Transformando Gerenciamento de Nuvem com Interfaces de Voz
À medida que infraestruturas em nuvem se tornam cada vez mais sofisticadas, a demanda por interfaces de gerenciamento intuitivas e eficientes cresce proporcionalmente. Interfaces de linha de comando (CLI) e consoles web tradicionais, embora poderosos, frequentemente criam barreiras que ralentizam a tomada de decisões e comprometem a eficiência operacional. E se fosse possível conversar diretamente com sua infraestrutura AWS e receber respostas inteligentes de forma imediata?
A AWS apresenta uma abordagem inovadora que combina Amazon Nova Sonic para processamento de voz com Strands Agents para orquestração de múltiplos agentes especializados. Esta solução demonstra como interações naturais por voz podem revolucionar operações em nuvem, tornando serviços AWS mais acessíveis e operações significativamente mais eficientes.
A arquitetura multi-agente apresentada vai além de simples operações AWS, estendendo-se para casos de uso diversos como automação de atendimento ao cliente, gerenciamento de dispositivos de Internet das Coisas (IoT), análise de dados financeiros e orquestração de fluxos de trabalho corporativos. Este padrão fundamental pode ser adaptado para qualquer domínio que exija roteamento inteligente de tarefas e interação baseada em linguagem natural.
Explorando a Arquitetura Técnica
A solução emprega uma arquitetura sofisticada onde Amazon Nova Sonic se integra perfeitamente com Strands Agents, criando um sistema multi-agente que processa comandos de voz e executa operações AWS em tempo real.
Componentes Principais
A arquitetura multi-agente é composta por diversos componentes especializados que trabalham em conjunto:
- Agente Supervisor: Funciona como coordenador central, analisando consultas de voz recebidas e as direcionando para o agente especializado apropriado, com base no contexto e intenção da solicitação
- Agentes Especializados:
- Agente EC2: Responsável por gerenciamento de instâncias, monitoramento de status e operações de computação
- Agente SSM: Gerencia operações do Systems Manager, execução de comandos e gerenciamento de patches
- Agente de Backup: Supervisiona configurações de AWS Backup, monitoramento de trabalhos e operações de restauração
- Camada de Integração de Voz: Utiliza Amazon Nova Sonic para processamento bidirecional de voz, convertendo fala em texto para processamento e texto em fala para respostas
Visão Geral da Solução
O Assistente Nova Voice de Strands Agents demonstra um novo paradigma para gerenciamento de infraestrutura AWS através de inteligência artificial conversacional. Em vez de navegar por consoles complexos ou memorizar comandos CLI, usuários podem simplesmente expressar suas intenções por voz e receber respostas instantâneas. Esta solução coloca a comunicação humana natural no centro das operações técnicas AWS, democratizando o gerenciamento de nuvem para equipes técnicas e não-técnicas.
Stack Tecnológico
A solução utiliza tecnologias modernas e nativas de nuvem para entregar uma interface de voz robusta e escalável:
- Backend: Python 3.12+ com framework Strands Agents para orquestração de agentes
- Frontend: React com AWS Cloudscape Design System para experiência de usuário consistente com padrões AWS
- Modelos de IA: Amazon Bedrock e Claude 3 Haiku para compreensão e geração de linguagem natural
- Processamento de voz: Amazon Nova Sonic para síntese e reconhecimento de fala de alta qualidade
- Comunicação: Servidor WebSocket para comunicação bidirecional em tempo real
Recursos e Capacidades Principais
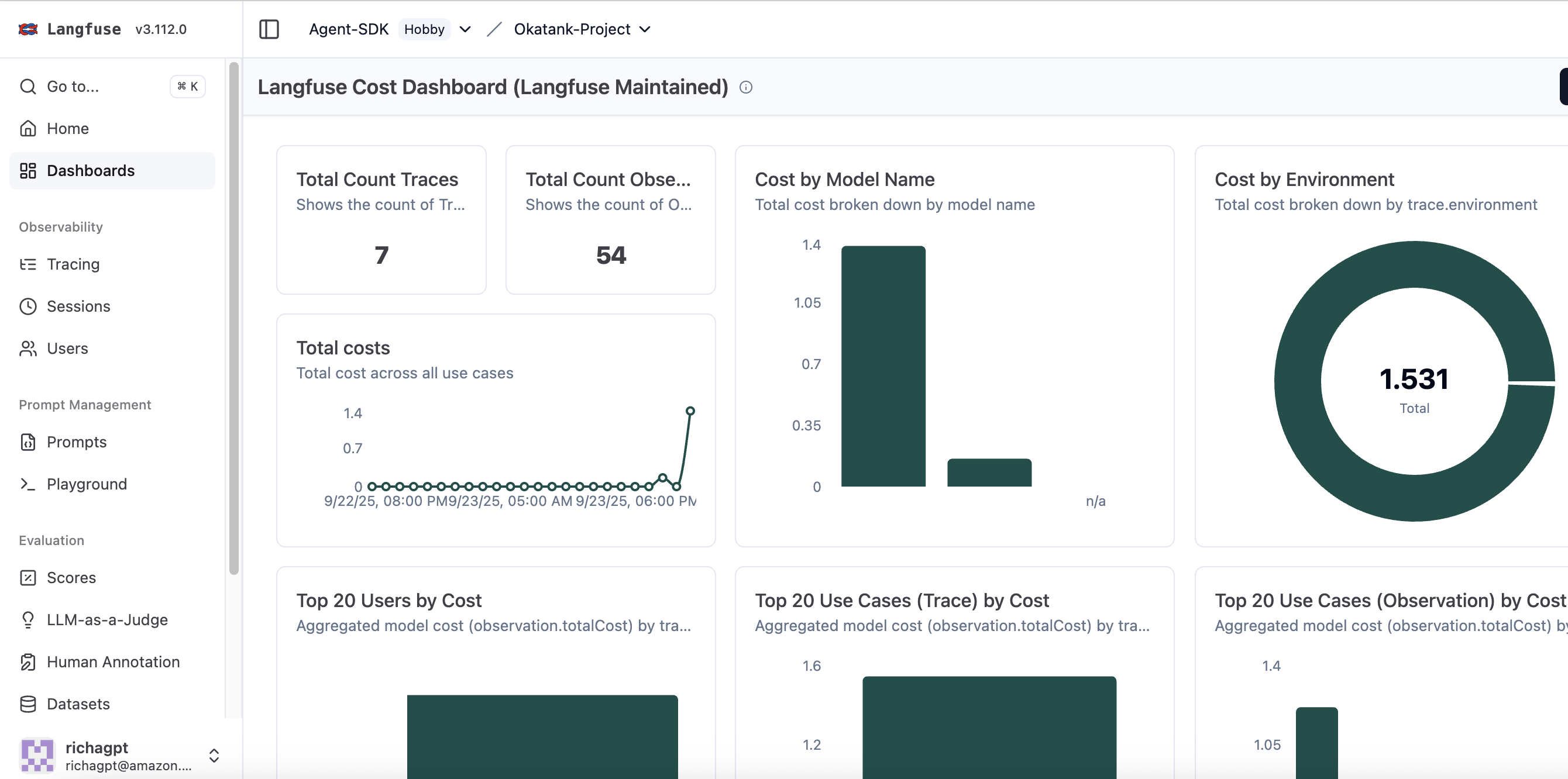
O assistente de voz oferece funcionalidades avançadas que tornam operações AWS mais intuitivas e eficientes. O sistema compreende consultas naturais de voz e as converte em chamadas apropriadas às APIs AWS. Por exemplo:
- “Mostrar todas as instâncias EC2 em execução em us-east-1”
- “Instalar o agente Amazon CloudWatch usando SSM nas minhas instâncias Dev”
- “Verificar o status dos trabalhos de backup de ontem à noite”
As respostas são especificamente otimizadas para entrega por voz, com resumos concisos limitados a 800 caracteres, informações estruturadas claras e fraseado conversacional que soa natural quando sintetizado em fala, evitando jargão técnico e utilizando sentenças completas adequadas para síntese de voz.
Colocando em Prática
Começar com o assistente de voz envolve três etapas principais:
Configuração do Ambiente
- Configurar credenciais AWS com acesso a Bedrock, Nova Sonic e serviços AWS alvo
- Preparar ambiente backend Python 3.12+ e frontend React
- Garantir permissões apropriadas de AWS Identity and Access Management (IAM) para operações multi-agente
Iniciando a Aplicação
- Iniciar o servidor Python WebSocket para processamento de voz
- Iniciar o frontend React com componentes AWS Cloudscape
- Configurar definições de voz e conexões WebSocket
- Começar interações de voz
Testando a Solução
- Conceder permissões de microfone do navegador para entrada de voz
- Testar com comandos de exemplo como “Listar minhas instâncias EC2” ou “Verificar status de backup”
- Experienciar respostas de voz em tempo real através de Amazon Nova Sonic
Instruções completas de implementação, exemplos de código e guias de solução de problemas estão disponíveis no repositório GitHub.
Exemplos de Comandos para Testar
Teste o assistente de voz com estes comandos de exemplo:
Gerenciamento de Instâncias EC2
- “Listar minhas instâncias EC2 dev onde a chave de tag é ‘env’”
- “Qual é o status dessas instâncias?”
- “Iniciar essas instâncias”
- “Essas instâncias têm permissões SSM?”
Gerenciamento de Backup
- “Garantir que essas instâncias sejam feitas backup diariamente”
Gerenciamento de SSM
- “Instalar agente CloudWatch usando SSM nessas instâncias”
- “Verificar essas instâncias quanto a patches usando SSM”
Exemplos de Implementação
Os exemplos de código demonstram padrões-chave de integração e práticas recomendadas para implementar o assistente de voz. Eles mostram como integrar Amazon Nova Sonic para processamento de voz e configurar o agente supervisor para roteamento inteligente de tarefas.
Configuração de Strands Agents
A implementação utiliza um padrão de orquestrador multi-agente com agentes especializados:
from strands import Agent
from config.conversation_config import ConversationConfig
from config.config import create_bedrock_model
class SupervisorAgent(Agent):
def __init__(self, specialized_agents, config=None):
bedrock_model = create_bedrock_model(config)
conversation_manager = ConversationConfig.create_conversation_manager("supervisor")
super().__init__(
model=bedrock_model,
system_prompt=self._get_routing_instructions(),
tools=[], # No tools for pure router
conversation_manager=conversation_manager,
)
self.specialized_agents = specialized_agentsIntegração com Nova Sonic
A implementação utiliza um servidor WebSocket com gerenciamento de sessão para processamento de voz em tempo real:
class S2sSessionManager:
def __init__(self, model_id='amazon.nova-sonic-v1:0', region='us-east-1', config=None):
self.model_id = model_id
self.region = region
self.audio_input_queue = asyncio.Queue()
self.output_queue = asyncio.Queue()
self.supervisor_agent = SupervisorAgentIntegration(config)
async def processToolUse(self, toolName, toolUseContent):
if toolName == "supervisoragent":
result = await self.supervisor_agent.query(content)
if len(result) > 800:
result = result[:800] + "... (truncated for voice)"
return {"result": result}Considerações de Segurança
Esta solução foi projetada para fins de desenvolvimento e testes. Antes de implantar em ambientes produtivos, implemente controles de segurança apropriados incluindo:
- Mecanismos de autenticação e autorização
- Controles de segurança de rede e restrições de acesso
- Monitoramento e logging para conformidade de auditoria
- Controles de custo e monitoramento de uso
Sempre siga as práticas recomendadas de segurança da AWS e o princípio do menor privilégio ao configurar permissões IAM.
Considerações para Produção
Embora esta solução demonstre capacidades de Strands Agents usando uma abordagem de implantação focada em desenvolvimento, organizações planejando implementações produtivas devem considerar o Amazon Bedrock AgentCore Runtime para hospedagem e gerenciamento em nível corporativo.
Benefícios do Amazon Bedrock AgentCore para Implantação Produtiva
- Runtime Serverless: Propositadamente construído para implantar e dimensionar agentes de IA dinâmicos sem gerenciar infraestrutura
- Isolamento de Sessão: Isolamento completo de sessão com microVMs dedicadas para cada sessão de usuário, fundamental para agentes que executam operações privilegiadas
- Auto-dimensionamento: Dimensionar para milhares de sessões de agente em segundos com precificação por uso
- Segurança Corporativa: Controles de segurança integrados com integração perfeita a provedores de identidade (Amazon Cognito, Microsoft Entra ID, Okta)
- Observabilidade: Rastreamento distribuído integrado, métricas e capacidades de depuração através da integração CloudWatch
- Persistência de Sessão: Altamente confiável com persistência de sessão para interações de agentes de longa duração
Para organizações prontas para avançar além de desenvolvimento e testes, o Amazon Bedrock AgentCore Runtime oferece a base pronta para produção necessária para implantar assistentes AWS baseados em voz em escala corporativa.
Extensão para Serviços AWS Adicionais
O sistema pode ser estendido para suportar serviços AWS adicionais:
- AWS Lambda: Executar funções serverless através de comandos de voz
- Amazon CloudWatch: Consultar métricas e logs através de linguagem natural
- Amazon Relational Database Service (RDS): Operações de gerenciamento e monitoramento de banco de dados
Síntese
O Assistente Nova Voice de Strands Agents demonstra o potencial significativo de combinar interfaces de voz com orquestração inteligente de agentes em diversos domínios. Ao aproveitar Amazon Nova Sonic para processamento de fala e Strands Agents para coordenação multi-agente, organizações podem criar formas mais intuitivas e eficientes de interagir com sistemas e fluxos de trabalho complexos.
Esta arquitetura fundamental estende-se muito além de operações em nuvem, habilitando soluções baseadas em voz para automação de atendimento ao cliente, análise financeira, gerenciamento de IoT, fluxos de trabalho em saúde, otimização de cadeia de suprimentos e inúmeras outras aplicações corporativas. A combinação de processamento de linguagem natural, roteamento inteligente e conhecimento especializado de domínio cria uma plataforma versátil para transformar como usuários interagem com qualquer sistema complexo.
A arquitetura modular garante escalabilidade e extensibilidade, permitindo que organizações personalizem a solução para seus domínios e casos de uso específicos. À medida que interfaces de voz continuam evoluindo e capacidades de IA avançam, soluções como esta tendem a se tornar cada vez mais importantes para gerenciar ambientes complexos em todas as indústrias.
Começando
Pronto para construir seu próprio assistente de operações AWS alimentado por voz? O código-fonte completo e documentação estão disponíveis no repositório GitHub. Siga este guia de implementação para começar e não hesite em personalizar a solução para seus casos de uso específicos. Para dúvidas, feedback ou contribuições, consulte o repositório do projeto ou procure nos fóruns da comunidade AWS.
Fonte
Building a voice-driven AWS assistant with Amazon Nova Sonic (https://aws.amazon.com/blogs/machine-learning/building-a-voice-driven-aws-assistant-with-amazon-nova-sonic/)