A AWS anunciou uma importante expansão do Block Public Access (Bloqueio de Acesso Público) para o Amazon S3. O serviço agora permite gerenciamento centralizado através do AWS Organizations, possibilitando que organizações padronizem e enforcem configurações de acesso público em todos os accounts de sua estrutura por meio de uma única configuração de política.
Como funciona o Block Public Access em nível organizacional
Propagação automática de políticas
O Block Public Access em nível organizacional opera através de uma configuração única que controla todas as definições de acesso público em todos os accounts dentro da organização. Quando você anexa a política no root ou em uma Unidade Organizacional (OU, do inglês Organizational Unit) da sua organização, ela se propaga automaticamente para todos os sub-accounts dentro desse escopo. Contas-membro novas herdam a política de forma automática, eliminando a necessidade de configuração manual individual.
Flexibilidade de aplicação
Além da abordagem centralizada, você também tem a opção de aplicar a política a accounts específicos quando precisa de um controle mais granular. Essa flexibilidade permite que organizações balanceiem a uniformidade de segurança com necessidades específicas de diferentes times ou departamentos.
Como começar
Configuração através do console
Para iniciar, acesse o console do AWS Organizations e utilize o checkbox “Bloquear todo acesso público” ou use o editor JSON para configurações mais avançadas. A interface permite que você customize exatamente quais tipos de acesso público devem ser bloqueados em toda a sua organização.
Monitoramento e auditoria
A AWS CloudTrail pode ser utilizada para auditar e acompanhar a anexação de políticas, bem como monitorar o enforcement da política em todas as contas-membro. Isso oferece visibilidade completa sobre como as configurações de segurança estão sendo aplicadas e mantidas em toda a organização.
Disponibilidade e acesso
Esse recurso está disponível no console do AWS Organizations, bem como através da AWS CLI (Interface de Linha de Comando, do inglês Command Line Interface) e SDKs (Kits de Desenvolvimento de Software, do inglês Software Development Kits), em todas as regiões AWS onde AWS Organizations e Amazon S3 são suportados. Importante destacar que não há custos adicionais para usar esse recurso.
Controle granular sobre o agendamento de cargas de trabalho
A AWS anunciou um novo recurso no Amazon SageMaker HyperPod que oferece suporte a labels (etiquetas) e taints (repugnâncias) personalizados do Kubernetes. Essa funcionalidade permite aos clientes exercer controle preciso sobre o posicionamento de pods e garantir integração tranquila com infraestruturas Kubernetes já existentes.
Para equipes que implantam cargas de trabalho de inteligência artificial em clusters HyperPod orquestrados com EKS (Elastic Kubernetes Service), esse é um recurso particularmente valioso. A capacidade de controlar exatamente onde cada pod é executado ajuda a evitar que recursos caros, como GPUs, sejam consumidos por pods de sistema ou cargas de trabalho não relacionadas a inteligência artificial, enquanto mantém compatibilidade com plugins de dispositivo personalizados, como o EFA (Elastic Fabric Adapter) e operadores NVIDIA GPU.
Eliminando a sobrecarga operacional
O desafio anterior
Antes deste anúncio, clientes precisavam aplicar manualmente labels e taints usando kubectl, tendo que reaplicá-los após cada substituição de nó, operação de escalonamento ou patch do sistema. Esse processo manual gerava sobrecarga operacional significativa e aumentava o risco de inconsistências.
A solução implementada
O novo recurso permite configurar labels e taints no nível do grupo de instâncias através das APIs CreateCluster e UpdateCluster, oferecendo uma abordagem gerenciada para definir e manter políticas de agendamento ao longo de todo o ciclo de vida dos nós.
Capacidades técnicas
Utilizando o novo parâmetro KubernetesConfig, é possível especificar até 50 labels e 50 taints por grupo de instâncias. As labels habilitam organização de recursos e direcionamento de pods através de seletores de nó, enquanto taints repelem pods que não possuem tolerâncias correspondentes, protegendo nós especializados.
Casos de uso práticos
Um exemplo concreto é aplicar taints do tipo NoSchedule em grupos de instâncias com GPUs, garantindo que apenas trabalhos de treinamento de inteligência artificial com tolerâncias explícitas consumam esses recursos de alto custo. Outra aplicação é adicionar labels personalizados que permitam aos pods de plugins de dispositivo agendar corretamente no ambiente.
Operação simplificada
O HyperPod aplica automaticamente essas configurações durante a criação de nós e as mantém durante substituição, escalonamento e operações de patch. Isso elimina a necessidade de intervenção manual e reduz significativamente a sobrecarga operacional que as equipes enfrentavam anteriormente.
O recurso está disponível em todas as regiões da AWS onde o Amazon SageMaker HyperPod é oferecido. Para aprofundar seus conhecimentos sobre labels e taints personalizados, consulte a documentação técnica completa.
A AWS apresentou um conjunto de diretrizes destinadas às varreduras de rede realizadas em ambientes de clientes. O objetivo? Permitir que ferramentas conformes coletem dados mais precisos, reduzam relatos de abuso e contribuam para elevar o nível de segurança na internet como um todo.
Varreduras de rede são práticas comuns em infraestruturas modernas de TI. No entanto, essa prática enfrenta um dilema fundamental: ela pode servir tanto a propósitos legítimos quanto a atividades maliciosas. Do lado legítimo, equipes de segurança, administradores de sistemas e pesquisadores autorizados utilizam varreduras para manter inventários precisos de ativos, validar configurações de segurança e identificar vulnerabilidades ou versões desatualizadas de software que demandam atenção imediata.
Já do lado malicioso, atores de ameaça realizam varreduras para enumerar sistemas, descobrir fraquezas e coletar inteligência para futuros ataques. Distinguir entre essas duas situações é um desafio constante para operações de segurança.
Por Que Essas Diretrizes Importam
O Crescimento Exponencial de Vulnerabilidades
O cenário atual apresenta pressões significativas. De acordo com o banco de dados de vulnerabilidades da NIST (Banco Nacional de Dados de Vulnerabilidades), o número de vulnerabilidades conhecidas cresce a uma taxa de 21% ao ano nos últimos dez anos. Quando uma vulnerabilidade é descoberta por meio de varredura, a intenção do scanner torna-se crítica. Se um ator de ameaça explorar essa vulnerabilidade antes que seja corrigida, ele poderá obter acesso não autorizado aos sistemas organizacionais.
As organizações precisam gerenciar efetivamente suas vulnerabilidades de software para se protegerem contra ransomware, roubo de dados, problemas operacionais e penalidades regulatórias. Porém, isso só é possível quando os dados de segurança coletados por varreduras permanecem protegidos.
Os Múltiplos Interessados nos Dados de Segurança
Diferentes grupos possuem interesses legítimos mas distintos em relação aos dados de segurança coletados:
Organizações querem entender seus ativos e corrigir vulnerabilidades rapidamente para proteger sua infraestrutura
Auditores de compliance buscam evidências de controles robustos na gestão de infraestrutura
Provedores de seguros cibernéticos precisam avaliar o risco da postura de segurança organizacional
Investidores em avaliação de diligência querem compreender o perfil de risco cibernético de uma organização
Pesquisadores de segurança desejam identificar riscos e notificar organizações para que ajam
Atores de ameaça buscam explorar vulnerabilidades não corrigidas e fraquezas para obter acesso não autorizado
Esse ecossistema complexo de interesses concorrentes exige que dados sensíveis de segurança sejam mantidos com níveis diferentes de acesso. Se esses dados caírem nas mãos erradas, as consequências podem ser severas: comprometimento de sistemas, ransomware, negação de serviço e custos significativos para os proprietários dos sistemas.
Considerando o crescimento exponencial de data centers e cargas de trabalho de software conectadas que fornecem serviços críticos em setores como energia, manufatura, saúde, governo, educação, finanças e transportes, o impacto de dados de segurança em mãos erradas pode ter consequências significativas no mundo real.
A Falta de um Padrão Unificado
Atualmente, não existe um padrão único para identificação de scanners de rede na internet. Proprietários de sistemas geralmente não sabem quem está realizando varreduras em suas infraestruturas. Cada proprietário é independentemente responsável por gerenciar a identificação dessas diferentes partes. Scanners podem usar métodos variados para se identificar — como busca reversa de DNS, agentes de usuário personalizados ou faixas de rede dedicadas. Já atores maliciosos podem tentar evitar identificação completamente.
Esse grau de variação na identidade torna extremamente difícil para os proprietários de sistemas compreender a motivação por trás das varreduras que recebem. É nesse contexto que a AWS apresenta suas diretrizes comportamentais para varreduras de rede, buscando proteger redes e clientes.
Os Benefícios das Diretrizes
Quando scanners em conformidade com essas diretrizes realizam varreduras, eles coletam dados mais confiáveis da infraestrutura AWS. Organizações que executam workloads na AWS recebem um maior grau de confiança em sua gestão de riscos. Quando a varredura segue essas diretrizes, proprietários de sistemas conseguem fortalecer suas defesas e melhorar visibilidade em todo seu ecossistema digital.
Ferramentas como o Amazon Inspector podem detectar vulnerabilidades de software e priorizar esforços de correção enquanto aderem a essas diretrizes. Parceiros do AWS Marketplace utilizam essas orientações para coletar sinais de segurança em toda a internet e ajudar organizações a compreender e gerenciar riscos cibernéticos. Como afirmou um especialista do Bitsight: “Quando organizações têm visibilidade clara orientada por dados sobre sua própria postura de segurança e a de terceiros, conseguem tomar decisões mais rápidas e inteligentes para reduzir riscos cibernéticos em todo o ecossistema.”
Reportando Atividades Abusivas
A segurança funciona melhor quando há colaboração. Clientes da AWS podem reportar varreduras abusivas através do Centro de Confiança e Segurança, selecionando o tipo de relatório como “Atividade de Rede > Varredura de Portas e Tentativas de Intrusão”. Cada relatório contribui para melhorar a proteção coletiva contra o uso malicioso de dados de segurança.
As Diretrizes de Conformidade
Para permitir que scanners legítimos se diferenciem claramente de atores de ameaça, a AWS oferece as seguintes orientações para varredura de workloads. Essas diretrizes complementam as políticas existentes sobre testes de penetração e relatório de vulnerabilidades. A AWS se reserva o direito de limitar ou bloquear tráfego que pareça não estar em conformidade com essas diretrizes.
1. Observacional
Um scanner em conformidade não realiza ações que tentem criar, modificar ou deletar recursos ou dados nos endpoints descobertos. Respeita a integridade dos sistemas-alvo. As varreduras não causam degradação na funcionalidade do sistema e não introduzem mudanças nas configurações.
Exemplos de varredura não-modificadora incluem:
Iniciar e completar um handshake TCP
Recuperar o banner de um serviço SSH
2. Identificável
Um scanner em conformidade oferece transparência ao publicar as fontes de sua atividade de varredura. Implementa um processo verificável para confirmar a autenticidade de atividades de varredura.
Exemplos de varredura identificável incluem:
Suportar buscas reversa de DNS para uma das zonas de DNS públicas de sua organização nos IPs de varredura
Publicar intervalos de IP de varredura, organizados por tipos de requisições (como verificação de existência de serviços, verificações de vulnerabilidades)
Se realizar varreduras HTTP, incluir conteúdo significativo em strings de agente de usuário (como nomes de suas zonas de DNS públicas, URL para opt-out)
3. Cooperativo
Um scanner em conformidade limita taxas de varredura para minimizar impacto nos sistemas-alvo. Oferece um mecanismo de opt-out para proprietários de recursos verificados que desejam solicitar cessação da atividade de varredura. Honra solicitações de opt-out dentro de um período de resposta razoável.
Exemplos de varredura cooperativa incluem:
Limitar varredura a uma transação de serviço por segundo por serviço de destino
Respeitar configurações de site conforme expressos em robots.txt, security.txt e outros padrões da indústria para expressar intenção do proprietário do site
4. Confidencial
Um scanner em conformidade mantém práticas seguras de infraestrutura e manipulação de dados, refletidas em certificações de padrão industrial como SOC2. Garante nenhum acesso não autenticado ou não autorizado aos dados coletados. Implementa processos de identificação e verificação de usuários.
O Caminho Adiante
À medida que mais scanners de rede adotam essas diretrizes, proprietários de sistemas se beneficiarão de riscos reduzidos em relação a confidencialidade, integridade e disponibilidade. Scanners legítimos enviarão um sinal claro de sua intenção e melhorarão a qualidade de visibilidade que conseguem obter. Com o estado em constante mudança do networking, espera-se que essas diretrizes evoluam acompanhando controles técnicos ao longo do tempo.
Os modelos de IA generativa continuam crescendo em escala e capacidade, intensificando a necessidade de inferência mais veloz e eficiente. Aplicações que funcionam com estes modelos precisam de baixa latência e desempenho consistente sem comprometer a qualidade dos resultados gerados. A AWS anunciou novos aprimoramentos em seu kit de ferramentas de otimização de inferência no SageMaker AI, expandindo o suporte para a decodificação especulativa baseada em EAGLE para mais arquiteturas de modelos.
Essas atualizações facilitam a aceleração do processo de decodificação, permitem otimizar o desempenho utilizando dados específicos da sua aplicação e possibilitam o deploy de modelos com maior throughput por meio do fluxo de trabalho familiar do SageMaker AI.
Entendendo o EAGLE
EAGLE é uma sigla para Algoritmo de Extrapolação para Maior Eficiência em Modelos de Linguagem (Extrapolation Algorithm for Greater Language-model Efficiency). A técnica funciona acelerando a decodificação de modelos de linguagem grandes ao prever tokens futuros diretamente a partir das camadas ocultas do modelo.
Uma das características principais é a capacidade de otimização dinâmica baseada em seus dados. Quando você orienta a otimização usando dados reais da sua aplicação, as melhorias se alinham com os padrões e domínios específicos que você atende, produzindo uma inferência mais rápida que reflete suas cargas de trabalho reais e não apenas benchmarks genéricos.
Dependendo da arquitetura do modelo, o SageMaker AI treina cabeçalhos EAGLE 3 ou EAGLE 2. É importante notar que esse treinamento e otimização não se limita a uma única operação. Você pode começar utilizando os conjuntos de dados fornecidos pelo SageMaker para treinamento inicial, mas conforme coleta e reúne seus próprios dados, pode também fazer ajuste fino usando seu próprio conjunto de dados curado para desempenho altamente adaptativo e específico à sua carga de trabalho.
Um exemplo prático seria usar uma ferramenta como Captura de Dados para curar seu próprio conjunto de dados ao longo do tempo a partir de requisições em tempo real que atingem seu modelo hospedado. Trata-se de um recurso iterativo com múltiplos ciclos de treinamento para melhorar continuamente o desempenho.
O SageMaker AI agora oferece suporte nativo para decodificação especulativa com EAGLE 2 e EAGLE 3, permitindo que cada arquitetura de modelo aplique a técnica que melhor se adequa ao seu design interno.
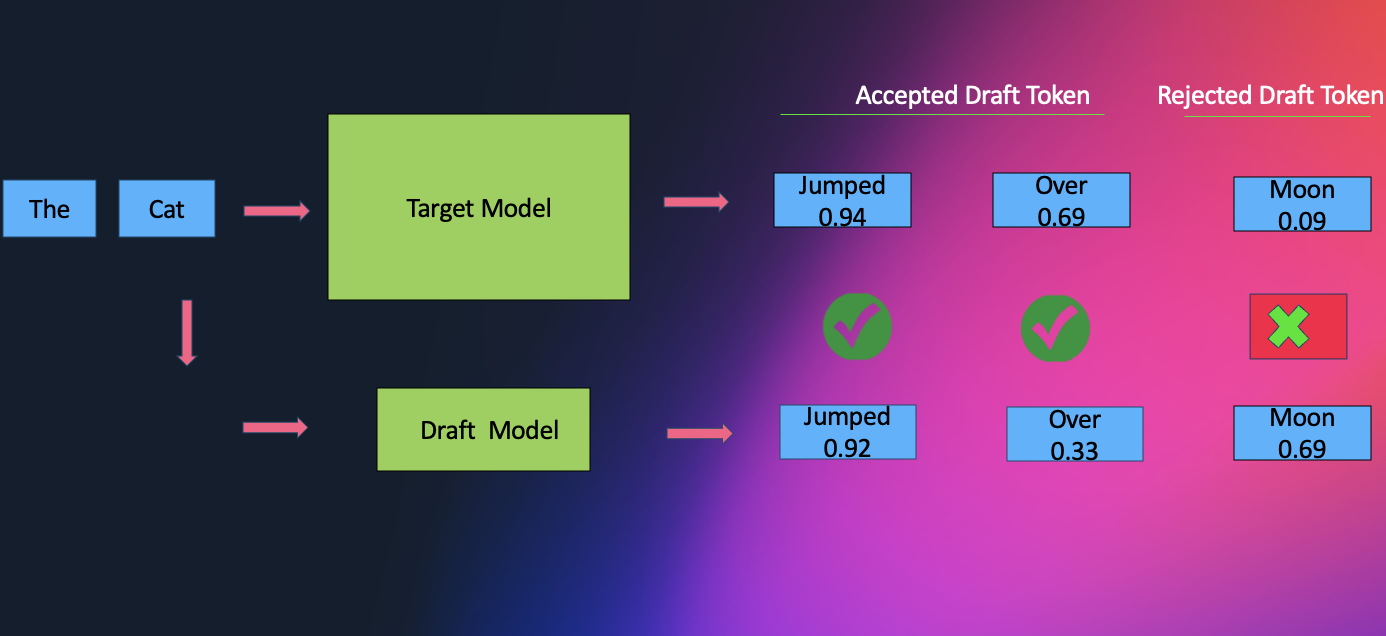
Para seu modelo de base LLM, você pode utilizar modelos do SageMaker JumpStart ou trazer seus próprios artefatos de modelo de outro lugar, como o HuggingFace. A decodificação especulativa é uma técnica amplamente empregada para acelerar inferência em LLMs sem comprometer a qualidade. O método envolve usar um modelo de rascunho menor para gerar tokens preliminares, que são então verificados pelo LLM alvo. A extensão da aceleração obtida por meio da decodificação especulativa depende fortemente da seleção do modelo de rascunho.
A natureza sequencial dos LLMs modernos os torna caros e lentos, e a decodificação especulativa provou ser uma solução eficaz para este problema. Métodos como EAGLE melhoram isso reutilizando recursos do modelo alvo, levando a melhores resultados.
Evolução: Do EAGLE 2 ao EAGLE 3
Uma tendência atual na comunidade de LLM é aumentar dados de treinamento para potencializar a inteligência do modelo sem adicionar custos de inferência. Infelizmente, essa abordagem tem benefícios limitados para EAGLE. Essa limitação ocorre devido às restrições do EAGLE na previsão de recursos.
Para resolver isso, o EAGLE 3 foi introduzido, que prevê tokens diretamente em vez de recursos e combina recursos de múltiplas camadas usando uma técnica chamada teste em tempo de treinamento. Essas mudanças melhoram significativamente o desempenho e permitem que o modelo se beneficie plenamente do aumento de dados de treinamento.
Para dar aos clientes máxima flexibilidade, o SageMaker suporta todos os principais fluxos de trabalho para construir ou refinar um modelo EAGLE:
Treinar um modelo EAGLE completamente do zero usando o conjunto de dados aberto curado pelo SageMaker
Treinar do zero com seus próprios dados para alinhar o comportamento especulativo com seus padrões de tráfego
Começar a partir de um modelo EAGLE base existente, retreinando-o com o conjunto de dados aberto padrão para uma baseline rápida e de alta qualidade
Ou ajustar esse modelo base com seu próprio conjunto de dados para desempenho altamente adaptativo e específico à sua carga de trabalho
Além disso, o SageMaker JumpStart fornece modelos EAGLE completamente pré-treinados, permitindo que você comece a otimização imediatamente sem preparar nenhum artefato.
A solução abrange seis arquiteturas suportadas e inclui uma base EAGLE pré-treinada e pré-armazenada em cache para acelerar experimentação. O SageMaker AI também suporta formatos de dados de treinamento amplamente utilizados, especificamente ShareGPT e chat e completude OpenAI, permitindo que corpora existentes sejam usados diretamente. Os clientes também podem fornecer dados capturados usando seus próprios endpoints do SageMaker AI, desde que os dados estejam nos formatos especificados acima.
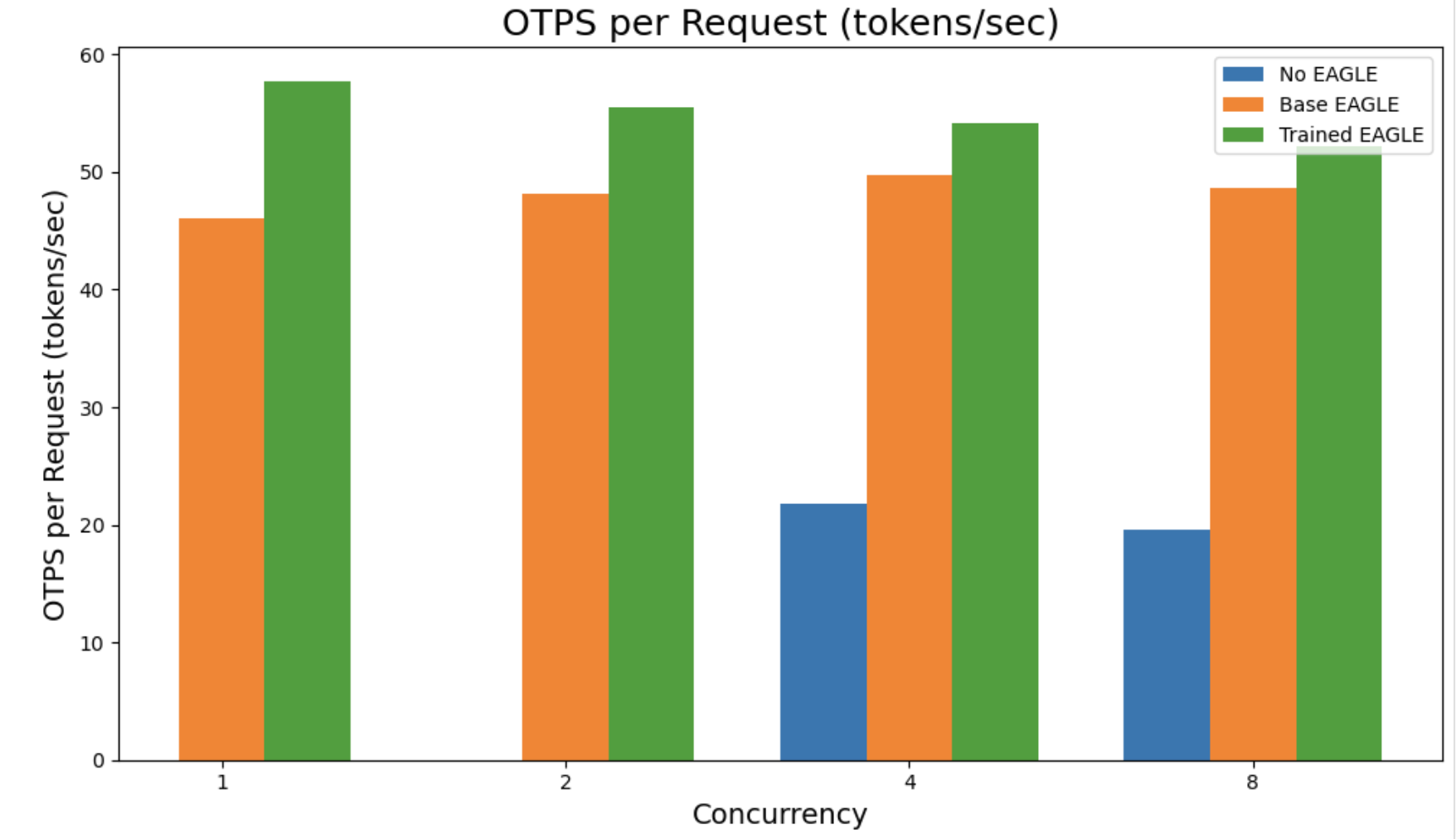
Seja confiando no conjunto de dados aberto do SageMaker ou trazendo seus próprios dados, os trabalhos de otimização normalmente entregam aproximadamente 2.5x de throughput sobre a decodificação padrão, ao mesmo tempo que se adaptam naturalmente às nuances de seu caso de uso específico. Todos os trabalhos de otimização produzem automaticamente resultados de benchmark, dando-lhe visibilidade clara nas melhorias de latência e throughput.
Arquiteturas Suportadas
O SageMaker AI atualmente suporta LlamaForCausalLM, Qwen3ForCausalLM, Qwen3MoeForCausalLM, Qwen2ForCausalLM e GptOssForCausalLM com EAGLE 3, e Qwen3NextForCausalLM com EAGLE 2. Você pode utilizar um pipeline de otimização único em um conjunto de arquiteturas diferentes enquanto ainda obtém os benefícios do comportamento específico de cada modelo.
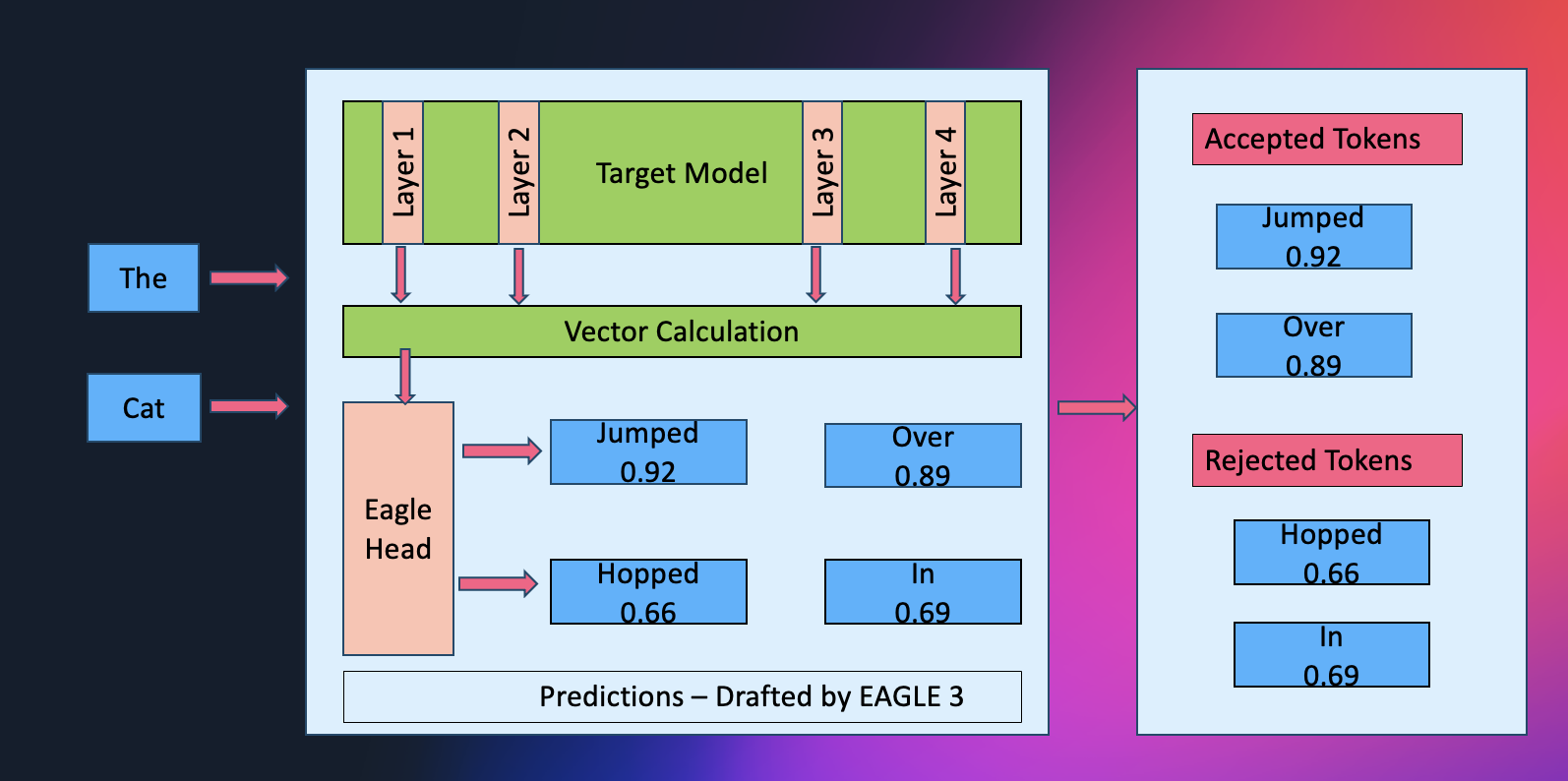
Como o EAGLE Funciona Internamente
A decodificação especulativa pode ser pensada como um cientista chefe experiente guiando o fluxo de descoberta. Em configurações tradicionais, um modelo “assistente” menor funciona antecipadamente, esboçando rapidamente várias continuações de tokens possíveis, enquanto o modelo maior examina e corrige essas sugestões. Essa combinação reduz o número de passos lentos e sequenciais verificando múltiplos rascunhos de uma vez.
O EAGLE simplifica ainda mais esse processo. Em vez de depender de um assistente externo, o modelo efetivamente se torna seu próprio parceiro de laboratório: inspeciona suas representações de camadas ocultas internas para antecipar vários tokens futuros em paralelo. Como essas previsões surgem da estrutura aprendida do próprio modelo, tendem a ser mais precisas desde o início, levando a etapas especulativas mais profundas, menos rejeições e throughput mais suave.
Ao remover a sobrecarga de coordenação de um modelo secundário e permitir verificação altamente paralela, essa abordagem alivia gargalos de largura de banda de memória e entrega acelerações notáveis, frequentemente em torno de 2.5x, mantendo a mesma qualidade de saída que o modelo de base produziria.
Executando Trabalhos de Otimização
Você pode interagir com o kit de ferramentas de otimização usando o AWS Python Boto3 SDK, Studio UI ou AWS CLI. As chamadas de API principais para criação de endpoint permanecem as mesmas: create_model, create_endpoint_config e create_endpoint.
O fluxo de trabalho começa com registro de modelo usando a chamada da API create_model. Com essa chamada você pode especificar seu contêiner de serviço e stack. Você não precisa criar um objeto de modelo SageMaker e pode especificar os dados do modelo também na chamada da API do Trabalho de Otimização.
Para otimização de cabeçalhos EAGLE, você especifica os dados do modelo apontando para o parâmetro Fonte de Dados do Modelo. No momento, especificação do ID do Modelo do HuggingFace Hub não é suportada. Extraia seus artefatos e carregue-os em um bucket S3 e especifique-o no parâmetro Fonte de Dados do Modelo.
Por padrão, verificações são realizadas para confirmar que os arquivos apropriados foram carregados, garantindo que você tenha os dados padrão esperados para LLMs:
Usando seus próprios dados de modelo com dataset EAGLE curado
Você pode iniciar um trabalho de otimização com a chamada da API create-optimization-job. Aqui está um exemplo com um modelo Qwen3 32B. Note que você pode trazer seus próprios dados ou também usar os conjuntos de dados fornecidos pelo SageMaker.
Primeiro, crie um objeto de Modelo SageMaker que especifique o bucket S3 com seus artefatos de modelo:
Sua chamada de otimização então extrai esses artefatos de modelo quando você especifica o Modelo SageMaker e um parâmetro TrainingDataSource da seguinte forma:
Para seu próprio EAGLE treinado, você pode especificar outro parâmetro na chamada da API create_model onde aponta para seus artefatos EAGLE. Opcionalmente, você também pode especificar um ID de Modelo SageMaker JumpStart para extrair os artefatos de modelo empacotados:
Usando dados de modelo próprio com conjuntos de dados incorporados
Opcionalmente, você pode utilizar os conjuntos de dados fornecidos pelo SageMaker:
gsm8k_training.jsonl
magicoder.jsonl
opencodeinstruct.jsonl
swebench_oracle_train.jsonl
ultrachat_0_8k_515292.jsonl
Após conclusão, o SageMaker AI armazena métricas de avaliação no S3 e registra a linhagem de otimização no Studio. Você pode fazer deploy do modelo otimizado para um endpoint de inferência com a chamada da API create_endpoint ou na interface.
Resultados de Benchmark
Para benchmarks, foram comparados três estados: sem EAGLE como baseline, EAGLE base usando conjuntos de dados incorporados, e EAGLE treinado usando datasets incorporados e retreinamento com dados customizados próprios.
Os números exibidos abaixo são para Qwen3-32B em métricas como Tempo para Primeiro Token (TTFT) e throughput geral:
Os trabalhos de otimização são executados em instâncias de treinamento do SageMaker AI, e você será cobrado dependendo do tipo de instância e duração do trabalho. O deploy do modelo otimizado resultante usa a precificação padrão de Inferência do SageMaker AI.
Conclusão
A decodificação especulativa adaptativa baseada em EAGLE oferece um caminho mais rápido e eficaz para melhorar o desempenho de inferência de IA generativa no Amazon SageMaker AI. Ao funcionar dentro do modelo em vez de depender de uma rede de rascunho separada, o EAGLE acelera a decodificação, aumenta o throughput e mantém a qualidade da geração. Quando você otimiza usando seu próprio conjunto de dados, as melhorias refletem o comportamento único de suas aplicações, resultando em melhor desempenho de ponta a ponta.
Com suporte a conjuntos de dados incorporados, automação de benchmarks e deployment simplificado, o kit de ferramentas de otimização de inferência ajuda você a entregar aplicações de IA generativa de baixa latência em escala.
Transição do Amazon Lookout for Vision para SageMaker
Em outubro de 2024, a AWS anunciou a descontinuação do Amazon Lookout for Vision, com previsão de encerramento em 31 de outubro de 2025. Como parte de sua estratégia de transição, a empresa recomenda que clientes interessados em soluções de inteligência artificial e aprendizado de máquina para visão computacional utilizem as ferramentas do Amazon SageMaker AI.
A boa notícia é que a AWS disponibilizou no AWS Marketplace os modelos subjacentes que alimentavam o serviço descontinuado. Esses modelos podem ser ajustados usando o Amazon SageMaker para casos de uso específicos, oferecendo flexibilidade total de integração com infraestruturas existentes de hardware e software. Quando executados na nuvem, os custos envolvem apenas a infraestrutura necessária para treinamento ou inferência.
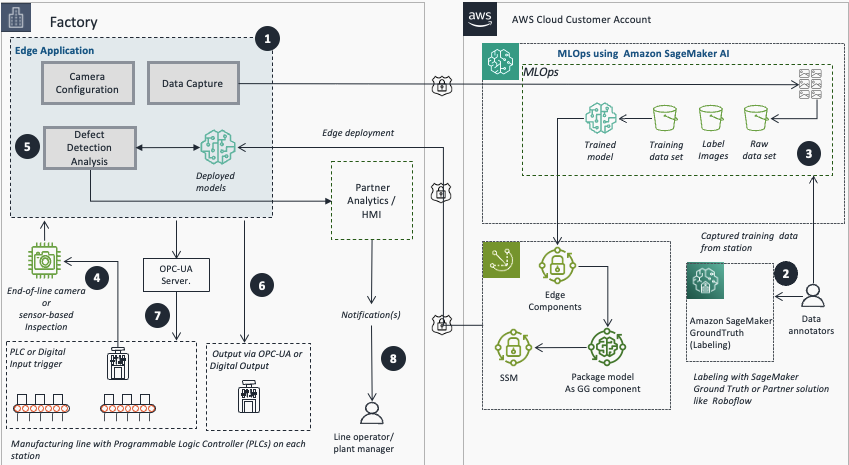
Fluxo end-to-end: da aquisição de imagens até a inferência em dispositivos edge — Fonte: Aws
Vantagens da Migração para SageMaker
A transição proporciona ganhos significativos em flexibilidade e controle. Com o SageMaker, é possível treinar modelos em instâncias maiores para reduzir o tempo de processamento. Além disso, usuários podem ajustar hiperparâmetros que antes não eram disponíveis no console do Lookout for Vision. Por exemplo, é possível desabilitar a cabeça do classificador binário em modelos de segmentação semântica, tornando a solução mais tolerante a variações de iluminação e fundo.
Outro destaque é o controle sobre o tempo máximo de treinamento, que no Lookout for Vision era limitado a 24 horas. Agora, organizações podem customizar esse parâmetro conforme suas necessidades.
Recursos e Modelos Disponíveis
A AWS coloca à disposição dois tipos principais de modelos:
Classificação binária: para categorizar imagens como normais ou anômalas
Segmentação semântica: para identificar regiões específicas com defeitos em uma imagem
Ambos podem ser treinados nas contas próprias da AWS para implantação na nuvem ou em dispositivos edge. O repositório GitHub do Amazon Lookout for Vision foi atualizado com um Jupyter Notebook que facilita o treinamento de datasets com esses dois tipos de modelos e seu empacotamento.
Para rotular dados além do conjunto amostral, é possível usar o Amazon SageMaker Ground Truth para crowdsourcing ou permitir que equipes privadas façam a anotação. Alternativas incluem soluções de parceiros como Edge Impulse, Roboflow e SuperbAI.
Pré-Requisitos
Antes de começar, certifique-se de ter em lugar:
Amazon SageMaker Studio ou Amazon SageMaker Unified Studio para desenvolvimento integrado
Função Controle de Identidade e Acesso (IAM) com permissões apropriadas, incluindo acesso ao Amazon S3, operações no SageMaker e subscrição ao AWS Marketplace
Conhecimento básico de criar instâncias Jupyter no SageMaker e executar notebooks
Configuração do Processo de Etiquetagem
O primeiro passo da jornada envolve preparar os dados para treinamento. A AWS oferece o Ground Truth, que possibilita criar equipes privadas de anotadores e organizar o trabalho de rotulação.
No console do SageMaker AI, navegue até Ground Truth e selecione a opção de criar uma equipe privada. Após definir nome e configurações iniciais, você pode convidar membros da sua equipe por e-mail, enviando automaticamente convites com credenciais de acesso.
Etiquetagem com SageMaker Ground Truth — Fonte: Aws
Preparação e Etiquetagem de Datasets
Uma vez que a equipe está pronta, o próximo passo é preparar o dataset. Faça upload das imagens para um bucket Amazon S3 e organize-as em uma estrutura única de diretório, combinando imagens normais e anômalas.
Para automatizar esse processo, você pode usar um script no AWS CloudShell:
#!/bin/bash
# Clone o repositório
git clone https://github.com/aws-samples/amazon-lookout-for-vision.git
cd amazon-lookout-for-vision/aliens-dataset
# Remove diretório anterior se existir
rm -rf all
# Cria novo diretório
mkdir -p all
# Copia imagens normais
cp normal/*.png all/
# Copia imagens anômalas com sufixo
cd "$(dirname "$0")/amazon-lookout-for-vision/aliens-dataset"
for file in anomaly/*.png; do
if [ -f "$file" ]; then
filename=$(basename "$file")
cp "$file" "all/${filename}.anomaly.png"
fi
done
# Verifica contagem
echo "Imagens normais: $(find normal -name "*.png" | wc -l)"
echo "Imagens anômalas: $(find anomaly -name "*.png" | wc -l)"
echo "Total no diretório all: $(find all -type f | wc -l)"
# Upload para S3
aws s3 cp all/ s3://<BUCKET_NAME>/aliens-dataset-all/ --recursive
# Limpeza
cd ../..
rm -rf amazon-lookout-for-vision
Alternativamente, com a CLI da AWS configurada, você pode usar comandos manuais. Depois de fazer upload, acesse o console do SageMaker, navigate para Ground Truth e crie um novo job de etiquetagem. Configure a localização dos dados no S3, escolha “Configuração Automática de Dados” e selecione “Imagem” como tipo de dados.
Para o tipo de tarefa, escolha “Classificação de Imagem (Rótulo Único)” para classificação binária ou “Segmentação Semântica” conforme sua necessidade. Crie dois rótulos: “normal” e “anomalia”. Uma vez que o job é iniciado, trabalhadores acesso o portal de etiquetagem e rotulam cada imagem conforme as instruções fornecidas.
Treinamento do Modelo
Após concluir a etiquetagem, use os dados rotulados para treinar o modelo de detecção de defeitos. Primeiro, subscrevam-se ao modelo no AWS Marketplace. Copie o ARN (Identificador de Recurso da Amazon) do modelo para referência posterior.
Em seguida, crie uma instância Jupyter do SageMaker. Para essa tarefa, uma instância do tipo m5.2xl é adequada, com volume de 128 GB (o padrão de 5 GB é insuficiente). GPU não é obrigatória na instância do notebook, pois o SageMaker ativa automaticamente instâncias habilitadas com GPU durante o treinamento.
Clone o repositório GitHub dentro da instância Jupyter e localize a pasta relevante. No notebook, defina o ARN do modelo que você subscreveu:
# TODO: altere para usar o algoritmo SageMaker subscrito
algorithm_name = "<Especificar nome do algoritmo após subscrição>"
# Inicializa a sessão SageMaker e obtém a função de execução
sagemaker_session = sagemaker.Session()
region = sagemaker_session.boto_region_name
role = get_execution_role()
# Nome do projeto para identificar no S3
project = "ComputerVisionDefectDetection"
O Futuro da IA em Tempo Real: Comunicação Bidirecional Contínua
Em 2025, a inteligência artificial generativa transcendeu a simples geração de texto. As aplicações modernas demandam muito mais do que respostas transacionais isoladas. Elas exigem capacidades multimodais abrangentes — desde transcrição e tradução de áudio até agentes de voz sofisticados — e, sobretudo, necessitam de comunicação contínua e fluida em tempo real.
O diferencial está em um requisito essencial: os dados precisam fluir simultaneamente em ambas as direções, através de uma única conexão persistente. Imagine um cenário de conversão de fala para texto onde o áudio é transmitido de forma contínua enquanto, ao mesmo tempo, o modelo processa e retorna a transcrição em tempo real, palavra por palavra. Esses casos de uso demandam exatamente essa capacidade bidirecional.
A AWS anunciou a transmissão bidirecional para Amazon SageMaker AI Inference, transformando fundamentalmente o paradigma de inferência — de uma troca transacional isolada para uma conversa contínua e natural. A experiência de fala flui naturalmente quando não há interrupções. Com transmissão bidirecional, a conversão de fala para texto torna-se imediata: o modelo escuta e transcreve simultaneamente, fazendo as palavras aparecerem no exato momento em que são pronunciadas.
Considere o caso prático de um centro de atendimento ao cliente. Conforme o cliente descreve seu problema, a transcrição ao vivo aparece instantaneamente na tela do atendente, fornecendo contexto imediato e permitindo que ele responda sem esperar o cliente terminar de falar. Esse tipo de troca contínua torna as experiências de voz mais fluidas, responsivas e genuinamente humanas.
Como Funciona a Transmissão Bidirecional
O Paradigma Tradicional versus Bidirecional
Na abordagem tradicional de requisições de inferência, existe um padrão bem definido: o cliente envia uma pergunta completa e aguarda, enquanto o modelo processa e retorna uma resposta completa antes que o cliente possa enviar a próxima pergunta. É um ciclo de espera e resposta.
Com transmissão bidirecional, esse fluxo é radicalmente diferente. A pergunta começa a fluir do cliente enquanto o modelo simultaneamente inicia o processamento e começa a retornar a resposta imediatamente. O cliente pode continuar refinando sua entrada enquanto o modelo adapta sua resposta em tempo real. Os resultados aparecem assim que o modelo os gera — palavra por palavra para texto, frame por frame para vídeo, amostra por amostra para áudio.
Esse padrão também oferece benefícios infraestruturais significativos: manter uma única conexão persistente elimina a necessidade de centenas de conexões de curta duração. Isso reduz consideravelmente a sobrecarga de gerenciamento de rede, handshakes TLS e administração de conexões. Além disso, os modelos conseguem manter contexto ao longo de um fluxo contínuo, possibilitando interações multi-turnos sem a necessidade de reenviar o histórico de conversa a cada requisição.
Arquitetura de Três Camadas do SageMaker AI Inference
A implementação técnica da transmissão bidirecional no SageMaker AI Inference combina dois protocolos complementares: HTTP/2 e WebSocket, criando um canal robusto de comunicação bidirecional em tempo real entre cliente e modelo. O fluxo ocorre em três camadas:
Cliente para Roteador SageMaker AI: Sua aplicação se conecta ao endpoint de tempo de execução do Amazon SageMaker AI usando HTTP/2, estabelecendo uma conexão eficiente e multiplexada que suporta transmissão bidirecional.
Roteador para Contêiner do Modelo: O roteador encaminha a requisição para um Sidecar — um proxy leve executando ao lado de seu contêiner de modelo — que estabelece uma conexão WebSocket com o contêiner em ws://localhost:8080/invocations-bidirectional-stream. Uma vez estabelecida, os dados fluem livremente em ambas as direções.
Fluxo de Requisição e Resposta: Sua aplicação envia entrada como uma série de blocos de dados via HTTP/2. A infraestrutura do SageMaker AI converte esses blocos em frames de dados WebSocket — texto (para dados UTF-8) ou binário — e os encaminha ao contêiner. O modelo recebe esses frames em tempo real e começa a processar imediatamente, antes mesmo da chegada da entrada completa. Na direção oposta, o modelo gera saída e a envia como frames WebSocket. O SageMaker AI encapsula cada frame em um payload de resposta e o transmite diretamente à sua aplicação via HTTP/2.
A conexão WebSocket entre o Sidecar e o contêiner permanece aberta pela duração da sessão, com monitoramento de saúde integrado. Para manter a integridade da conexão, o SageMaker AI envia frames de ping a cada 60 segundos para verificar se a conexão está ativa. Seu contêiner responde com pong frames para confirmar que está saudável. Se 5 pings consecutivos não receberem resposta, a conexão é fechada de forma controlada.
Construindo seu Próprio Contêiner com Transmissão Bidirecional
Pré-requisitos e Preparação
Se você deseja utilizar modelos de código aberto ou seus próprios modelos, é possível customizar seu contêiner para suportar transmissão bidirecional. Seu contêiner deve implementar o protocolo WebSocket para lidar com frames de dados recebidos e enviar frames de resposta de volta ao SageMaker AI.
Permissões de IAM que permitam explicitamente a ação sagemaker:InvokeEndpoint* para invocação de endpoints
Docker instalado localmente
Python 3.12 ou superior
Instalar aws-sdk-python para a API InvokeEndpointWithBidirectionalStream do tempo de execução do SageMaker AI
Construindo e Implantando o Contêiner
O processo começa clonando o repositório de demonstração e configurando seu ambiente conforme definido no README.md. Os passos a seguir criarão uma imagem Docker simples de demonstração e a enviarão para seu repositório de ECR na AWS.
# As variáveis de ambiente devem ser definidas para autenticação AWS
# export AWS_ACCESS_KEY_ID="sua-chave-de-acesso"
# export AWS_SECRET_ACCESS_KEY="sua-chave-secreta"
# export AWS_DEFAULT_REGION="us-west-2"
container_name="sagemaker-bidirectional-streaming"
container_tag="latest"
cd container
account=$(aws sts get-caller-identity --query Account --output text)
region=$(aws configure get region)
region=${region:-us-west-2}
container_image_uri="${account}.dkr.ecr.${region}.amazonaws.com/${container_name}:${container_tag}"
# Se o repositório não existe no ECR, crie-o
aws ecr describe-repositories --repository-names "${container_name}" --region "${region}" > /dev/null 2>&1
if [ $? -ne 0 ]
then
aws ecr create-repository --repository-name "${container_name}" --region "${region}" > /dev/null
fi
# Obtenha o comando de login do ECR e execute-o
aws ecr get-login-password --region ${region} | docker login --username AWS --password-stdin ${account}.dkr.ecr.${region}.amazonaws.com/${container_name}
# Construa a imagem Docker localmente e envie-a para o ECR
docker build --platform linux/amd64 --provenance=false -t ${container_name} .
docker tag ${container_name} ${container_image_uri}
docker push ${container_image_uri}
Este processo cria um contêiner com um rótulo Docker indicando ao SageMaker AI que o suporte a transmissão bidirecional está habilitado: com.amazonaws.sagemaker.capabilities.bidirectional-streaming=true.
Após criar a imagem, você pode implantar o contêiner em um endpoint do SageMaker AI através de um script Python que cria o modelo, a configuração do endpoint e finalmente o endpoint propriamente dito.
Invocando o Endpoint com a Nova API
Uma vez que o endpoint do SageMaker AI esteja em estado InService, você pode proceder à invocação do endpoint para testar a funcionalidade de transmissão bidirecional. O cliente Python conecta-se ao endpoint do SageMaker AI e envia dados em chunks, recebendo respostas simultâneas.
#!/usr/bin/env python3
"""
Script Python para Transmissão Bidirecional no SageMaker AI.
Conecta-se a um endpoint do SageMaker AI para comunicação bidirecional.
"""
import argparse
import asyncio
import sys
from aws_sdk_sagemaker_runtime_http2.client import SageMakerRuntimeHTTP2Client
from aws_sdk_sagemaker_runtime_http2.config import Config, HTTPAuthSchemeResolver
from aws_sdk_sagemaker_runtime_http2.models import InvokeEndpointWithBidirectionalStreamInput, RequestStreamEventPayloadPart, RequestPayloadPart
from smithy_aws_core.identity import EnvironmentCredentialsResolver
from smithy_aws_core.auth.sigv4 import SigV4AuthScheme
import logging
def parse_arguments():
"""Analisa argumentos da linha de comando."""
parser = argparse.ArgumentParser(
description="Conecta-se a um endpoint do SageMaker AI para transmissão bidirecional"
)
parser.add_argument(
"ENDPOINT_NAME",
help="Nome do endpoint do SageMaker AI para conectar"
)
return parser.parse_args()
AWS_REGION = "us-west-2"
BIDI_ENDPOINT = f"https://runtime.sagemaker.{AWS_REGION}.amazonaws.com:8443"
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class SimpleClient:
def __init__(self, endpoint_name, region=AWS_REGION):
self.endpoint_name = endpoint_name
self.region = region
self.client = None
self.stream = None
self.response = None
self.is_active = False
def _initialize_client(self):
config = Config(
endpoint_uri=BIDI_ENDPOINT,
region=self.region,
aws_credentials_identity_resolver=EnvironmentCredentialsResolver(),
auth_scheme_resolver=HTTPAuthSchemeResolver(),
auth_schemes={"aws.auth#sigv4": SigV4AuthScheme(service="sagemaker")}
)
self.client = SageMakerRuntimeHTTP2Client(config=config)
async def start_session(self):
if not self.client:
self._initialize_client()
logger.info(f"Iniciando sessão com endpoint: {self.endpoint_name}")
self.stream = await self.client.invoke_endpoint_with_bidirectional_stream(
InvokeEndpointWithBidirectionalStreamInput(endpoint_name=self.endpoint_name)
)
self.is_active = True
self.response = asyncio.create_task(self._process_responses())
async def send_words(self, words):
for i, word in enumerate(words):
logger.info(f"Enviando payload: {word}")
await self.send_event(word.encode('utf-8'))
await asyncio.sleep(1)
async def send_event(self, data_bytes):
payload = RequestPayloadPart(bytes_=data_bytes)
event = RequestStreamEventPayloadPart(value=payload)
await self.stream.input_stream.send(event)
async def end_session(self):
if not self.is_active:
return
await self.stream.input_stream.close()
logger.info("Stream fechado")
async def _process_responses(self):
try:
output = await self.stream.await_output()
output_stream = output[1]
while self.is_active:
result = await output_stream.receive()
if result is None:
logger.info("Sem mais respostas")
break
if result.value and result.value.bytes_:
response_data = result.value.bytes_.decode('utf-8')
logger.info(f"Recebido: {response_data}")
except Exception as e:
logger.error(f"Erro ao processar respostas: {e}")
def main():
"""Função principal para analisar argumentos e executar o cliente de streaming."""
args = parse_arguments()
print("=" * 60)
print("Cliente de Transmissão Bidirecional SageMaker AI")
print("=" * 60)
print(f"Nome do Endpoint: {args.ENDPOINT_NAME}")
print(f"Região AWS: {AWS_REGION}")
print("=" * 60)
async def run_client():
sagemaker_client = SimpleClient(endpoint_name=args.ENDPOINT_NAME)
try:
await sagemaker_client.start_session()
words = ["Preciso de ajuda com", "meu saldo da conta", "Posso ajudar com isso", "e cobranças recentes"]
await sagemaker_client.send_words(words)
await asyncio.sleep(2)
await sagemaker_client.end_session()
sagemaker_client.is_active = False
if sagemaker_client.response and not sagemaker_client.response.done():
sagemaker_client.response.cancel()
logger.info("Sessão encerrada com sucesso")
return 0
except Exception as e:
logger.error(f"Erro no cliente: {e}")
return 1
try:
exit_code = asyncio.run(run_client())
sys.exit(exit_code)
except KeyboardInterrupt:
logger.info("Interrompido pelo usuário")
sys.exit(1)
except Exception as e:
logger.error(f"Erro inesperado: {e}")
sys.exit(1)
if __name__ == "__main__":
main()
A AWS e a Deepgram colaboraram para construir suporte de transmissão bidirecional especificamente para endpoints do SageMaker AI. A Deepgram, parceira de Tier Avançado da AWS, oferece modelos de IA de voz em nível empresarial com precisão e velocidade líderes do setor. Seus modelos alimentam aplicações de transcrição em tempo real, conversão de texto para fala e agentes de voz para contact centers, plataformas de mídia e aplicações de IA conversacional.
Para clientes com requisitos rigorosos de conformidade que exigem que o processamento de áudio nunca saia de sua Nuvem Privada Virtual (VPC) na AWS, as opções tradicionais auto-hospedadas demandavam sobrecarga operacional considerável para configuração e manutenção. A transmissão bidirecional do Amazon SageMaker transforma completamente essa experiência, permitindo que os clientes implantem e escalem aplicações de IA em tempo real com apenas alguns poucos cliques no Console de Gerenciamento da AWS.
O modelo de fala para texto Deepgram Nova-3 está disponível atualmente no AWS Marketplace para implantação como um endpoint do SageMaker AI, com modelos adicionais chegando em breve. As capacidades incluem transcrição multilíngue, desempenho em escala empresarial e reconhecimento específico de domínio. A Deepgram oferece um período de avaliação gratuita de 14 dias no Amazon SageMaker AI para desenvolvedores prototiparem aplicações sem incorrer em custos de licença de software. As cobranças de infraestrutura do tipo de máquina escolhido ainda serão incorridas durante esse período. Para mais detalhes, consulte a documentação de preços do Amazon SageMaker AI.
Configurando um Endpoint Deepgram no SageMaker AI
Para configurar um endpoint Deepgram no SageMaker AI, navegue até a seção de pacotes de modelos do AWS Marketplace dentro do console do Amazon SageMaker AI e procure por Deepgram. Inscreva-se no produto e proceda ao assistente de lançamento na página do produto. Continue fornecendo detalhes no assistente de criação de endpoint de inferência em tempo real do Amazon SageMaker AI. Certifique-se de editar a variante de produção para incluir um tipo de instância válido ao criar sua configuração de endpoint. O botão de edição pode estar oculto até que você role a direita na tabela de variantes de produção. O ml.g6.2xlarge é um tipo de instância preferido para testes iniciais. Consulte a documentação Deepgram para requisitos específicos de hardware e orientação de seleção. Na página de resumo do endpoint, anote o nome do endpoint que você forneceu, pois será necessário na seção seguinte.
Usando o Endpoint Deepgram no SageMaker AI
Uma aplicação TypeScript de exemplo mostra como transmitir um arquivo de áudio para o modelo Deepgram hospedado em um endpoint de inferência em tempo real do SageMaker AI e imprimir uma transcrição transmitida em tempo real. A função cria um fluxo do arquivo WAV abrindo um arquivo de áudio local e enviando-o para o Amazon SageMaker AI Inference em pequenos blocos binários.
import * as fs from "fs";
import * as path from "path";
import { RequestStreamEvent } from '@aws-sdk/client-sagemaker-runtime-http2';
function sleep(ms: number): Promise {
return new Promise(resolve => setTimeout(resolve, ms));
}
async function* streamWavFile(filePath: string): AsyncIterable {
const full = path.resolve(filePath);
if (!fs.existsSync(full)) {
throw new Error(`Arquivo de áudio não encontrado: ${full}`);
}
console.log(`Transmitindo áudio: ${full}`);
const readStream = fs.createReadStream(full, { highWaterMark: 512_000 }); // 512 KB
for await (const chunk of readStream) {
yield { PayloadPart: { Bytes: chunk, DataType: "BINARY" } };
}
// Mantenha o stream ativo para receber respostas de transcrição após todo arquivo ser enviado
console.log("Áudio enviado, aguardando conclusão da transcrição...");
await sleep(15000); // Aguarde 15 segundos para processamento do bloco final de áudio
// Avise ao contêiner que terminamos
yield { PayloadPart: { Bytes: new TextEncoder().encode('{"type":"CloseStream"}'), DataType: "UTF8" } };
}
O cliente de tempo de execução do AWS SageMaker AI é configurado especificando a região AWS, o nome do endpoint do SageMaker AI e a rota do modelo Deepgram dentro do contêiner. Você precisa atualizar esses valores conforme necessário.
import { SageMakerRuntimeHTTP2Client, InvokeEndpointWithBidirectionalStreamCommand } from '@aws-sdk/client-sagemaker-runtime-http2';
const region = "us-east-1"; // Região AWS
const endpointName = "REPLACEME"; // Nome do seu endpoint Deepgram SageMaker
const audioFile = "test.wav"; // Arquivo de áudio local
const modelInvocationPath = "v1/listen"; // Caminho WebSocket dentro do contêiner do modelo
const modelQueryString = "model=nova-3";
const client = new SageMakerRuntimeHTTP2Client({ region });
O trecho final envia o fluxo de áudio ao endpoint do SageMaker AI e imprime os eventos JSON de transmissão da Deepgram conforme chegam. A aplicação exibe a saída de fala para texto ao vivo sendo gerada.
async function run() {
console.log("Enviando áudio para Deepgram via SageMaker...");
const command = new InvokeEndpointWithBidirectionalStreamCommand({
EndpointName: endpointName,
Body: streamWavFile(audioFile),
ModelInvocationPath: modelInvocationPath,
ModelQueryString: modelQueryString
});
const response = await client.send(command);
if (!response.Body) {
console.log("Nenhuma resposta de streaming recebida.");
return;
}
const decoder = new TextDecoder();
for await (const msg of response.Body) {
if (msg.PayloadPart?.Bytes) {
const text = decoder.decode(msg.PayloadPart.Bytes);
try {
const parsed = JSON.parse(text);
// Extraia e exiba a transcrição
if (parsed.channel?.alternatives?.[0]?.transcript) {
const transcript = parsed.channel.alternatives[0].transcript;
if (transcript.trim()) {
console.log("Transcrição:", transcript);
}
}
console.debug("Deepgram (bruto):", parsed);
} catch {
console.error("Deepgram (erro):", text);
}
}
}
}
console.log("Streaming concluído.");
}
run().catch(console.error);
A transmissão bidirecional no Amazon SageMaker AI Inference representa um avanço significativo na forma como os desenvolvedores podem construir aplicações de IA em tempo real. Ao eliminar as limitações das interações transacionais tradicionais, essa capacidade abre possibilidades para experiências de usuário genuinamente conversacionais e responsivas.
Com suporte para contêineres customizados e integração pronta com modelos parceiros como o Deepgram, a plataforma oferece flexibilidade tanto para quem deseja trazer seus próprios modelos quanto para quem busca soluções prontas para produção. A infraestrutura de três camadas garante eficiência, enquanto o monitoramento automático de conexão assegura confiabilidade.
Developers podem começar a construir aplicações de transmissão bidirecional com Modelos de Linguagem Grande (LLMs) e SageMaker AI hoje mesmo, abrindo novos horizontes para agentes de voz, assistentes conversacionais e qualquer aplicação que se beneficie de comunicação em tempo real verdadeiramente bidirecional.
Novo servidor MCP do SageMaker com suporte a HyperPod
A AWS ampliou as capacidades do servidor MCP (Model Context Protocol) de IA do SageMaker, adicionando ferramentas especializadas para configuração e gerenciamento de clusters HyperPod. Esse avanço permite que assistentes de código alimentados por IA possam provisionar e operar clusters de IA e aprendizado de máquina completos, desde o treinamento inicial até a implantação de modelos em produção.
O que é SageMaker HyperPod e por que importa
O SageMaker HyperPod foi desenvolvido pela AWS para eliminar tarefas repetitivas e de baixo nível no processo de construção de modelos de IA generativa. A solução escala rapidamente tarefas como treinamento, ajuste fino e implantação de modelos em grupos de aceleradores de IA. Com a integração ao servidor MCP de IA, agora é possível que assistentes de código configurem e gerenciem essa infraestrutura complexa de forma intuitiva.
Como funcionam os servidores MCP na AWS
Os servidores MCP no ecossistema da AWS oferecem uma interface padronizada que amplifica a capacidade de desenvolvimento assistido por IA. Equipam os assistentes de código com compreensão em tempo real e contextualizada de diferentes serviços AWS, integrando-se perfeitamente ao fluxo de trabalho dos desenvolvedores.
Capacidades do novo servidor MCP de IA do SageMaker
Configuração simplificada de clusters
O servidor MCP do SageMaker oferece ferramentas que simplificam o ciclo de vida completo das operações de cluster de IA/ML. Os agentes de IA conseguem configurar clusters HyperPod orquestrados tanto pelo Amazon EKS (Elastic Kubernetes Service) quanto pelo Slurm, com todos os pré-requisitos inclusos. A solução usa modelos CloudFormation que otimizam automaticamente rede, armazenamento e recursos de computação, garantindo que os clusters estejam prontos para cargas de trabalho de treinamento distribuído de alta performance.
Gerenciamento e operações contínuas
Além da configuração inicial, o servidor oferece ferramentas abrangentes para administração de clusters e nós, incluindo operações de dimensionamento, aplicação de patches de software e manutenção diversa. Quando integrado ao API MCP Server da AWS, ao Knowledge MCP Server e ao Amazon EKS MCP Server, você ganha cobertura completa de todas as APIs do SageMaker HyperPod, permitindo diagnóstico eficaz de problemas comuns—como identificar por que um nó se tornou inacessível.
Benefícios para diferentes perfis
Administradores de cluster
Para equipes de administração, as ferramentas simplificam operações diárias, reduzindo overhead manual e facilitando a manutenção de infraestrutura em larga escala.
Cientistas de dados
Para profissionais de ciência de dados, a solução permite configurar e escalar clusters de IA/ML sem necessidade de expertise profunda em infraestrutura, liberando tempo para focar no que realmente importa: treinar e implantar modelos eficientes.
Disponibilidade e próximos passos
O gerenciamento de clusters de IA/ML através do servidor MCP do SageMaker está disponível em todas as regiões onde o SageMaker HyperPod opera. Para começar, consulte a documentação do servidor MCP do SageMaker.
Busca Agentica: Uma Nova Forma de Interagir com Dados
A AWS anunciou o lançamento do recurso Agentic Search no Amazon OpenSearch Service, revolucionando a maneira como os usuários buscam e interagem com seus dados. Esse novo sistema utiliza agentes inteligentes orientados por linguagem natural, eliminando a necessidade de conhecer a sintaxe complexa de consultas tradicionais.
Como Funciona o Agentic Search
O Agentic Search introduz um sistema de busca orientado por agentes que compreende a intenção do usuário, orquestra o conjunto adequado de ferramentas, gera consultas em DSL (Linguagem de Domínio Específico) do OpenSearch e fornece resumos transparentes do seu processo de tomada de decisão através de cláusulas simples e consultas em linguagem natural.
Ao automatizar o planejamento e a execução de consultas do OpenSearch, o recurso dispensa a necessidade de sintaxe de busca complexa. Usuários podem fazer perguntas simples como “Encontre carros vermelhos por menos de 30 mil reais” ou “Mostre tendências de vendas do último trimestre”. O agente interpreta a intenção, aplica as estratégias de busca mais adequadas e entrega os resultados enquanto explica seu raciocínio.
Tipos de Agentes Disponíveis
Agentes Conversacionais
Esses agentes lidam com interações complexas e possuem a capacidade de armazenar conversas em memória, permitindo contexto contínuo entre múltiplas consultas.
Agentes de Fluxo
Projetados para processamento eficiente de consultas, os agentes de fluxo oferecem respostas rápidas e diretas.
Tecnologia e Acessibilidade
O QueryPlanningTool integrado utiliza modelos de linguagem grandes (LLMs) para criar consultas em DSL, tornando a busca acessível independentemente do nível de expertise técnica do usuário. As buscas agênticas podem ser gerenciadas através de APIs ou do OpenSearch Dashboards, permitindo configuração e modificação dos agentes conforme necessário.
As configurações avançadas do Agentic Search permitem conexão com servidores MCP externos e o uso de modelos de busca personalizados, oferecendo flexibilidade para casos de uso mais sofisticados.
Disponibilidade e Recursos
O suporte para Agentic Search está disponível para OpenSearch Service versão 3.3 e posteriores em todas as regiões comerciais da AWS e na AWS GovCloud (US) onde o OpenSearch Service opera. Para uma listagem completa das regiões, consulte a documentação de infraestrutura global.
Usuários podem construir agentes e executar buscas agênticas utilizando o novo caso de uso de Agentic Search disponível no plugin AI Search Flows. Para aprender mais sobre o Agentic Search, consulte a documentação técnica do OpenSearch.
Transcrição de fala em tempo real: o desafio dos agentes de voz
À medida que empresas expandem o desenvolvimento de agentes de voz com inteligência artificial, surge um desafio crítico: oferecer transcrição de fala em tempo real com o menor atraso possível. O intervalo entre o usuário falar e o agente responder é fundamental para criar experiências naturais e intuitivas. Historicamente, equipes de engenharia precisavam construir soluções customizadas para gerenciar este processamento contínuo, investindo semanas em desenvolvimento e manutenção de infraestrutura específica para protocolos de streaming — tempo que poderia ser dedicado à melhoria da precisão dos modelos.
A solução: streaming bidirecional no SageMaker AI Inference
A AWS introduziu suporte a streaming bidirecional no Amazon SageMaker AI Inference, transformando a forma como modelos de fala são implantados em produção. Esse recurso permite que modelos de transcrição de fala recebam fluxos de áudio contínuos e retornem transcrições parciais simultaneamente enquanto o usuário está falando — eliminando a necessidade de entrada em lotes e processamento aguardando o término da fala.
Como funciona a implementação
O modelo operacional é elegante em sua simplicidade. Cientistas de dados e engenheiros de machine learning podem implantar modelos de fala-para-texto invocando o endpoint através da nova API Bidirectional Stream. O cliente abre uma conexão HTTP/2 com o runtime do SageMaker AI, que automaticamente cria uma conexão WebSocket para o container. Este container processa quadros de áudio em streaming e retorna transcrições parciais conforme são geradas.
O design é agnóstico ao modelo: qualquer container que implemente um handler WebSocket seguindo o contrato do SageMaker AI funciona automaticamente. Modelos de speech em tempo real como o Deepgram funcionam sem necessidade de modificações, demonstrando a flexibilidade da abordagem.
Impacto prático: eliminando meses de desenvolvimento
Essa implementação elimina meses de desenvolvimento de infraestrutura customizada. Equipes que gastavam semanas mantendo protocolos de WebSocket, gerenciando conexões e otimizando latência agora podem concentrar seus esforços onde realmente importa: melhorando a precisão do modelo, refinando as capacidades do agente e criando experiências de usuário superiores.
Disponibilidade global
O recurso de streaming bidirecional está disponível em mais de 30 regiões AWS distribuídas globalmente, incluindo Canada (Central), South America (São Paulo), Africa (Cape Town), Europe (Paris), Asia Pacific (Hyderabad), Asia Pacific (Jakarta), Israel (Tel Aviv), Europe (Zurich), Asia Pacific (Tokyo), AWS GovCloud US (West), AWS GovCloud US (East), Asia Pacific (Mumbai), Middle East (Bahrain), US West (Oregon), China (Ningxia), US West (Northern California), Asia Pacific (Sydney), Europe (London), Asia Pacific (Seoul), US East (N. Virginia), Asia Pacific (Hong Kong), US East (Ohio), China (Beijing), Europe (Stockholm), Europe (Ireland), Middle East (UAE), Asia Pacific (Osaka), Asia Pacific (Melbourne), Europe (Spain), Europe (Frankfurt), Europe (Milan) e Asia Pacific (Singapore).
A AWS anunciou o lançamento do Network Firewall Proxy em prévia pública, um novo recurso que reforça significativamente a postura defensiva das organizações contra ameaças de exfiltração de dados e injeção de malware. O serviço foi projetado para funcionar em modo explícito, permitindo que seja configurado em apenas alguns cliques.
O destaque principal do Network Firewall Proxy é sua capacidade de gerenciar e proteger o tráfego de dados que sai das aplicações, bem como as respostas que essas aplicações recebem. Isso oferece um controle muito mais preciso sobre as comunicações de rede que atravessam a infraestrutura corporativa.
Capacidades e controles granulares
Proteção contra spoofing e acesso não autorizado
O Network Firewall Proxy da AWS protege as organizações contra tentativas de falsificação de nomes de domínio ou do índice de nome do servidor (SNI — Server Name Index). Além disso, oferece flexibilidade para implementar controles de acesso muito específicos e adaptados às necessidades de cada ambiente.
Um dos casos de uso mais importantes é a restrição de acesso das aplicações apenas para domínios ou endereços IP confiáveis. O recurso também permite bloquear respostas não intencionais provenientes de servidores externos, criando uma barreira efetiva contra comunicações não autorizadas.
Inspeção de TLS e filtragem avançada
O serviço permite ativar a inspeção de TLS (Transport Layer Security) e estabelecer controles granulares de filtragem baseados em atributos de cabeçalho HTTP. Isso significa que é possível examinar e controlar comunicações mesmo quando criptografadas, ampliando as possibilidades de proteção sem sacrificar a privacidade.
Monitoramento e análise detalhada
O Network Firewall Proxy oferece registros abrangentes para monitoramento contínuo das aplicações. Esses logs podem ser direcionados para o Amazon S3 (Simple Storage Service) e o AWS CloudWatch, permitindo análises detalhadas e facilitando processos de auditoria. Essa rastreabilidade é especialmente importante para organizações que precisam atender requisitos regulatórios rigorosos.
Disponibilidade e próximos passos
O Network Firewall Proxy está disponível em prévia pública na região US East (Ohio) e, durante este período, é oferecido gratuitamente. Organizações interessadas são convidadas a testar o recurso em ambientes de teste para avaliar seu impacto nas estratégias de segurança de rede.