Claude Opus 4.5 chega ao Amazon Bedrock
O modelo de linguagem mais recente da Anthropic, o Claude Opus 4.5, está agora disponível no Amazon Bedrock, um serviço gerenciado que oferece acesso a modelos de linguagem de alto desempenho de empresas líderes em inteligência artificial. O Opus 4.5 representa um avanço significativo no que os sistemas de inteligência artificial podem realizar e estabelece novos patamares em programação, agentes de IA, interação com computadores e tarefas de produtividade.
Este modelo se destaca por superar tanto o Sonnet 4.5 quanto o Opus 4.1, enquanto oferece capacidades equivalentes às do Opus com um terço do custo anterior. Sua arquitetura foi especificamente projetada para desenvolvedores que constroem agentes de IA sofisticados—sistemas capazes de raciocinar, planejar e executar tarefas complexas com mínima supervisão humana.
O que distingue o Opus 4.5
Engenharia de software e codificação
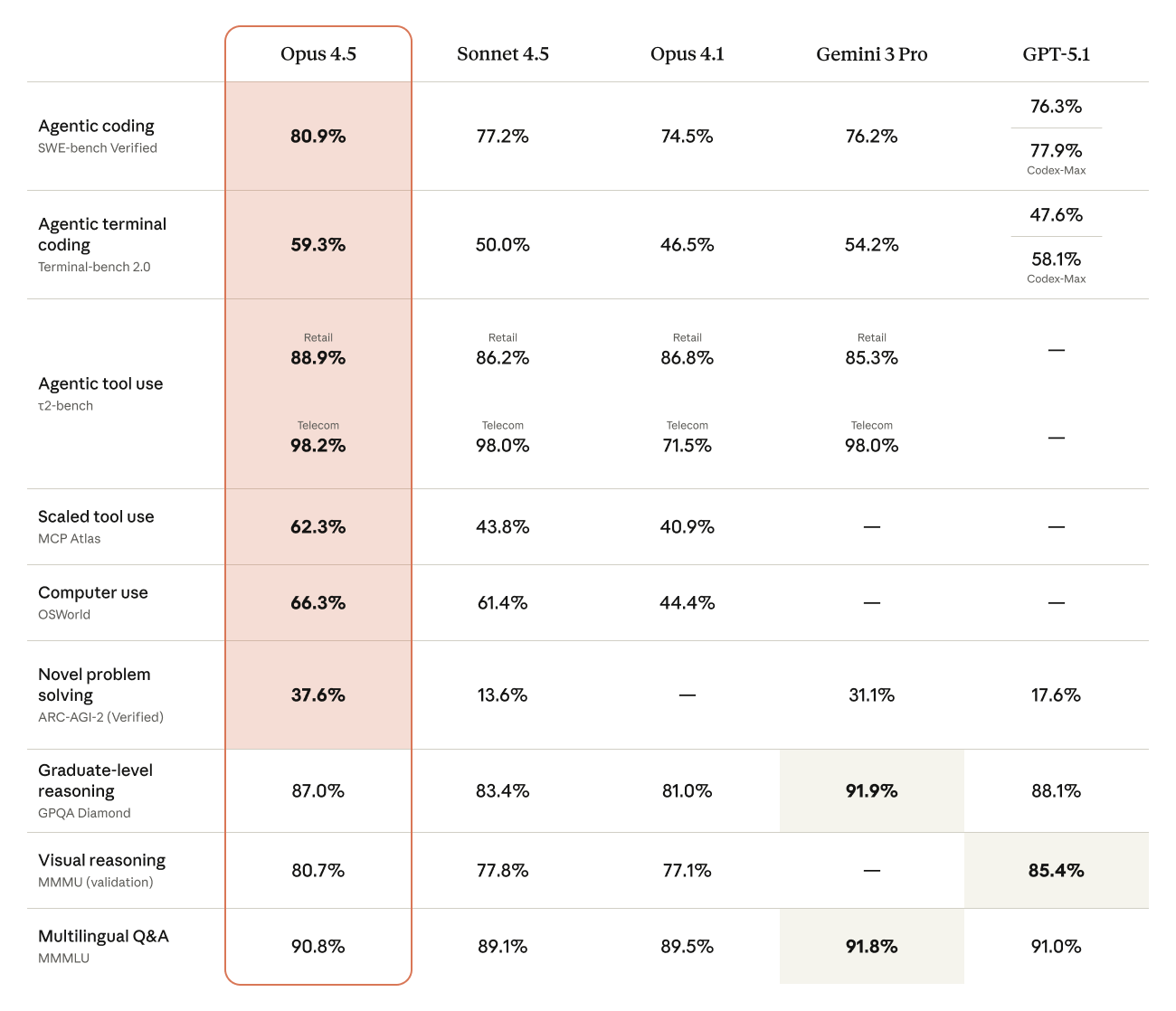
O Opus 4.5 demonstra desempenho excepcional em desenvolvimento profissional de software, alcançando 80,9% no benchmark SWE-bench Verified. Isso significa que o modelo pode transformar projetos de desenvolvimento que levariam vários dias em tarefas executáveis em horas. O modelo trabalha independentemente e inclui capacidades aprimoradas de codificação multilíngue, gerando código mais eficiente, melhor cobertura de testes e arquiteturas mais limpas.
Produtividade em tarefas empresariais
Para operações corporativas, o Opus 4.5 gerencia projetos complexos do início ao fim. Ele capacita agentes para criar apresentações em PowerPoint, planilhas em Excel e documentos em Word com acabamento profissional, incluindo revisão detalhada de documentos para contratos e acordos de não divulgação. O modelo também produz artefatos de React e HTML de qualidade superior, mantendo consistência e precisão—aspectos críticos para setores como finanças, onde a exatidão é fundamental. Ele preserva contexto entre arquivos durante projetos longos, garantindo coerência nas decisões.
Raciocínio visual avançado
Esta é a melhor capacidade de visão que a Anthropic ofereceu até agora, alcançando 80,7% no benchmark MMMU para fluxos de trabalho que dependem de interpretação visual complexa e navegação em múltiplas etapas. Exemplos incluem análise de mockups de design, processamento de documentos com layouts complexos e automatização de tarefas baseadas em navegação do navegador—com desempenho ainda mais aprimorado em interação com computadores.
Melhorias para desenvolvimento de agentes
O modelo introduz dois aprimoramentos-chave para desenvolvedores que criam agentes. A ferramenta de busca de ferramentas permite que agentes trabalhem com centenas de ferramentas descobrindo e carregando dinamicamente apenas aquelas que precisam, em vez de carregar todas as definições antecipadamente—potencialmente economizando dezenas de milhares de tokens e evitando confusão de esquemas ao escalar para grandes bibliotecas de ferramentas. Os exemplos de uso de ferramentas permitem fornecer chamadas de ferramentas exemplares diretamente na definição da ferramenta, melhorando a precisão para esquemas complexos com objetos ou arrays aninhados.
Casos de uso principais
Desenvolvimento de software
O Opus 4.5 é ideal para construir agentes que escrevem e refatoram código em projetos inteiros, gerenciam arquiteturas completas ou projetam sistemas multiagente que decompõem objetivos de alto nível em passos executáveis. A geração Claude abrange o ciclo completo de desenvolvimento: Opus 4.5 para código de produção e agentes sofisticados que usam 10 ou mais ferramentas em fluxos de trabalho como engenharia de software completa, cibersegurança ou análise financeira; Sonnet 4.5 para iteração rápida e experiências de usuário em escala; Haiku 4.5 para subagentos e produtos de acesso gratuito.
O Opus 4.5 pode analisar documentação técnica, planejar uma implementação de software, escrever o código necessário e refiná-lo iterativamente—mantendo rastreabilidade dos requisitos e contexto arquitetônico durante todo o processo.
Operações empresariais
Para gerenciar projetos complexos do início ao fim, o Opus 4.5 utiliza memória para manter contexto e consistência entre arquivos, com melhorias adicionais na criação de planilhas, slides e documentos. O modelo lida com projetos corporativos contínuos, automatizando fluxos de trabalho manuais.
Análise financeira
O modelo funciona eficientemente em sistemas complexos de informações—arquivos regulatórios, relatórios de mercado, dados internos—possibilitando modelagem preditiva e conformidade proativa. Sua consistência e precisão o tornam valioso para finanças e outros setores onde a exatidão é fundamental.
Cibersegurança
O Opus 4.5 oferece análise de nível profissional em fluxos de trabalho de segurança, correlacionando logs, bancos de dados de problemas de segurança e inteligência de segurança para detecção de eventos de segurança e resposta a incidentes automatizada.
Integração com o Amazon Bedrock AgentCore
A AWS fornece a fundação corporativa para implantar o Opus 4.5 em produção através do Amazon Bedrock AgentCore. O serviço gerenciado oferece uma API unificada para modelos de linguagem com segurança de nível corporativo, conformidade e governança.
O Opus 4.5 se integra ao AgentCore, que fornece infraestrutura e elementos primitivos para construir agentes de produção. O AgentCore inclui memória persistente para manter contexto entre sessões, o Gateway de Ferramentas para converter suas APIs e funções Lambda em ferramentas compatíveis com agentes, e gerenciamento de identidade e acesso integrado para acesso seguro aos recursos.
Você pode implantar e monitorar agentes com isolamento completo de sessão, suporte para fluxos de trabalho de longa duração (até 8 horas) e recursos de observabilidade—permitindo que você se concentre na construção de agentes em vez de gerenciar infraestrutura.
O Gateway de Ferramentas converte suas APIs e funções Lambda existentes em ferramentas compatíveis com agentes com mínimo de código—funcionando junto com o recurso de busca de ferramentas do modelo para orquestrar centenas de ferramentas. A observabilidade integrada através do Amazon CloudWatch rastreia uso de tokens, latência e taxas de erro em seus fluxos de trabalho de agentes.
Como começar
Para começar a usar o Opus 4.5 no Amazon Bedrock, você precisa configurar um cliente Python e importar as bibliotecas necessárias:
# Importar bibliotecas necessárias
import boto3
import json
# Criar uma sessão e cliente Bedrock
session = boto3.Session()
bedrock_client = session.client(
service_name='bedrock-runtime',
region_name='us-east-1'
)Neste exemplo, definimos múltiplas ferramentas com defer_loading para ativar a busca de ferramentas. Isso permite que o modelo descubra e carregue apenas as ferramentas que necessita em vez de carregar todas as definições antecipadamente:
# Definir ferramentas com busca de ferramentas ativada
tools = [
# Ativar busca de ferramentas - permite descoberta dinâmica de ferramentas
{
"type": "tool_search_tool_regex",
"name": "tool_search_tool_regex"
},
# Ferramentas marcadas com defer_loading são descobertas sob demanda
{
"name": "get_weather",
"description": "Obter clima atual para uma localização",
"input_schema": {
"type": "object",
"properties": {
"location": {"type": "string"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location"]
},
"defer_loading": True,
# Fornecer exemplos de entrada para melhorar precisão de esquemas complexos
"input_examples": [
{"location": "San Francisco, CA", "unit": "fahrenheit"},
{"location": "Tokyo, Japan", "unit": "celsius"}
]
},
{
"name": "search_documentation",
"description": "Pesquisar documentação da AWS",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string"},
"service": {"type": "string"}
},
"required": ["query"]
},
"defer_loading": True,
"input_examples": [
{"query": "Lambda pricing", "service": "lambda"},
{"query": "S3 bucket policies"}
]
},
{
"name": "analyze_logs",
"description": "Analisar logs de aplicação para erros",
"input_schema": {
"type": "object",
"properties": {
"log_file": {"type": "string"},
"time_range": {"type": "string"}
},
"required": ["log_file"]
},
"defer_loading": True,
"input_examples": [
{"log_file": "/var/log/app.log", "time_range": "last 24 hours"},
{"log_file": "/var/log/error.log"}
]
}
]Agora invocamos o modelo usando a Aplicação Programática (API) invoke_model com o parâmetro effort definido como médio:
# Construir a requisição com recursos beta ativados
request_body = {
"anthropic_version": "bedrock-2023-05-31",
# Ativar recursos beta: busca de ferramentas, exemplos de ferramentas e parâmetro effort
"anthropic_beta": ["tool-search-tool-2025-10-19", "tool-examples-2025-10-29", "effort-2025-11-24"],
"max_tokens": 4096,
"temperature": 0.7,
# Definir effort para "medium" para uso equilibrado de tokens
"output_config": {
"effort": "medium"
},
"messages": [
{
"role": "user",
"content": "What's the weather in Seattle?"
}
],
"tools": tools
}
# Invocar o modelo
response = bedrock_client.invoke_model(
modelId="global.anthropic.claude-opus-4-5-20251101-v1:0",
body=json.dumps(request_body)
)
# Fazer parsing da resposta
response_body = json.loads(response['body'].read())O modelo utiliza busca de ferramentas para localizar a ferramenta relevante (get_weather) da biblioteca sem carregar todas as definições de ferramentas antecipadamente. O parâmetro effort, disponível em versão beta, controla quanto liberalmente o modelo gasta tokens em raciocínio, chamadas de ferramentas e respostas. Você pode definir effort como alto para melhores resultados, médio para uso equilibrado ou baixo para uso conservador de tokens.
Capacidades principais para desenvolvimento de agentes
O Opus 4.5 possui várias capacidades que o tornam adequado para construir agentes em produção. O modelo mantém coerência em fluxos de trabalho estendidos, permitindo tomada de decisão consistente para agentes que executam processos com múltiplas etapas ao longo de horas ou dias. Melhor manipulação de ferramentas significa que agentes interagem mais confiávelmente com sistemas externos, Aplicações Programáticas (APIs) e interfaces de software—o modelo escolhe as ferramentas certas e interpreta resultados com maior precisão.
O Opus 4.5 também rastreia informações entre conversas e mantém contexto, ajudando agentes a acumular conhecimento ao longo do tempo e tomar decisões baseadas em histórico. O parâmetro effort, disponível em versão beta, oferece controle sobre uso de tokens. Você pode defini-lo como alto para melhores resultados quando qualidade importa mais, médio para desempenho equilibrado ou baixo para uso conservador de tokens. O Opus 4.5 ajusta o gasto de tokens entre raciocínio, chamadas de ferramentas e respostas com base nesta configuração.
Para implantações em produção, o Amazon Bedrock AgentCore oferece monitoramento e observabilidade através da integração com CloudWatch, rastreando uso de tokens em tempo real (útil ao ajustar o parâmetro effort), junto com métricas de latência, duração da sessão e taxas de erro para ajudar a otimizar desempenho do agente e gerenciar custos.
Preços e disponibilidade
O modelo é precificado em $5 por milhão de tokens de entrada e $25 por milhão de tokens de saída, tornando a inteligência em nível Opus acessível a um terço do custo das ofertas anteriores.
O modelo está disponível hoje no Amazon Bedrock através de inferência entre regiões, que roteia automaticamente requisições para capacidade disponível em regiões da AWS para maior throughput durante picos de demanda. Use este modelo para agentes que lidam com tarefas de longa duração, coordenam múltiplas ferramentas ou mantêm contexto em sessões estendidas.
Para informações detalhadas sobre disponibilidade, preços e especificações do modelo, consulte a documentação do Amazon Bedrock.
Próximos passos
Para começar, experimente o modelo no console do Amazon Bedrock, explore a documentação técnica e consulte a página de detalhes do modelo Claude da Anthropic para mais informações sobre suas capacidades.
Para implantar agentes em escala, explore o Opus 4.5 no Amazon Bedrock AgentCore para obter infraestrutura gerenciada com orquestração de ferramentas e monitoramento. O Opus 4.5 se destaca em fluxos de trabalho complexos e de longa duração, como desenvolvimento de software e operações empresariais. Suas capacidades em manipulação de ferramentas, gerenciamento de contexto e tomada de decisão o tornam valioso para construir agentes que operam de forma confiável em ambientes de produção.
Fonte
Claude Opus 4.5 now in Amazon Bedrock (https://aws.amazon.com/blogs/machine-learning/claude-opus-4-5-now-in-amazon-bedrock/)