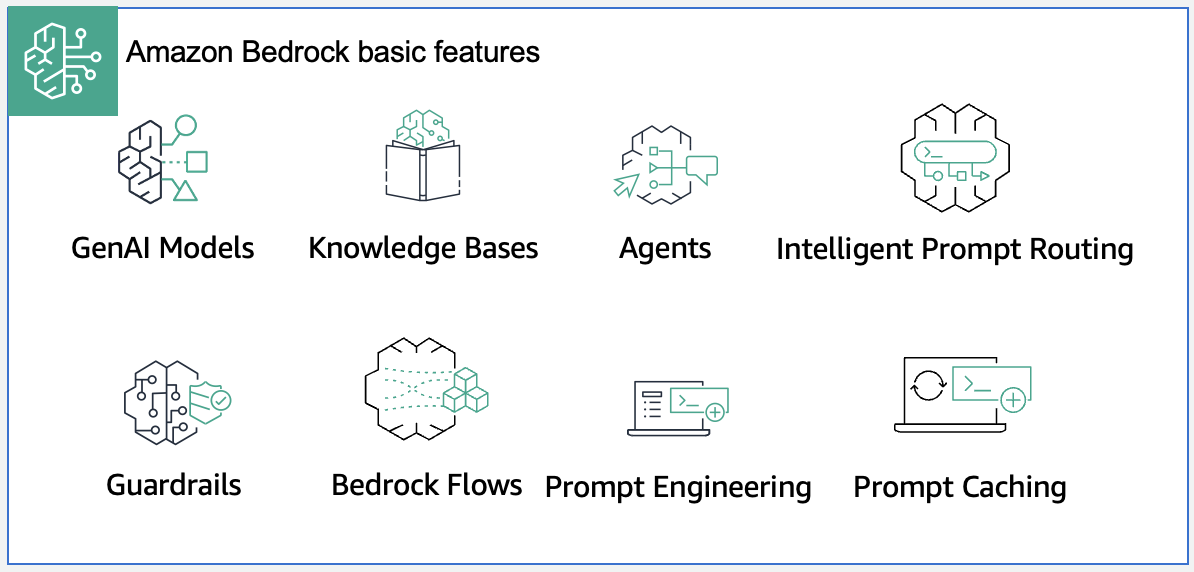
Passo 1: Gerenciar dados para aplicações de IA generativa — Dados servem três funções críticas: potencializar sistemas de Retrieval Augmented Generation (RAG), fornecer verdade fundamental para avaliação de modelos e viabilizar treinamento e ajuste fino. Com Amazon Bedrock, você pode consultar banco de dados de vetores como Amazon OpenSearch Service ou usar Amazon Bedrock Knowledge Bases, uma capacidade gerenciada que implementa todo o fluxo RAG sem integrações customizadas. Configure guardrails para bloquear informações pessoais identificáveis (PII) que não devem ser enviadas ao modelo.
Passo 2: Estabelecer ambiente de desenvolvimento — Integre FMs e capacidades de IA generativa durante prototipagem em desenvolvimento. Use Amazon Bedrock Prompt Management para criar, testar, gerenciar e otimizar prompts. Use Amazon Bedrock Flows para fluxos multietapas como pipelines de análise de documentos. Configure Amazon Bedrock Guardrails para controles de segurança.
Passo 4: Adicionar testes de IA ao pipeline CI/CD — Após identificar modelo, prompts e configurações ótimos, faça commit ao repositório de aplicação para ativar o pipeline CI/CD. O pipeline deve executar testes de avaliação predefinidos como portão de qualidade essencial. Quando testes passam nos limites de acurácia, segurança e desempenho, o pipeline implanta em pré-produção para validação final.
Passo 5: Monitorar solução de IA generativa — Com observabilidade de IA generativa, ganhe visibilidade para equilibrar custo, desempenho e latência. Monitore métricas operacionais (saúde do sistema, latência de aplicação com breakdown para operações de recuperação, inferência de modelo, uso de tokens), exceções de runtime (rate limiting, excedência de quotas de token), métricas de qualidade (relevância, correção, coerência de resposta), auditoria (logs de interações do usuário) e guardrails (tentativas de injeção de prompt, vazamento de PII).
Conforme as organizações entram no estágio de produção, estabelecem centros de excelência de IA generativa com papéis especializados: engenheiros de prompt, especialistas em avaliação de IA e engenheiros GenAIOps. Treinamento sistemático é implantado, conformidade transita para automação política, e colaboração move-se de coordenação informal para fluxos estruturados com handoffs definidos.
Padronizar repositórios de código e componentes reutilizáveis: Crie blueprints versionados e reutilizáveis para prompts, configuração de modelos e guardrails. Um template de prompt inclui variáveis substituíveis para acelerar engenharia de prompt. Armazene centralmente templates de prompt em catálogo. Para ferramentas de otimização, Prompt optimization in Amazon Bedrock ajuda refinar prompts. Armazene fluxos end-to-end como código no repositório para rastreamento de versão e implantação contínua.
Avaliação automatizada e loops de feedback: Armazene pipelines de avaliação como ativos compartilhados e deployáveis mantidos e versionados em repositório. Para avaliações que incluem revisão humana, use human-based model evaluation em Amazon Bedrock para orquestrar fluxos de avaliação humana.
Muitas organizações progridem de aplicações iniciais com LLM e implementações RAG para arquiteturas sofisticadas baseadas em agentes. Um agente de IA é um sistema autônomo que combina LLMs com ferramentas e fontes de dados externas para perceber seu ambiente, raciocinar, planejar e executar tarefas multietapas complexas com mínima intervenção humana.
A natureza probabilística de alguns componentes traz novos desafios. AgentOps estende GenAIOps para endereçar esses desafios, sendo tema de parte 2 desta série, que mergulha em AgentOps e designs de solução para sistemas multi-agente com Amazon Bedrock AgentCore.
Conclusão
Implementar GenAIOps alinha-se com o estágio de adoção de IA generativa de sua organização, acelera desenvolvimento através de avaliação sistemática e ativos reutilizáveis, e estabelece monitoramento robusto para soluções de IA generativa. Ao aplicar essas práticas, você mitiga riscos e maximiza valor empresarial com as capacidades gerenciadas do Amazon Bedrock.
Além do Agente Único: Por Que Orquestração Importa
Agentes de IA baseados em grandes modelos de linguagem revolucionaram a forma como abordamos tarefas multietapas complexas. No entanto, conforme os desafios do mundo real se tornam mais sofisticados, fica evidente que um único agente nem sempre é suficiente. Considere o planejamento de uma viagem de negócios: enquanto uma entidade busca voos respeitando restrições de horário, outra pesquisa acomodações perto dos locais de reunião, e uma terceira coordena o transporte terrestre. Cada uma dessas atividades demanda ferramentas e conhecimento de domínio específicos.
O desafio central é orquestrar a comunicação entre múltiplos agentes especializados de forma previsível e confiável. Sem uma estrutura adequada, as interações entre agentes podem se tornar caóticas, dificultando a depuração, monitoramento e escalabilidade em ambientes de produção. A orquestração resolve esse problema definindo fluxos de trabalho explícitos que determinam quando cada agente atua, como se comunicam e como suas saídas se integram numa solução coerente.
Apresentando Strands Agents: Framework para Orquestração de IA
Strands Agents é um framework de código aberto recentemente lançado pela AWS, projetado especificamente para construir sistemas de IA orquestrados em produção. O framework simplifica o desenvolvimento de agentes abstraindo o ciclo do agente em três componentes fundamentais:
Provedor de Modelo: o motor de raciocínio (como Claude no Amazon Bedrock)
Instrução do Sistema: diretrizes que definem o papel e as limitações do agente
Conjunto de Ferramentas: as APIs ou funções que o agente pode invocar
Esse design modular permite começar com sistemas simples de um único agente e evoluir para arquiteturas sofisticadas com múltiplos agentes. O Strands inclui suporte nativo para operações assíncronas, gerenciamento de estado de sessão e integrações com diversos provedores incluindo Amazon Bedrock, Anthropic e Mistral. Além disso, se integra perfeitamente com serviços AWS como Lambda, Fargate e AgentCore.
O que torna o Strands particularmente potente é sua capacidade de orquestração multi-agente. Os usuários podem compor agentes de várias formas: usar um agente como ferramenta de outro, transferir controle entre agentes, ou coordenar múltiplos agentes trabalhando em paralelo. A API GraphBuilder permite conectar agentes em fluxos estruturados, capacitando-os a colaborar em tarefas complexas de forma controlada e previsível.
Para implantações em produção, o Strands oferece observabilidade de nível empresarial através da integração com OpenTelemetry. Isso fornece rastreamento distribuído por todo o sistema de agentes, facilitando a depuração e o monitoramento de desempenho conforme os usuários escalam de protótipos para cargas de trabalho em produção.
Fundamentos da Orquestração com Strands
O Padrão ReAct: Abordagem Padrão Atual
O padrão ReAct (Raciocínio + Ação) é a abordagem padrão para a maioria dos agentes de IA hoje. Ele combina planejamento, invocação de ferramentas e síntese de respostas em um único ciclo de agente. O agente raciocina em linguagem natural para decidir o próximo passo, invoca uma ferramenta se necessário, observa a saída e continua raciocinando com essa observação até produzir uma resposta final.
Embora funcione bem para tarefas simples, essa abordagem cria problemas em cenários complexos. O agente pode invocar ferramentas repetidamente sem uma estratégia clara, misturar coleta de evidências com conclusões, ou precipitar-se para uma resposta sem verificação adequada. Esses problemas se tornam críticos em aplicações que exigem raciocínio estruturado, verificações de conformidade ou validação em múltiplas etapas.
Por Que Orquestração Muda o Jogo
Em vez de um único agente fazendo tudo, a orquestração permite criar agentes especializados com papéis distintos na resolução do problema. Um agente pode planejar a abordagem, outro executa o plano, e um terceiro sintetiza os resultados. Os usuários conectam esses agentes em fluxos de trabalho controlados que se adequam às exigências específicas.
Na prática, a orquestração com Strands utiliza um modelo de execução em grafo. Cada nó é um agente especializado, as arestas definem como as informações fluem entre agentes, e a estrutura torna os passos de raciocínio visíveis e depuráveis. Diferentemente do ReAct, onde a tomada de decisão é implícita, os grafos expõem cada etapa: qual agente produziu qual saída, quando ficou disponível e como o próximo agente a utilizou.
O Strands fornece quatro componentes fundamentais para qualquer padrão de orquestração:
Nós: agentes que encapsulam lógica ou expertise específica
Arestas: conexões que definem ordem de execução e fluxo de dados
AgentResult: formato de saída padronizado de cada agente
GraphResult: rastreamento completo da execução com timings, saídas e caminhos percorridos
Três Padrões de Orquestração em Ação
ReWOO: Planejamento Desacoplado da Execução
ReWOO (Raciocínio Sem Observação) redefine como as ferramentas são utilizadas separando planejamento, execução e síntese em estágios distintos. Mantém um único executor de ferramentas para todas as APIs de companhia aérea, mas aplica separação rigorosa entre planejamento, execução e síntese ao redor dele. No Strands, isso se torna um grafo pequeno e explícito onde cada nó retorna um resultado tipado.
A decomposição em três fases funciona assim:
Planejador: produz apenas um plano, em formato estritamente definido
Executor: interpreta o plano, resolve argumentos, invoca ferramentas e acumula evidências em estrutura normalizada
Sintetizador: lê evidências (resultados das ferramentas, não as ferramentas diretamente) e compõe a resposta final
Desacoplar execução do planejamento torna o uso de ferramentas previsível e aplicável em termos de políticas: o executor só pode executar o que o plano autoriza. Além disso, mantém os efeitos das ferramentas e a tomada de decisão auditáveis, evitando chamadas “escondidas” na etapa final.
O planejador ReWOO gera um programa declarativo descrevendo uso de ferramentas, não uma resposta. Um plano efetivo enumera o conjunto permitido de nomes de ferramentas com argumentos, fornece exemplos práticos de como planejar para responder a consultas dos usuários, e força o formato de saída. Por exemplo:
Um plano estruturado é pronto para auditoria e minimiza ambiguidades. Também possibilita verificações estáticas (por exemplo, “apenas essas ferramentas são permitidas”) antes de qualquer execução.
Reflexão: Refino Iterativo Através de Crítica
Reflexão é um padrão em que um agente gera uma resposta candidata e uma crítica dessa resposta, depois usa a crítica para revisar a resposta em um ciclo limitado. O objetivo não é “tentar novamente” às cegas, mas direcionar revisões baseadas em feedback explícito e processável por máquina (por exemplo, restrições violadas, verificações ausentes).
O grafo de Reflexão possui 2 nós construídos com GraphBuilder. O nó de Rascunho gera uma resposta inicial e reflexão inicial. O nó de Revisor itera entre melhorar a consulta, revisar e refletir sobre a resposta, invocando ferramentas conforme necessário.
O nó de Rascunho invoca o executor de ferramentas para produzir uma resposta inicial. Imediatamente depois, executa uma passagem focada de “reflexão” invocando o modelo de linguagem com um prompt que identifica lacunas (restrições violadas, verificações ausentes, raciocínio fraco) e retorna um payload compacto que o revisor pode interpretar deterministicamente com rótulos como Resposta, Auto-Reflexão, Necessita-Revisão e Consulta-do-Usuário.
O nó de Revisor interpreta o payload do rascunho, decodifica os rótulos e decide se revisão é justificada. Em caso afirmativo, melhora a consulta original baseado na crítica e re-invoca o executor de ferramentas para produzir uma resposta revisada. Depois reflete novamente usando os mesmos rótulos. Esse ciclo é limitado (por exemplo, até 3 passagens) e para assim que a crítica retorna Necessita-Revisão: Falso.
ReWOO Guiado por ReAct: Equilibrando Governança e Flexibilidade
Ao considerar os prós e contras de ReWOO (governança e auditabilidade), ReAct (velocidade e flexibilidade) e Reflexão (qualidade via crítica), um padrão híbrido combina a disciplina de planejamento do ReWOO com a agilidade local do ReAct.
Um Planejador ReWOO emite primeiro um programa rígido e indexado por etapas (#E1…#En) que nomeia as ferramentas e sua ordem. A execução depois muda para um ciclo ReAct guiado por plano que roda dentro de cada etapa: o agente raciocina → valida argumentos de evidências anteriores → chama a ferramenta autorizada → observa e (se necessário) faz uma passagem leve de refinamento.
Isso preserva garantias globais (sem novas ferramentas, sem reordenação, portões de política antes de mutações) enquanto mantém flexibilidade local para ligação de argumentos e micro-decisões. Comparado ao ReAct puro, o plano fornece governança e idempotência — o agente não consegue vagar ou mutar cedo. Comparado ao ReWOO puro, o ciclo interno em cada etapa lida com a desordem do mundo real (ligação de argumentos, retentativas menores) sem re-planejamento. Diferentemente da Reflexão, evita sobrecarga de crítica multi-passagem em tarefas diretas enquanto ainda produz um rastro auditável.
Quando Usar Cada Padrão
ReAct é a opção mais rápida para tarefas lineares e óbvias. Use quando há uma atualização simples e inequívoca ou busca com 1–2 chamadas de ferramenta e sem trade-offs. A força é latência mais baixa; o cuidado é que pode pular verificações de política e mutar inseguramente se não for cuidadoso.
ReWOO é apropriado quando você precisa de dependências ordenadas e portões de política antes de qualquer mutação. Use para verificar elegibilidade antes de buscar, depois atualizar. A força é fluxo de dados transparente e resultados auditáveis em grafo; o cuidado é que a resolução de argumentos exige contexto rico se não usar um modelo de linguagem.
Reflexão destaca-se em decisões multi-restrição, trade-offs, ou nuances de política que exigem comparar opções. Use para itinerários mais baratos sob regras de pagamento, upgrade de voos com verificações de elegibilidade, ou qualquer cenário exigindo raciocínio sobre alternativas. A força é melhor qualidade de resposta através de crítica estruturada; o cuidado é latência mais alta — pode fazer perguntas demais em edições triviais a menos que critique seja limitada.
Resultados em Cenários Reais
Os padrões foram testados no conjunto de dados τ-Bench do domínio aéreo, que inclui mais de 300 entradas de voos, 500 perfis sintéticos de usuários, mais de 2.000 reservas pré-geradas, políticas detalhadas de companhia aérea e 50 cenários estruturados do mundo real.
Em tarefas simples como alteração de nome de passageiro, ReAct foi mais rápido (8s) oferecendo um preview preciso e confirmação com um clique. Em consultas complexas envolvendo múltiplas restrições de pagamento, Reflexão foi mais lenta (116s) mas mais alinhada com as instruções exatas do usuário. ReWOO ofereceu um meio-termo: decomposição sólida com fluxo de dados transparente, mas levemente mais lento que ReAct em casos simples.
Conclusão
A orquestração move agentes de IA de sistemas monolíticos únicos para arquiteturas precisas e controladas. O Strands Agents oferece componentes e padrões que permitem aos desenvolvedores escolher a estratégia de orquestração que melhor corresponde à estrutura de dependências e perfil de risco de seus casos de uso.
O modelo de execução em grafo do Strands, com handoffs tipados, rastros de execução e contratos de ferramentas aplicáveis, torna possível ajustar padrões por caso de uso: ciclos apertados para operações CRUD simples, planejar-executar-sintetizar para atualizações governadas, refletir-revisar para análise de opções—tudo enquanto se limitam efeitos colaterais e desvio de modelo.
Para construir agentes de produção, trate a orquestração como o plano de controle: escolha o padrão que combina com sua estrutura de dependências e perfil de risco, depois instrumente-o. Para exemplos de ponta a ponta, prompts e grafos executáveis, visite este repositório no GitHub.
Compreendendo o Desafio do Carregamento de Dados em ML
O Amazon Simple Storage Service (S3) é um serviço altamente elástico que se adapta automaticamente conforme a demanda das aplicações, oferecendo a performance de throughput necessária para cargas de trabalho modernas de aprendizagem de máquina. Conectores clientes de alto desempenho, como o Amazon S3 Connector para PyTorch e o Mountpoint para Amazon S3, possibilitam integração nativa ao S3 dentro de pipelines de treinamento, eliminando a necessidade de lidar diretamente com APIs REST do S3.
Este artigo examina técnicas práticas e recomendações para otimizar a throughput em cargas de trabalho de ML que leem dados diretamente de buckets S3 de propósito geral. Muitas das estratégias de otimização apresentadas são aplicáveis a diferentes arquiteturas de armazenamento. A AWS validou essas recomendações através de benchmarks em uma carga de trabalho representativa de visão computacional—uma tarefa de classificação de imagens com dezenas de milhares de arquivos JPEG pequenos.
Gargalos em Pipelines de Treinamento de ML
Embora GPUs desempenhem um papel vital na aceleração de computações de ML, o treinamento é um processo multifacetado com diversos estágios interdependentes—qualquer um deles pode se tornar um gargalo crítico.
Um pipeline típico de treinamento end-to-end passa por quatro etapas recorrentes de alto nível:
Leitura de amostras de treinamento do armazenamento persistente para a memória
Pré-processamento de amostras em memória (decodificação, transformação e aumento de dados)
Atualização de parâmetros do modelo com base em gradientes computados e sincronizados entre GPUs
Salvamento periódico de checkpoints para tolerância a falhas
A throughput efetiva de qualquer pipeline de ML é limitada pelo seu estágio mais lento. Enquanto a computação dos parâmetros do modelo (etapa 3) é o objetivo final, cargas de trabalho de ML em nuvem enfrentam desafios únicos. Em ambientes de nuvem, onde recursos de computação e armazenamento são tipicamente desacoplados por design, o pipeline de entrada de dados (etapas 1 e 2) frequentemente emerge como gargalo crítico.
Mesmo as GPUs mais modernas não conseguem acelerar o treinamento se ficarem ociosas esperando por dados. Quando ocorre escassez de dados, investimentos adicionais em hardware de computação mais poderoso geram retornos diminutos—uma ineficiência custosa em ambientes de produção. Maximizar a utilização de GPU requer otimização cuidadosa do pipeline de dados para garantir um fluxo contínuo de amostras de treinamento prontas para consumo pelos GPUs.
Entendendo Padrões de Acesso: Leitura Sequencial versus Aleatória
Um dos fatores mais importantes que influenciam a performance do carregamento de dados do S3 é o padrão de acesso aos dados durante o treinamento. A distinção entre leituras sequenciais e aleatórias desempenha um papel determinante na throughput e latência geral. Compreender como esses padrões de acesso interagem com as características subjacentes do S3 é fundamental para projetar pipelines de entrada eficientes.
A leitura de dados do S3 apresenta comportamento similar ao de unidades de disco rígido (HDDs) tradicionais com braços atuadores mecânicos. HDDs leem blocos de dados sequencialmente quando estão contíguos, permitindo que o braço minimize o movimento. Leituras aleatórias, por outro lado, exigem que o braço salte pela superfície do disco para acessar blocos espalhados, introduzindo atrasos pela reposição física do braço.
Ao acessar dados no S3, a situação é parcialmente similar. Cada requisição S3 incorre em uma sobrecarga de time-to-first-byte (TTFB) antes que a transferência de dados comece. Essa sobrecarga compreende vários componentes: estabelecimento de conexão, latência de round-trip de rede, operações internas do S3 (localização e acesso aos dados em disco) e tratamento de resposta no cliente. Enquanto o tempo de transferência escala com o tamanho dos dados, a sobrecarga TTFB é largamente fixa e independente do tamanho do objeto—um aspecto crucial para compreender o desempenho.
Em cargas de trabalho de ML, chamamos de padrão de leitura aleatória quando datasets consistem em numerosos arquivos pequenos armazenados no S3, cada arquivo contendo uma amostra de treinamento. Leitura aleatória também ocorre quando scripts de treinamento buscam amostras de diferentes partes dentro de um arquivo shard maior, usando requisições S3 GET com byte-range.
Padrões de leitura sequencial, por outro lado, ocorrem quando datasets são organizados em shards de arquivo grandes, cada shard contendo muitas amostras de treinamento, iteradas sequencialmente. Uma única requisição S3 GET pode recuperar múltiplas amostras, possibilitando throughput de dados muito mais alto que no cenário de leitura aleatória. Essa abordagem também simplifica o pré-carregamento de dados, permitindo antecipar, buscar e armazenar em buffer a próxima leva de amostras, deixando-as prontas para a GPU.
Caso de Estudo: Visão Computacional com Arquivos Pequenos
Para entender melhor como diferentes padrões de acesso afetam a performance, considere dois cenários em uma tarefa de visão computacional onde o dataset consiste em muitos arquivos de imagem relativamente pequenos (aproximadamente 100 KB cada).
Cenário 1 – Acesso Aleatório: O dataset é armazenado como está na classe de armazenamento S3 Standard, e o script de treinamento recupera cada imagem sob demanda. Isso cria um padrão de acesso aleatório, onde cada amostra de treinamento requer sua própria requisição S3 GET. Com latência TTFB na ordem de dezenas de milissegundos e tempo de download mínimo para arquivos pequenos, a performance do dataloader fica limitada por latência. Os threads do cliente gastam a maior parte do tempo ociosos aguardando a chegada dos dados.
Cenário 2 – Acesso Sequencial: O dataset é consolidado em shards de arquivo maiores (por exemplo, ~100 MB cada) antes de ser armazenado no S3. Agora o dataloader lê múltiplas amostras de treinamento sequencialmente com uma única requisição S3 GET. Isso muda a carga de trabalho para ser limitada por largura de banda, removendo o impacto TTFB por amostra e possibilitando streaming eficiente de amostras consecutivas durante a fase de download.
Técnicas Práticas de Otimização
Utilizar Clientes de Alto Desempenho Otimizados para S3
Escolher um cliente S3 performático pode ser desafiador dada a abundância de opções disponíveis. Para enfrentar isso, a AWS introduziu em 2023 dois clientes nativos de código aberto para S3: Mountpoint para Amazon S3 e Amazon S3 Connector para PyTorch. Ambos são construídos sobre o AWS Common Runtime (CRT), uma coleção de primitivas otimizadas em C que incluem um cliente S3 nativo implementando otimizações de performance baseadas em boas práticas, como paralelização de requisições, timeouts, retentativas e reutilização de conexões.
Mountpoint para Amazon S3 é um cliente de arquivo de código aberto que permite montar um bucket S3 em sua instância de computação e acessá-lo como um sistema de arquivos local sem necessidade de alterações no código existente. Isso o torna adequado para uma ampla gama de cargas de trabalho, incluindo treinamento de ML. Para ambientes Kubernetes, o Mountpoint para Amazon S3 Container Storage Interface (CSI) Driver estende essa capacidade apresentando um bucket S3 como um volume de armazenamento. Com o recente lançamento do Mountpoint para Amazon S3 CSI v2, o driver introduz cache compartilhado entre pods, permitindo que cargas de trabalho distribuídas de ML reutilizem dados localmente armazenados em cache, potencializando performance e eficiência de recursos.
Amazon S3 Connector para PyTorch oferece primitivas nativas do PyTorch que integram estritamente S3 com pipelines de treinamento. A integração possibilita acesso de alta throughput aos dados de treinamento e checkpointing eficiente diretamente ao Amazon S3, aplicando automaticamente otimizações de performance. O conector suporta datasets em estilo mapa para acesso aleatório e datasets em estilo iterável para acesso sequencial de streaming, adequando-se a diversos padrões de treinamento de ML. Inclui também interface de checkpointing integrada para salvar e carregar checkpoints do S3 sem depender de armazenamento local. A instalação é leve (usando pip, por exemplo), e o conector requer apenas mudanças mínimas no código de treinamento, com exemplos disponíveis no GitHub.
Fragmentar Datasets e Usar Padrões Sequenciais
Uma estratégia eficaz para otimizar o carregamento de dados do S3 é serializar datasets em fewer, shards de arquivo maiores, cada um contendo muitas amostras de treinamento, e ler essas amostras sequencialmente usando seu dataloader. Em micro-benchmarks S3, tamanhos de shard entre 100 MB a 1 GB tipicamente entregam excelente throughput. O tamanho ideal pode variar dependendo da carga de trabalho. Shards menores podem melhorar comportamento quasi-aleatório de buffers de pré-carregamento, enquanto shards maiores geralmente oferecem melhor throughput bruto.
Formatos comuns para fragmentação incluem tar (frequentemente usado em PyTorch através de bibliotecas como WebDataset) e TFRecord (usado com tf.data em TensorFlow). Fragmentar dados não garante leituras sequenciais. Se seu dataloader acessar aleatoriamente amostras dentro de um shard—comum com formatos como Parquet ou HDF5—os benefícios do acesso sequencial se perdem. Para completar os ganhos de performance, projete seu dataloader para que amostras sejam lidas em ordem dentro de cada shard.
Paralelização, Pré-carregamento e Cache
Otimizar os estágios de ingestão e pré-processamento de dados de um pipeline de ML é crítico para maximizar throughput de treinamento, especialmente quando padrões de acesso aleatório são inevitáveis.
Paralelização é uma das formas mais eficazes de melhorar throughput em pipelines de carregamento de dados, particularmente porque decodificação e pré-processamento de dados são frequentemente embarrassingly parallel—divisíveis em muitos processos independentes rodando simultaneamente sem necessidade de comunicação. Você pode usar frameworks como TensorFlow (tf.data) e PyTorch (DataLoader nativo) para ajustar o tamanho de seus pools de workers—threads ou processos CPU—para paralelizar ingestão de dados.
Para padrões de acesso sequencial, uma boa regra é corresponder o número de threads worker ao número de núcleos CPU disponíveis. Contudo, em instâncias com alto número de CPUs (por exemplo, mais de 20), usar um pool ligeiramente menor pode melhorar eficiência. Para padrões de acesso aleatório, particularmente ao ler diretamente do S3, tamanhos de pool maiores que o número de CPUs provaram ser benéficos. Por exemplo, em uma instância EC2 com 8 vCPUs, aumentar a configuração de num_workers do PyTorch para 64 ou mais melhorou significativamente throughput de dados.
Aumentar paralelismo não é uma solução universal. Over-paralelization pode sobrecarregar recursos de CPU e memória, deslocando o gargalo de I/O para pré-processamento. É importante fazer benchmark dentro do contexto de sua carga de trabalho específica para encontrar o equilíbrio correto.
Pré-carregamento complementa paralelização desacoplando carregamento de dados da computação de GPU. Usando um padrão produtor-consumidor, pré-carregamento permite que dados sejam preparados assincronamente e armazenados em buffer na memória, deixando o próximo lote pronto quando a GPU o necessite. Buffers de pré-carregamento bem dimensionados e tamanhos de pool worker adequadamente ajustados ajudam a amortizar latência de I/O e pré-processamento, melhorando throughput geral de treinamento.
Cache é particularmente eficaz para cargas de trabalho multi-epoch com padrões de acesso aleatório, onde as mesmas amostras de dados são lidas múltiplas vezes. Ferramentas como Mountpoint para Amazon S3 oferecem mecanismos de cache integrados que armazenam objetos do dataset localmente em armazenamento de instância (por exemplo, discos NVMe), volumes EBS ou memória. Removendo requisições S3 GET repetidas, cache melhora velocidade de treinamento e eficiência de custos.
Como o dataset de entrada típico permanece estático durante treinamento, recomenda-se configurar Mountpoint com indefinite metadata TTL (configurando –metadata-ttl indefinite, veja documentação Mountpoint para S3) para reduzir sobrecarga de requisição S3. Adicionalmente, nos benchmarks, cache de dados para NVMe foi habilitado, permitindo que Mountpoint armazene objetos localmente. O cache gerencia espaço automaticamente evictando os arquivos menos recentemente usados, mantendo pelo menos 5% de espaço disponível por padrão (configurável).
Validação Através de Benchmarks
A AWS conduziu uma série de benchmarks simulando uma carga de trabalho realista de visão computacional sob padrões de acesso aleatório e sequencial. Embora resultados exatos variem conforme seu caso específico, tendências e insights de performance são amplamente aplicáveis a pipelines de treinamento de ML.
Os benchmarks foram executados em uma instância Amazon EC2 g5.8xlarge equipada com GPU NVIDIA A10G e 32 vCPUs. A carga de trabalho usou o backbone google/vit-base-patch16-224-in21k ViT para classificação de imagens, treinando em um dataset de 10 GB contendo 100.000 imagens JPEG sintéticas (~115 KB cada), transmitidas diretamente do S3 Standard sob demanda.
Cada configuração de benchmark comparou diferentes clientes S3: dataloader baseado em fsspec, Mountpoint para Amazon S3 (sem cache de dados), Mountpoint para Amazon S3 (com cache de dados) e S3 Connector para PyTorch. Para benchmark com acesso sequencial, o dataset foi reorganizado em formato tar com tamanhos de shard variando de 4 MB a 256 MB.
Os resultados demonstraram que o S3 Connector para PyTorch alcançou a mais alta throughput de todos os clientes avaliados, atingindo aproximadamente 138 amostras/segundo com utilização próxima à saturação da GPU em acesso aleatório. Em cenários multi-epoch, cache de dados significativamente potencializou performance, com o dataset inteiro servido de disco a partir da segunda epoch, saturando completamente a GPU e maximizando throughput mesmo com pool de workers dataloader menor.
Para reproduzir benchmarks similares em seu próprio ambiente, a AWS fornece uma ferramenta de benchmark dedicada que suporta diversas configurações de carregamento de dados S3. Para resultados consistentes e significativos, use tipos idênticos de instância EC2 para cada cliente S3, coloque cada dataset de teste em buckets S3 separados e execute experimentos na mesma Região AWS que seus buckets.
Conclusão
Otimizar ingestão de dados é crucial para desbloquear completamente a performance de pipelines modernos de treinamento de ML em nuvem. Este artigo demonstrou como padrões de leitura aleatória e pequenos tamanhos de arquivo podem severamente limitar throughput devido a sobrecargas de latência, enquanto datasets consolidados com padrões de acesso sequencial podem maximizar largura de banda e manter GPUs plenamente utilizadas.
A AWS explorou como usar clientes Mountpoint para Amazon S3 e S3 Connector para PyTorch de alto desempenho pode fazer diferença significativa na performance de treinamento. Também demonstrou benefícios de fragmentar datasets em arquivos maiores, ajustar configurações de paralelização e aplicar cache para minimizar requisições S3 redundantes.
À medida que cargas de trabalho de treinamento crescem, revisite continuamente o design do seu pipeline de dados. Decisões cuidadosas sobre carregamento de dados podem entregar ganhos desproporciona is em eficiência de custos e tempo para resultados.
A AWS anunciou recursos avançados de políticas de segurança de rede para o Amazon Elastic Kubernetes Service (EKS), capacitando organizações a fortalecer sua postura de segurança em cargas Kubernetes. Essas melhorias visam tanto o tráfego entre componentes internos do cluster quanto as conexões com ambientes externos.
A expansão das capacidades de segmentação de rede consolida investimentos anteriores da AWS nessa área, oferecendo aos administradores ferramentas mais robustas para controlar e monitorar fluxos de dados em arquiteturas containerizadas cada vez mais complexas.
Isolamento centralizado de tráfego de rede
O isolamento de tráfego de rede tornou-se essencial conforme organizações ampliam seus ambientes de aplicações no EKS. A incapacidade de segmentar corretamente o tráfego aumenta os riscos de acessos não autorizados, tanto dentro quanto fora do cluster.
Agora, as organizações podem ir além: gerenciar centralmente filtros de rede para todo o cluster, oferecendo controle mais granular e uma visão unificada da segurança em toda a infraestrutura Kubernetes.
Políticas baseadas em nomes de domínio (FQDN)
Outro avanço significativo envolve as regras de saída — egress rules — que agora filtram o tráfego destinado a recursos externos com base em nomes de domínio totalmente qualificados (FQDN). Essa abordagem oferece aos administradores de cluster uma estratégia mais estável e previsível para bloquear acessos não autorizados a recursos na nuvem ou em ambientes locais (on-premises).
Em vez de gerenciar manualmente listas de endereços IP (que podem mudar frequentemente), administradores podem definir políticas baseadas em nomes de domínio, simplificando a manutenção e reduzindo erros de configuração.
Disponibilidade e compatibilidade
Esses recursos de segurança estão disponíveis em todas as regiões comerciais da AWS. A ClusterNetworkPolicy funciona em todos os modos de execução de clusters EKS que utilizam a versão 1.21.0 ou superior do VPC CNI.
As políticas baseadas em DNS estão disponíveis especificamente para instâncias EC2 iniciadas via EKS Auto Mode. Novos clusters com Kubernetes versão 1.29 ou posterior já têm acesso a essas capacidades, enquanto suporte para clusters existentes será implementado nas próximas semanas.
A AWS anunciou duas novas tipologias de perguntas para os formulários de avaliação do Amazon Connect. Essas adições permitem aos gestores capturar informações mais profundas sobre o desempenho de agentes humanos e inteligência artificial, expandindo significativamente as possibilidades de análise qualitativa dentro da plataforma.
O que mudou
Perguntas de múltipla escolha
Os gerentes agora conseguem criar perguntas que permitem múltiplas seleções de respostas. Um exemplo prático é registrar quais produtos o cliente demonstrou interesse durante uma conversa de vendas. Ao invés de respostas binárias ou limitadas a uma única opção, essa funcionalidade oferece flexibilidade para capturar contextos mais complexos e realistas de atendimento.
Captura de datas
Além das múltiplas escolhas, a plataforma agora permite registrar datas para ações de clientes e agentes dentro dos formulários de avaliação. Isso abre possibilidades para rastreamento temporal de eventos importantes. Um caso de uso comum é documentar quando um cliente solicitou um empréstimo e quando essa solicitação foi aprovada, criando um registro cronológico completo da jornada do cliente.
Disponibilidade
Este recurso está disponível em todas as regiões onde o Amazon Connect opera. Para aprofundar-se na implementação e configuração dessas novas funcionalidades, você pode consultar a documentação técnica e acessar mais informações na página oficial do serviço.
Impacto para seus formulários de avaliação
Essas novas opções de perguntas enriquecem a qualidade das avaliações de interações de atendimento. Com a possibilidade de registrar múltiplas respostas e datas, os formulários se tornam instrumentos mais robustos para análise de desempenho, permitindo que gestores extraiam insights mais profundos sobre a qualidade do atendimento e o comportamento dos clientes.