A AWS expandiu significativamente as capacidades da plataforma AWS Transform, evoluindo de um agente focado em modernização .NET para uma solução de modernização de pilha completa em ambientes Windows. Essa evolução representa um avanço importante para organizações que trabalham com aplicações .NET e seus bancos de dados associados, oferecendo uma abordagem integrada e automatizada para a transformação.
O novo agente de modernização de pilha completa em Windows gerencia tanto aplicações .NET quanto bancos de dados Microsoft SQL Server, transformando-os para arquiteturas modernas baseadas em nuvem. As aplicações são migradas para Amazon Aurora PostgreSQL e implantadas em containers dentro de Amazon ECS ou em instâncias Amazon EC2 Linux.
Ganhos de Desempenho e Eficiência
A plataforma oferece melhorias expressivas: acelera a modernização de pilha completa em 5 vezes (comparando camadas de aplicação e banco de dados) e reduz custos operacionais em até 70%. Esses números refletem a automação de tarefas repetitivas e a otimização das arquiteturas resultantes.
Como Funciona o Fluxo de Transformação
Descoberta e Planejamento
O agente realiza varredura em bancos de dados Microsoft SQL Server localizados em instâncias Amazon EC2 ou Amazon RDS, além de examinar o código da aplicação .NET a partir de repositórios de código-fonte (GitHub, GitLab, Bitbucket ou Azure Repos). Com base nesses dados, cria planos de modernização personalizados que podem ser editados conforme necessário.
Transformação de Dados e Aplicação
Na etapa de transformação, o agente converte esquemas do SQL Server para Aurora PostgreSQL e realiza a migração dos bancos de dados para clusters Aurora PostgreSQL novos ou existentes. Para as aplicações .NET, atualiza as conexões de banco de dados no código-fonte e modifica o código de acesso a dados escrito em Entity Framework e ADO.NET para compatibilidade com Aurora PostgreSQL. Todo esse processo ocorre em um fluxo unificado com supervisão humana, e o código transformado é consolidado em um novo branch do repositório.
Validação e Monitoramento
As aplicações transformadas e seus bancos de dados podem ser implantados em ambientes novos ou existentes para validação. Os clientes acompanham o progresso da transformação por meio de atualizações de worklog e chat interativo. O sistema gera resumos detalhados da transformação com recomendações para próximos passos, facilitando a transição para assistentes de código IA.
A AWS anunciou a disponibilidade de enriquecimento semântico automático para o Amazon OpenSearch Service em clusters gerenciados. Esse recurso havia sido lançado anteriormente para o OpenSearch Serverless e agora se estende às implementações tradicionais da plataforma.
Essa expansão permite que os usuários aproveitem o poder da busca semântica com esforço mínimo de configuração. Diferentemente das buscas lexicais tradicionais, que buscam apenas correspondências exatas de termos, a busca semântica compreende contexto e significado, entregando resultados muito mais relevantes.
Como funciona na prática
Um exemplo prático ilustra bem a diferença. Quando um usuário busca por “opções de transporte ecológico”, a busca semântica encontra correspondências para “veículos elétricos” ou “transporte público” — mesmo que esses termos exatos não apareçam nos documentos. A busca tradicional deixaria passar esses resultados relevantes por falta de correspondência literal.
O grande diferencial é que o OpenSearch agora gerencia automaticamente todo o processamento semântico. Não há necessidade de manter ou configurar modelos de aprendizado de máquina manualmente, reduzindo significativamente a complexidade operacional.
Suporte a múltiplos idiomas
A funcionalidade suporta variantes exclusivamente em inglês e também versões multilíngues que cobrem 15 idiomas distintos. Entre eles estão árabe, francês, hindi, japonês, coreano e várias outras línguas, tornando a capacidade acessível a organizações globais.
Modelo de precificação
A cobrança é baseada no uso real durante a ingestão de dados. Ela ocorre através da unidade de computação do OpenSearch — especificamente a variante de Busca Semântica. Mais detalhes sobre custos e exemplos de precificação estão disponíveis na página de precificação.
Disponibilidade e requisitos
O recurso já está disponível para domínios do Amazon OpenSearch Service que executam versão 2.19 do OpenSearch ou posterior. Atualmente, suporta domínios fora de VPC nas seguintes regiões da AWS: US East (N. Virginia), US East (Ohio), US West (Oregon), Ásia Pacífico (Mumbai), Ásia Pacífico (Singapura), Ásia Pacífico (Sydney), Ásia Pacífico (Tóquio), Europa (Frankfurt), Europa (Irlanda) e Europa (Estocolmo).
Para começar a usar o enriquecimento semântico automático, consulte a documentação disponível para guias e práticas recomendadas de implementação.
A AWS anunciou uma expansão significativa na disponibilidade do modelo Pegasus 1.2, desenvolvido pela TwelveLabs, através do Amazon Bedrock. Com a introdução de inferência global entre regiões, o modelo agora está acessível em 23 novas regiões, complementando as sete regiões onde já estava disponível anteriormente. Além disso, o Bedrock passou a oferecer acesso ao modelo em todas as regiões da União Europeia utilizando inferência geográfica entre regiões.
Diferenças nas Estratégias de Inferência
A AWS disponibiliza duas estratégias distintas de processamento para esse modelo. A inferência geográfica entre regiões é ideal para cargas de trabalho que apresentam requisitos específicos de residência de dados ou conformidade regulatória dentro de limites geográficos definidos. Por outro lado, a inferência global entre regiões é recomendada para aplicações que priorizam disponibilidade e performance em múltiplas geografias, permitindo que o processamento aconteça onde houver melhor desempenho.
Capacidades do Modelo Pegasus 1.2
O Pegasus 1.2 é um modelo de linguagem orientado para processamento de vídeos que consegue gerar texto baseado no conteúdo visual, áudio e textual dentro de vídeos. Desenvolvido especificamente para vídeos de longa duração, o modelo se destaca na geração de texto a partir de vídeos e na compreensão temporal, permitindo análises sofisticadas de conteúdo videográfico.
Benefícios da Maior Disponibilidade Regional
Com a expansão do Pegasus 1.2 para essas regiões adicionais, desenvolvedores podem construir aplicações de inteligência em vídeo mais próximas aos seus dados e usuários finais. Essa proximidade reduz a latência das requisições e simplifica a arquitetura geral das soluções, permitindo processamento mais rápido e eficiente.
Próximos Passos
Para obter a lista completa de perfis de inferência suportados e regiões disponíveis para o Pegasus 1.2, consulte a documentação de inferência entre regiões. Para começar a trabalhar com o Pegasus 1.2, acesse o console do Amazon Bedrock. Mais detalhes técnicos e informações adicionais estão disponíveis na página do produto e na documentação do Amazon Bedrock.
Novidade no Amazon Connect: Avaliações automáticas de qualidade
A AWS anunciou uma funcionalidade inovadora para o Amazon Connect, permitindo que empresas avaliem automaticamente a qualidade das interações de autoatendimento. Essa capacidade oferece aos gerentes e supervisores uma visão consolidada do desempenho geral, além da possibilidade de analisar contatos individuais para identificar pontos de melhoria.
Como funciona a avaliação automática
O novo recurso permite que os gerentes definam critérios customizados para avaliar a qualidade das interações de autoatendimento. Esses critérios podem ser preenchidos de duas formas: manualmente pelos supervisores ou automaticamente através de insights obtidos por meio de análise de conversas e outros dados disponíveis no Connect.
Exemplo prático de uso
Uma aplicação comum é avaliar automaticamente se um agente de IA tem dificuldade para entender o cliente. Quando esse problema ocorre, muitas vezes resulta em sentimento negativo do cliente e eventual transferência para um atendente humano. Identificar esses padrões permite que os gerentes ajustem treinamentos e configurações do agente para melhorar sua compreensão.
Análise de dados e melhorias contínuas
Os gerentes podem revisar os insights agregados sobre as interações, bem como acessar registros e transcrições de autoatendimento específicas. Essa visibilidade facilita a identificação de oportunidades para otimizar o desempenho do agente de IA e, consequentemente, melhorar a experiência do cliente.
Disponibilidade da funcionalidade
As avaliações de autoatendimento preenchidas manualmente estão disponíveis em todas as regiões onde o Amazon Connect é oferecido. As avaliações automáticas, por sua vez, estão limitadas a regiões específicas: Leste dos EUA (N. Virginia), Oeste dos EUA (Oregon), Ásia Pacífico (Seul), Ásia Pacífico (Singapura), Ásia Pacífico (Sydney), Ásia Pacífico (Tóquio) e Europa (Frankfurt).
Próximos passos
Para conhecer detalhes sobre preços e modelos de cobrança, consulte a página de preços do Amazon Connect. A documentação técnica disponibiliza guias completos sobre como criar e configurar formulários de avaliação. Também é possível aprender mais sobre a plataforma através da página principal do Amazon Connect.
A AWS anunciou a disponibilidade das instâncias Amazon EC2 C8gn em duas novas regiões: US East (Ohio) e Middle East (UAE). Essas instâncias são equipadas com os processadores AWS Graviton4, a geração mais recente de chips customizados desenvolvidos pela empresa, marcando um importante passo na expansão da plataforma para atender melhor aos clientes em diferentes geografias.
Ganhos em desempenho e conectividade
As instâncias C8gn trazem melhorias significativas em relação às gerações anteriores. O desempenho computacional é até 30% superior quando comparado com as instâncias C7gn baseadas em Graviton3. Além disso, utilizam a 6ª geração do AWS Nitro Cards, a infraestrutura de virtualização proprietária da AWS.
Destaque especial para a conectividade de rede: as C8gn oferecem até 600 Gbps de largura de banda de rede, a maior disponível entre as instâncias EC2 otimizadas para rede. Essa capacidade é acompanhada de até 60 Gbps de banda para armazenamento em Amazon Elastic Block Store (EBS), permitindo escalabilidade robusta para cargas exigentes.
Escalabilidade e capacidade
A linha C8gn oferece tamanhos de instâncias que variam até 48xlarge, com até 384 GiB de memória disponível. Essa gama de tamanhos permite que diferentes tipos de carga de trabalho encontrem a configuração ideal de recursos.
Para cenários mais avançados de processamento paralelo, a AWS integrou suporte a Elastic Fabric Adapter (EFA) nos tamanhos 16xlarge, 24xlarge, 48xlarge, metal-24xl e metal-48xl. Essa capacidade de rede especializada reduz a latência e melhora o desempenho de aglomerados fortemente acoplados, essencial para simulações científicas, análises de big data e treinamento distribuído de modelos.
Casos de uso ideais
A AWS destaca que as instâncias C8gn são particularmente adequadas para executar cargas de trabalho intensivas em rede, como:
Appliances virtuais de rede
Análise de dados em larga escala
Inferência de IA e aprendizado de máquina baseada em CPU
A combinação de largura de banda de rede excepcional com processamento de CPU potente as torna especialmente valiosas para aplicações que precisam processar grandes volumes de dados com baixa latência.
Disponibilidade regional
As instâncias C8gn agora estão disponíveis nas seguintes regiões da AWS:
US East (N. Virginia, Ohio)
US West (Oregon, N. California)
Europe (Frankfurt, Stockholm)
Asia Pacific (Singapore, Malaysia, Sydney, Thailand)
Inteligência Artificial no Gerenciamento de Servidores de Jogos
A AWS anunciou, em dezembro de 2025, o lançamento de um novo recurso de assistência com inteligência artificial na console AWS, especificamente para desenvolvedores que utilizam o GameLift Servers. Este avanço representa um passo importante na simplificação do gerenciamento de infraestrutura para jogos em escala.
A funcionalidade integra o Amazon Q Developer — um assistente inteligente da AWS — com conhecimentos especializados sobre o GameLift Servers. O objetivo é fornecer orientações personalizadas que ajudem desenvolvedoras e desenvolvedores a navegar por fluxos de trabalho complexos de forma mais ágil e eficiente.
Capacidades do Novo Recurso
Com a assistência IA ativada, desenvolvedores ganham acesso a recomendações inteligentes para três aspectos críticos do desenvolvimento com GameLift:
Integração de servidores de jogos: Orientações para conectar o servidor do jogo à plataforma de forma correta
Configuração de frotas: Sugestões para otimizar a disposição e gerenciamento de instâncias
Otimização de desempenho: Recomendações baseadas em padrões de uso para melhorar a experiência do jogador
Benefícios Práticos para Desenvolvedores
A IA integrada na console busca resolver três problemas principais enfrentados por desenvolvedoras e desenvolvedores:
Redução de tempo de troubleshooting: O assistente ajuda a identificar e resolver problemas mais rapidamente
Tomadas de decisão simplificadas: Recomendações contextualizadas reduzem incertezas em configurações complexas
Melhor utilização de recursos: Orientações para otimização resultam em economia de custos e melhor aproveitamento da infraestrutura
Consequentemente, esses avanços contribuem tanto para redução de gastos quanto para melhoria da experiência dos jogadores finais, que se beneficiam de servidores melhor configurados e otimizados.
Disponibilidade Global
A assistência baseada em inteligência artificial está disponível em todas as regiões onde o GameLift Servers é suportado. A única exceção é a AWS China, que mantém restrições específicas para serviços da Amazon.
Para explorar essa funcionalidade em detalhes e entender como integrá-la ao seu fluxo de desenvolvimento, desenvolvedores podem consultar a documentação oficial do GameLift Servers. Além disso, informações sobre quais regiões suportadas estão habilitadas para este recurso podem ser encontradas na documentação específica.
Contexto para o Ecossistema de Desenvolvimento de Jogos
Este lançamento reflete a tendência crescente de integração de IA em ferramentas de desenvolvimento na nuvem. A AWS reconhece que gerenciar infraestrutura de servidores de jogos — com suas demandas de latência, escalabilidade e confiabilidade — é uma tarefa complexa que se beneficia significativamente de assistência inteligente.
Ao colocar o Amazon Q Developer diretamente na console do GameLift, a empresa facilita o acesso a orientações especializadas no momento em que os desenvolvedores mais precisam: durante o planejamento, configuração e otimização contínua de seus servidores.
Proteção aprimorada contra ataques DDoS na camada de aplicação
Nos primeiros meses deste ano, a AWS implementou novas camadas de proteção para aplicações, respondendo ao crescimento de ataques de negação de serviço distribuído (DDoS) de curta duração e alto volume na camada 7 (L7). Essas proteções são oferecidas através do grupo de regras gerenciadas Anti-DDoS AMR (Regras Gerenciadas Anti-DDoS da AWS). Embora a configuração padrão seja eficaz para a maioria dos cenários, você pode personalizar a resposta para se adequar à tolerância ao risco da sua aplicação.
Neste artigo, exploraremos como o Anti-DDoS AMR funciona internamente e como você pode ajustar seu comportamento utilizando rótulos e regras adicionais do AWS WAF. Você acompanhará três cenários práticos, cada um demonstrando uma técnica diferente de personalização.
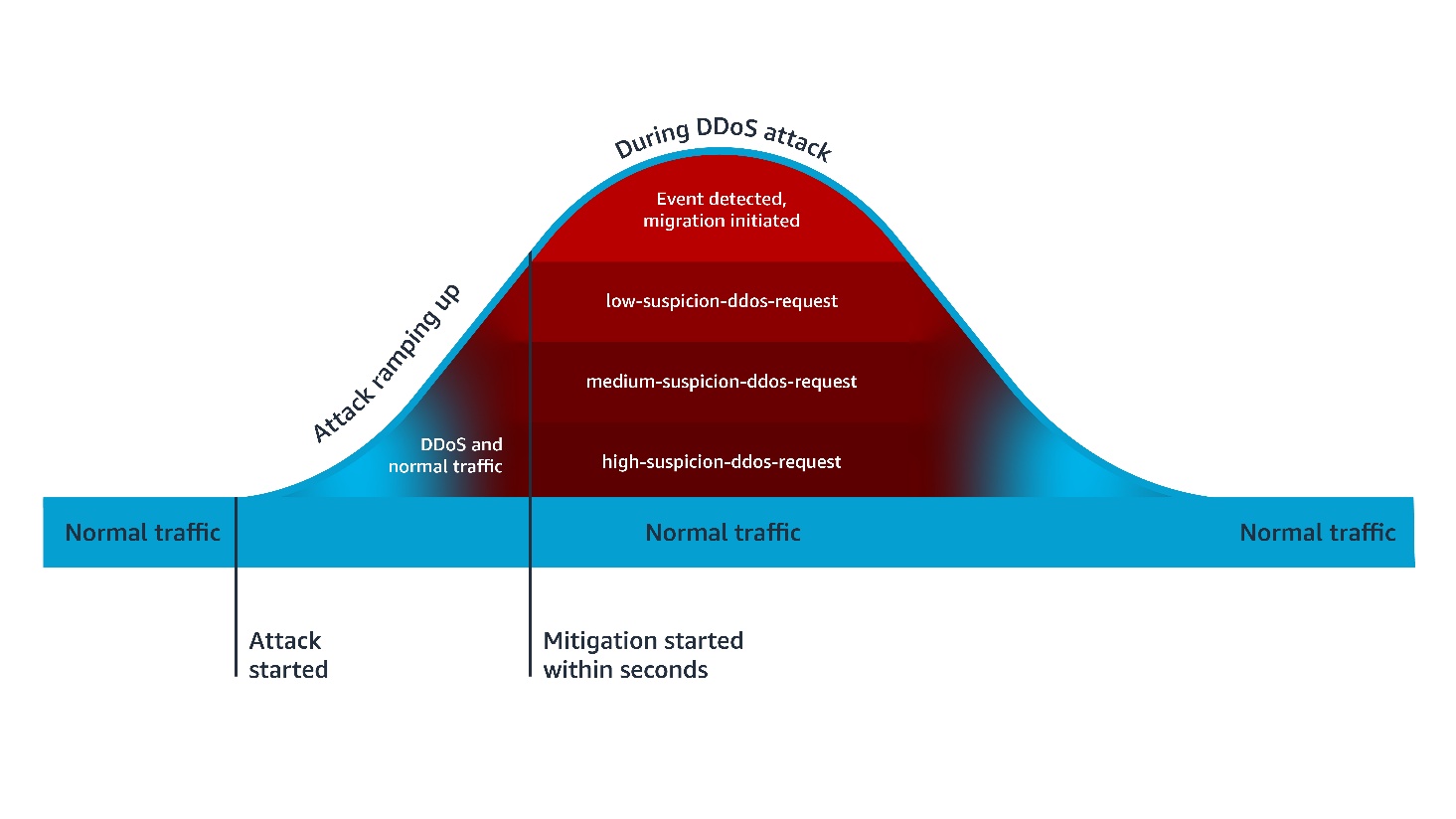
Como o Anti-DDoS AMR funciona
Detecção de anomalias e aplicação de rótulos
O Anti-DDoS AMR estabelece uma linha de base do seu tráfego e a utiliza para detectar anomalias em questão de segundos. Quando um ataque DDoS é identificado, o serviço adiciona metadados às requisições — aquilo que o AWS WAF chama de rótulos. Especificamente, todas as requisições recebem o rótulo event-detected, enquanto as requisições suspeitas de contribuir para o ataque recebem o rótulo ddos-request.
Além disso, rótulos adicionais baseados em confiança são aplicados, como high-suspicion-ddos-request, quando existe alta suspeita de que a requisição faz parte do ataque. Em termos técnicos, um rótulo é um metadado adicionado a uma requisição por uma regra quando ela é correspondida. Após ser adicionado, o rótulo fica disponível para as regras subsequentes, que podem utilizá-lo para enriquecer sua lógica de avaliação.
As mitigações padrão combinam dois tipos de ação: bloqueio direto e desafio JavaScript. O desafio funciona apenas com clientes que esperam conteúdo HTML. Por esse motivo, você precisa excluir requisições que não podem ser desafiadas — como chamadas de API — nas configurações do Anti-DDoS AMR. O serviço aplica o rótulo challengeable-request às requisições que não correspondem às exclusões configuradas.
As regras de mitigação padrão são avaliadas na seguinte sequência:
ChallengeAllDuringEvent: Equivalente à lógica: SE event-detected E challengeable-request, ENTÃO desafiar. Esta regra ativa desafios para todas as requisições elegíveis durante um evento detectado.
ChallengeDDoSRequests: Equivalente à lógica: SE (high-suspicion-ddos-request OU medium-suspicion-ddos-request OU low-suspicion-ddos-request) E challengeable-request, ENTÃO desafiar. A sensibilidade pode ser ajustada para desafiar apenas requisições de média e alta suspeita.
DDoSRequests: Equivalente à lógica: SE high-suspicion-ddos-request, ENTÃO bloquear. A sensibilidade pode ser aumentada para bloquear também requisições de média suspeita, por exemplo.
Personalizando sua resposta aos ataques DDoS
Duas abordagens de personalização
Existem dois caminhos principais para personalizar como você responde a ataques DDoS na camada 7. Na primeira abordagem, você configura o Anti-DDoS AMR para a ação desejada e, em seguida, adiciona regras subsequentes para enrijecer ainda mais sua resposta sob condições específicas. Na segunda abordagem, você converte algumas ou todas as regras do Anti-DDoS AMR para modo de contagem e cria regras adicionais que definem sua resposta personalizada.
Em ambas as abordagens, as regras subsequentes são configuradas utilizando condições que você define, combinadas com condições baseadas em rótulos aplicados pelo Anti-DDoS AMR. Para configurar regras com lógica complexa, você precisará usar o editor JSON do AWS WAF ou ferramentas de infraestrutura como código, como AWS CloudFormation ou Terraform.
Exemplo 1: Mitigação mais sensível fora de países principais
Suponha que sua operação ocorra principalmente em dois países: Emirados Árabes Unidos e Arábia Saudita. Você está satisfeito com o comportamento padrão do Anti-DDoS AMR nesses países, mas deseja bloquear mais agressivamente fora deles. Você pode implementar isso com as seguintes regras:
Anti-DDoS AMR com configurações padrão
Uma regra customizada que bloqueia se: a requisição vier de fora dos Emirados Árabes Unidos ou Arábia Saudita E a requisição tiver os rótulos high-suspicion-ddos-request ou medium-suspicion-ddos-request
Após adicionar o Anti-DDoS AMR com configuração padrão, crie uma regra customizada subsequente com a seguinte definição JSON:
De forma similar, durante um ataque, você pode mitigar de forma mais agressiva requisições de fontes incomuns, como aquelas identificadas pelo grupo de regras gerenciadas de reputação de IP como provenientes de provedores de hospedagem e nuvem.
Exemplo 2: Redução de limites de taxa durante ataques DDoS
Imaginemos que sua aplicação possui URLs sensíveis que são computacionalmente intensivas. Para proteger a disponibilidade, você aplicou uma regra de limitação de taxa configurada com um limite de 100 requisições a cada 2 minutos. Você pode enrijecer essa resposta durante um ataque DDoS aplicando um limite mais agressivo. Você pode implementar isso com:
Anti-DDoS AMR com configurações padrão
Uma regra de limitação de taxa, restrita às URLs sensíveis, configurada com limite de 100 requisições em janela de 2 minutos
Uma segunda regra de limitação de taxa, restrita às URLs sensíveis E ao rótulo event-detected, configurada com limite de 10 requisições em janela de 10 minutos
Após adicionar o Anti-DDoS AMR com configuração padrão e sua regra de limitação de taxa para URLs sensíveis, crie uma nova regra de limitação com a seguinte definição JSON:
Exemplo 3: Resposta adaptativa conforme escalabilidade da aplicação
Considere uma aplicação legada que pode escalar com segurança até um certo limite de volume de tráfego, além do qual degrada. Se o volume total de tráfego, incluindo ataque DDoS, estiver abaixo desse limite, você decide não desafiar todas as requisições durante um ataque para evitar impactar a experiência do usuário. Neste cenário, você depende apenas da ação de bloqueio padrão para requisições de alta suspeita. Porém, se o volume total exceder o limite seguro, você ativa a mitigação equivalente a ChallengeDDoSRequests.
Você pode implementar isso com:
Anti-DDoS AMR com as regras ChallengeAllDuringEvent e ChallengeDDoSRequests configuradas em modo de contagem
Uma regra de limitação de taxa que conta seu tráfego, configurada com um limite correspondente à capacidade da sua aplicação, que aplica um rótulo customizado — como CapacityExceeded — quando o limite é atingido
Uma regra que replica ChallengeDDoSRequests, mas apenas quando o rótulo CapacityExceeded está presente: desafiar se os rótulos ddos-request, CapacityExceeded e challengeable-request estão todos presentes
Primeiro, atualize seu Anti-DDoS AMR alterando as ações Challenge para Count.
Em seguida, crie a regra de detecção de capacidade excedida em modo de contagem, usando a seguinte definição JSON:
Ao combinar as proteções integradas do Anti-DDoS AMR com lógica customizada, você consegue adaptar suas defesas para corresponder ao seu perfil de risco único, padrões de tráfego e escalabilidade da aplicação. Os exemplos apresentados ilustram como você pode ajustar a sensibilidade, aplicar mitigações mais fortes sob condições específicas e até construir defesas adaptativas que respondem dinamicamente à capacidade do seu sistema.
O sistema dinâmico de rótulos no AWS WAF permite implementar essas personalizações de forma granular. Você pode também utilizar rótulos do AWS WAF para excluir o registro custoso de tráfego de ataque DDoS, otimizando sua observabilidade sem sacrificar a segurança.
O desafio da infraestrutura de chaves públicas em escala
A Infraestrutura de Chaves Públicas (PKI) é fundamental para garantir a segurança e estabelecer confiança nas comunicações digitais. À medida que as organizações expandem suas operações digitais, precisam emitir e revogar certificados continuamente. A revogação de certificados é especialmente importante quando funcionários se desligam, durante migrações para novas hierarquias de autoridades certificadoras, para atender requisitos de conformidade ou em resposta a incidentes de segurança.
Porém, empresas que enfrentam crescimento significativo encontram limitações ao usar CRLs completas para emitir e revogar mais de 1 milhão de certificados. Simplesmente aumentar o tamanho do arquivo CRL não é uma solução viável, pois muitas aplicações não conseguem processar arquivos CRL grandes — algumas exigem um máximo de 1 MB. Além disso, soluções alternativas como OCSP podem ser rejeitadas por grandes repositórios de confiança e fornecedores de navegadores devido a preocupações com privacidade e requisitos de conformidade. Essas restrições impactam significativamente a capacidade das organizações de escalar sua infraestrutura de PKI de forma eficiente, mantendo segurança e conformidade.
A solução: CRLs particionadas
A AWS Private CA agora oferece CRLs particionadas como resposta a esses desafios. Essa funcionalidade permite a emissão e revogação de até 100 milhões de certificados por CA, distribuindo as informações de revogação em múltiplas partições de CRL menores e gerenciáveis, cada uma mantendo um tamanho máximo de 1 MB para melhor compatibilidade com aplicações.
No momento da emissão, os certificados são automaticamente vinculados a partições CRL específicas através de uma extensão crítica de Ponto de Distribuição do Emissor (IDP), que contém uma URI única identificando a partição. A validação funciona comparando a URI de CRL na extensão de Ponto de Distribuição de CRL (CDP) do certificado contra a extensão IDP da CRL, proporcionando validação precisa.
Capacidades principais da nova funcionalidade
As CRLs particionadas oferecem diversos benefícios operacionais:
Escalabilidade automática do limite de emissão de certificados: de 1 milhão para 100 milhões de certificados por CA
Suporte tanto para novas quanto para autoridades certificadoras existentes
Opções de configuração flexível para nomes e caminhos de CRL
Compatibilidade reversa, preservando a funcionalidade completa de CRL existente enquanto oferece CRL particionada como recurso opcional
Conformidade com padrões da indústria, como o RFC5280, mantendo eficiência operacional e segurança
Configurando CRLs particionadas na AWS Private CA
A configuração de CRLs particionadas em autoridades certificadoras existentes segue um processo estruturado através do console da AWS:
Passos de configuração
Para ativar CRLs particionadas, acesse sua autoridade certificadora privada no console da AWS Private CA. Primeiro, selecione a CA desejada e navegue até a aba de configuração de revogação. Se a distribuição de CRL estiver desabilitada, você precisará ativá-la nos próximos passos.
Ao editar as configurações, marque a opção para ativar distribuição de CRL e selecione um bucket do Amazon S3 existente para armazenar os arquivos de CRL. É importante verificar que o recurso de Bloqueio de Acesso Público está desabilitado para sua conta e para o bucket. Se necessário, você pode consultar a documentação sobre criar uma CA privada na AWS Private CA para obter instruções detalhadas sobre políticas de acesso. Para configurações de segurança mais específicas, consulte o guia sobre políticas de acesso para CRLs no Amazon S3 e aprenda como adicionar uma política de bucket usando o console do Amazon S3.
Na seção de configurações de CRL, marque a caixa para ativar o particionamento. Isso habilitará o uso de CRL particionada. Se você não ativar o particionamento, uma CRL completa será criada e sua CA ficará sujeita ao limite de 1 milhão de certificados emitidos ou revogados. Para informações sobre limites de capacidade, consulte as cotas da AWS Private CA.
Após salvar as alterações, a distribuição de CRL aparecerá como habilitada com CRLs particionadas, e o limite de 1 milhão será automaticamente atualizado para 100 milhões por CA.
Benefícios para segurança, operações e conformidade
As CRLs particionadas da AWS Private CA oferecem benefícios substanciais em múltiplas dimensões organizacionais.
Perspectiva de segurança
A funcionalidade mantém a validação de certificados enquanto suporta capacidades abrangentes de revogação para até 100 milhões de certificados por CA. Isso permite que as organizações respondam efetivamente a incidentes de segurança ou comprometimento de chaves.
Perspectiva operacional
Operacionalmente, o recurso reduz a necessidade de rotação de autoridades certificadoras, diminuindo a sobrecarga administrativa e simplificando o gerenciamento de PKI. Manter os tamanhos de partição de CRL em 1 MB oferece compatibilidade ampla com aplicações, enquanto suporta gerenciamento automático de partições.
Perspectiva de conformidade
Para conformidade regulatória, a solução permite que as organizações atendam a múltiplos requisitos da indústria:
Alinhamento com requisitos de repositórios de confiança de navegadores para suporte tanto a CRL quanto a OCSP
Flexibilidade para padrões emergentes, como Matter
Custo e disponibilidade
Um ponto importante é que você pode maximizar o valor de suas autoridades certificadoras de propósito geral ou vida curta ativando CRL particionada sem custos adicionais, além da AWS Private CA e do Amazon Simple Storage Service (Amazon S3). Todos os certificados continuam sendo revogáveis, proporcionando uma solução completa e econômica para gestão de PKI em escala.
Próximos passos
Organizações interessadas em começar podem criar sua autoridade certificadora através do console de gerenciamento da AWS Private CA. A nova funcionalidade está disponível para configuração imediata em autoridades certificadoras existentes ou novas.
A AWS anunciou um novo provedor para o Secrets Store CSI Driver destinado ao Amazon EKS (Elastic Kubernetes Service), que funciona como um add-on gerenciado para a plataforma. Esse novo componente permite que as equipes de desenvolvimento recuperem secrets do AWS Secrets Manager e parâmetros do AWS Systems Manager Parameter Store, montando-os como arquivos nos pods do Kubernetes. A solução é clara em sua proposta: oferecer uma forma segura, confiável e gerenciada de acessar credenciais dentro de ambientes containerizados.
O novo add-on simplifica significativamente o processo de instalação e configuração, funciona tanto em instâncias de Amazon Elastic Compute Cloud (EC2) quanto em nós híbridos, e é mantido com as correções de segurança e atualizações mais recentes. Para equipes brasileiras que trabalham com Kubernetes em ambientes AWS, isso representa uma redução considerável no tempo necessário para implementar práticas seguras de gestão de credenciais.
Por que isso importa para a segurança
Historicamente, um dos maiores desafios em ambientes Kubernetes é evitar o uso de credenciais hardcoded no código-fonte das aplicações. O Secrets Manager já resolve essa questão no contexto geral da AWS, mas integrá-lo nativamente com Kubernetes exigia passos complexos de instalação e manutenção.
O novo provedor funciona como um DaemonSet do Kubernetes de código aberto, trabalhando em conjunto com o Secrets Store CSI Driver mantido pela comunidade Kubernetes. Essa arquitetura permite que o driver de armazenamento de secrets funcione de forma nativa no cluster, sem necessidade de integração customizada.
Benefícios do add-on gerenciado
Os add-ons do EKS da AWS proporcionam instalação e gerenciamento de um conjunto curado de componentes para clusters EKS. Em vez de depender de métodos legados como Helm ou kubectl, o novo add-on reduz significativamente o tempo de setup e aumenta a estabilidade geral dos clusters. Além disso, o gerenciamento centralizado pela AWS garante que patches de segurança e correções de bugs sejam aplicados de forma automática e consistente.
Considerações de segurança
Como em qualquer solução que envolve gestão de credenciais, a segurança é uma preocupação central. A AWS recomenda armazenar secrets em cache na memória quando possível, reduzindo a frequência de acesso ao Secrets Manager. Para equipes que preferem uma experiência totalmente nativa do Kubernetes, o AWS Secrets Manager Agent oferece uma alternativa complementar.
Do ponto de vista de controle de acesso, qualquer entidade IAM (Identity and Access Management) que precise acessar os secrets deve ter permissões explícitas no Secrets Manager. Se usar Parameter Store, também precisa de permissões específicas para ler parâmetros. As políticas de recurso funcionam como mecanismo adicional de controle de acesso, e é especialmente importante quando se acessa secrets de contas AWS diferentes.
O add-on inclui suporte a endpoints FIPS, alinhando-se com exigências de conformidade em ambientes altamente regulados. A AWS fornece uma política IAM gerenciada chamada AWSSecretsManagerClientReadOnlyAccess, que é a recomendação padrão para uso com esse add-on. Para implementar o princípio do menor privilégio, é possível criar políticas customizadas direcionadas apenas aos secrets específicos que cada aplicação precisa acessar.
Guia prático de implementação
Para equipes que desejam começar, a AWS disponibiliza um fluxo de trabalho completo desde a criação do cluster até a recuperação efetiva de um secret. Abaixo, apresentamos um resumo dos passos principais.
Pré-requisitos
Antes de iniciar, certifique-se de ter:
Credenciais AWS configuradas no seu ambiente para permitir chamadas à API
Um arquivo de deployment Kubernetes disponível no repositório do provedor
Criando o cluster EKS
Comece criando uma variável de shell com o nome do seu cluster:
CLUSTER_NAME="my-test-cluster"
Depois, crie o cluster:
eksctl create cluster $CLUSTER_NAME
O eksctl usará automaticamente uma versão recente do Kubernetes e criará todos os recursos necessários para o funcionamento do cluster. Esse comando geralmente leva cerca de 15 minutos.
Criando um secret de teste
Crie um secret chamado addon_secret no Secrets Manager:
A SecretProviderClass é um arquivo YAML que define quais secrets e parâmetros devem ser montados como arquivos no seu cluster. Crie um arquivo chamado spc.yaml com o seguinte conteúdo:
Embora o add-on gerenciado seja a forma recomendada, a AWS também oferece opções alternativas de instalação usando AWS CloudFormation, AWS Command Line Interface (AWS CLI), console de gerenciamento ou a própria API do EKS.
Conclusão
O novo add-on do Secrets Store CSI Driver para EKS representa um avanço significativo na forma como as equipes podem gerenciar credenciais em ambientes Kubernetes hospedados na AWS. Ao oferecer instalação simplificada, gerenciamento centralizado, atualizações de segurança automáticas e integração estreita com o EKS, a solução reduz tanto a complexidade operacional quanto o risco de segurança associado ao armazenamento inadequado de secrets.
Para organizações brasileiras que trabalham com Kubernetes em escala, esse add-on se posiciona como uma alternativa muito mais prática do que métodos legados de instalação, mantendo a flexibilidade e a conformidade com padrões de segurança internacionais. A documentação técnica completa está disponível para equipes que desejam explorar cenários mais avançados e configurações específicas.
Otimizando Inferência de Modelos de Linguagem em Escala
Aplicações modernas de IA enfrentam um desafio crescente: fornecer respostas rápidas e econômicas através de modelos de linguagem grandes, particularmente ao processar documentos extensos ou conversas com múltiplas mensagens. O problema surge quando a inferência de modelos de linguagem se torna cada vez mais lenta e cara à medida que o comprimento do contexto aumenta, com latência crescendo exponencialmente e custos elevados a cada interação.
Essa ineficiência ocorre porque esses modelos precisam recalcular os mecanismos de atenção para todos os tokens anteriores toda vez que geram um novo token. Essa redundância cria sobrecarga computacional significativa e alta latência em sequências longas.
Entendendo o Cache KV e o Roteamento Inteligente
O cache KV (par chave-valor) resolve esse gargalo armazenando e reutilizando os vetores de chave-valor de cálculos anteriores, reduzindo drasticamente a latência de inferência e o tempo até o primeiro token (TTFT, ou Tempo até o Primeiro Token).
O roteamento inteligente complementa essa abordagem ao direcionar requisições com prompts compartilhados para a mesma instância de inferência, maximizando a eficiência do cache KV. Quando uma nova requisição chega, o sistema a envia para uma instância que já processou o mesmo prefixo, permitindo reutilizar os dados em cache e acelerar o processamento.
No entanto, configurar e gerenciar o framework correto para cache KV e roteamento inteligente em escala produção é complexo e requer ciclos experimentais longos. A AWS anunciou que o Amazon SageMaker HyperPod agora oferece essas capacidades através do Operador de Inferência HyperPod, simplificando significativamente essa implementação.
Capacidades Principais do Cache KV Escalonado Gerenciado
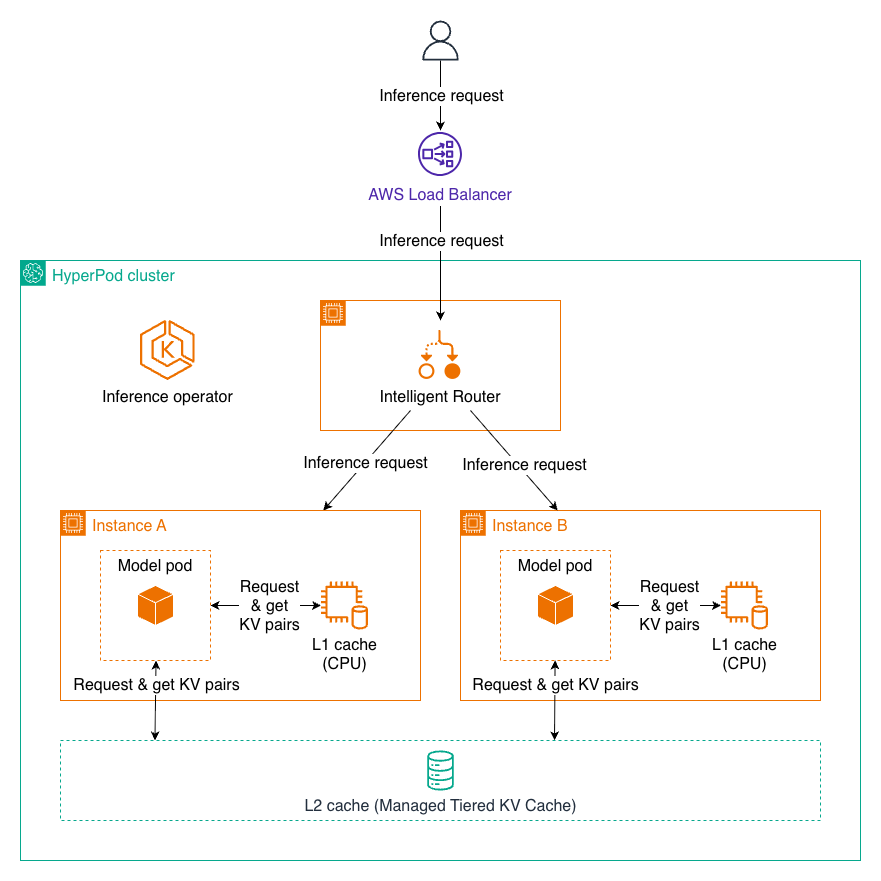
Arquitetura em Dois Níveis
O cache KV escalonado gerenciado funciona através de uma arquitetura em dois níveis, otimizada para diferentes padrões de acesso:
Cache L1 (Local): Reside na memória da CPU de cada nó de inferência e oferece acesso extremamente rápido. O cache gerencia automaticamente alocação de memória e políticas de despejo para otimizar o conteúdo armazenado em cache de maior valor.
Cache L2 (Distribuído): Opera como uma camada de cache distribuída abrangendo todo o cluster, permitindo compartilhamento de cache entre múltiplas instâncias de modelo. A AWS oferece dois backends para o cache L2:
Cache KV Escalonado Gerenciado (recomendado): Uma solução de memória disagregada do HyperPod que oferece escalabilidade excelente para pools de terabytes, baixa latência, otimização de rede AWS, design consciente de GPU com suporte zero-copy e eficiência de custos em escala.
Redis: Simples de configurar, funciona bem para cargas de trabalho pequenas e médias, com rico ecossistema de ferramentas e integrações.
Quando uma requisição chega, o sistema primeiro verifica o cache L1 para pares KV necessários. Se encontrados, são utilizados imediatamente com latência mínima. Se não encontrados em L1, o sistema consulta o cache L2. Se localizados lá, os dados são recuperados e opcionalmente promovidos para L1 para acesso mais rápido no futuro. Apenas se os dados não existirem em nenhum cache, o sistema executa o cálculo completo, armazenando os resultados em ambas as camadas para reutilização futura.
Fluxo de requisições de inferência com cache KV e roteamento inteligente. Imagem original — fonte: Aws
Estratégias de Roteamento Inteligente
O roteamento inteligente oferece quatro estratégias configuráveis para otimizar a distribuição de requisições conforme as características da carga de trabalho:
Roteamento Ciente de Prefixo (padrão): Mantém uma estrutura de árvore rastreando quais prefixos estão em cache em quais endpoints, oferecendo desempenho geral robusto. Ideal para conversas multi-turno, bots de atendimento ao cliente com saudações padrão e geração de código com importações comuns.
Roteamento Ciente de KV: Oferece gerenciamento de cache mais sofisticado através de um controlador centralizado que rastreia localizações de cache e trata eventos de despejo em tempo real. Excele em threads de conversas longas, fluxos de trabalho de processamento de documentos e sessões estendidas de programação onde eficiência máxima de cache é crítica.
Roteamento Round-robin: Abordagem mais simples, distribuindo requisições uniformemente entre workers. Melhor para cenários onde requisições são independentes, como trabalhos de inferência em lote, chamadas de API stateless e testes de carga.
Impacto em Cenários do Mundo Real
As otimizações delivram benefícios tangíveis para aplicações práticas. Equipes jurídicas analisando contratos de 200 páginas agora recebem respostas instantâneas para perguntas de acompanhamento em vez de aguardar mais de 5 segundos por consulta. Chatbots de saúde mantêm fluxo de conversa natural através de diálogos com pacientes de 20+ turnos. Sistemas de atendimento ao cliente processam milhões de requisições diárias com desempenho superior e custos de infraestrutura reduzidos.
Essas otimizações tornam análise de documentos, conversas multi-turno e aplicações de inferência de alta taxa de transferência viáveis economicamente em escala empresarial.
Implementando Cache KV Escalonado Gerenciado
Pré-requisitos
Antes de começar, você precisará:
Um cluster HyperPod criado com Amazon EKS (Elastic Kubernetes Service) como orquestrador
Status do cluster verificado como InService
Operador de inferência verificado e em execução
Para criar um cluster, acesse o console SageMaker AI, navegue para HyperPod Clusters e selecione Gerenciamento de Cluster. Escolha criar um novo cluster orquestrado por Amazon EKS. Para detalhes de configuração do cluster, consulte a documentação sobre criação de um cluster SageMaker HyperPod com orquestração Amazon EKS.
Você pode habilitar essas funcionalidades adicionando configurações ao seu arquivo CRD (Definição de Recurso Customizado) InferenceEndpointConfig. Para um exemplo completo, visite o repositório de exemplos da AWS no GitHub.
O arquivo de configuração define variáveis de ambiente e especificações de cache. Para o cache L1, você habilita a cache na memória local. Para o cache L2, você especifica o backend (armazenamento em camadas ou Redis). A configuração de roteamento inteligente permite que você escolha a estratégia que melhor se ajusta a seu padrão de carga de trabalho.
O seguinte exemplo mostra a estrutura básica de configuração:
Após preparar o manifesto, aplique a configuração e verifique o status dos pods. O sistema criará automaticamente pods de worker para modelo e um roteador inteligente para gerenciar distribuição de requisições.
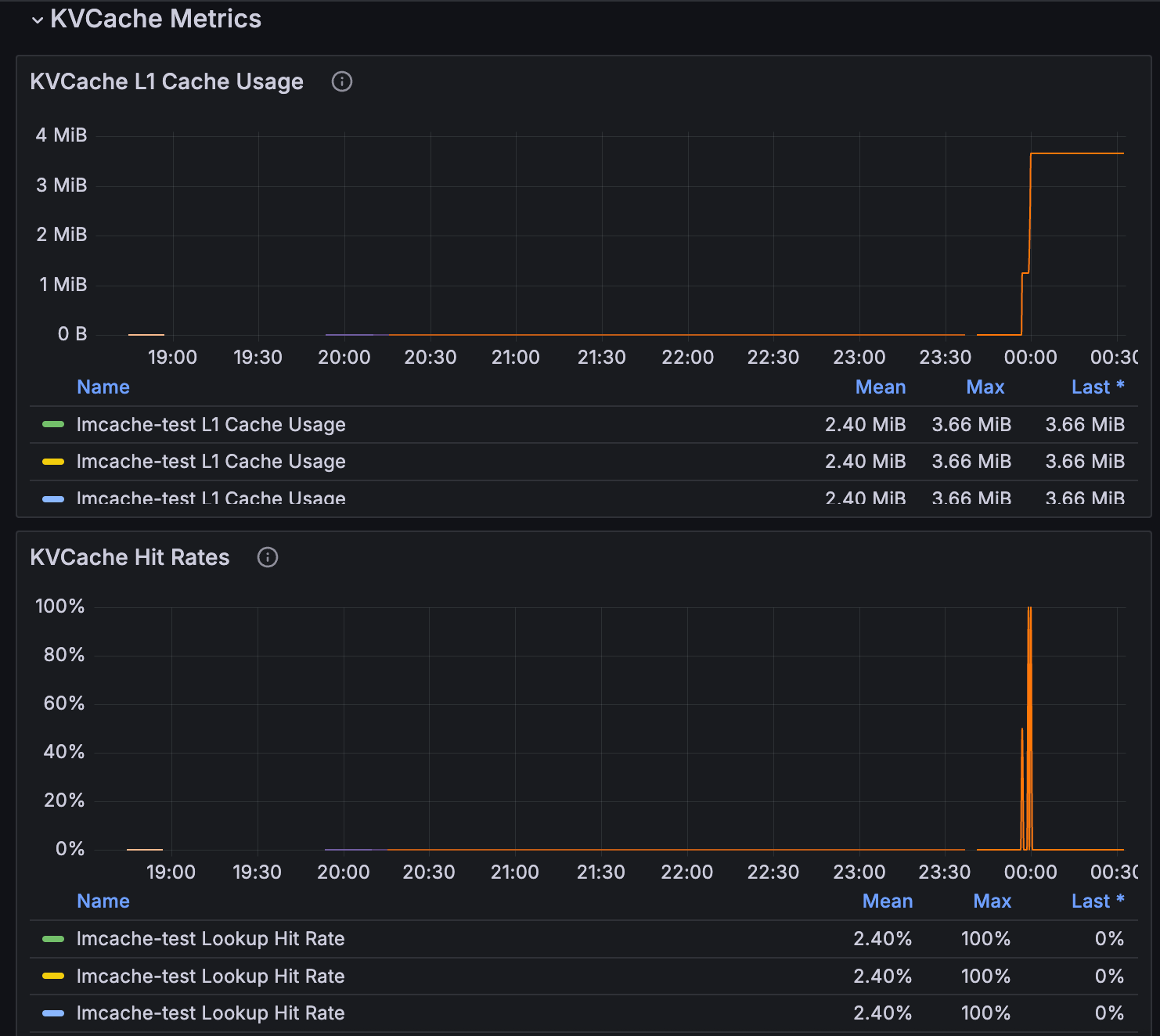
Monitoramento e Observabilidade
Métricas de Cache KV disponíveis no painel de inferência. Imagem original — fonte: Aws
As métricas de cache KV estão disponíveis no painel de inferência e incluem uso de cache L1, taxas de acerto, eficiência de roteamento e latência de requisição, fornecendo visibilidade completa sobre o desempenho da sua implantação.
Resultados de Desempenho
A AWS conduziu testes abrangentes para validar melhorias de desempenho em implantações reais de LLM. Os testes utilizaram o modelo Llama-3.1-70B-Instruct implantado em 7 réplicas em instâncias p5.48xlarge (cada uma equipada com oito GPUs NVIDIA), sob padrão de tráfego de carga constante.
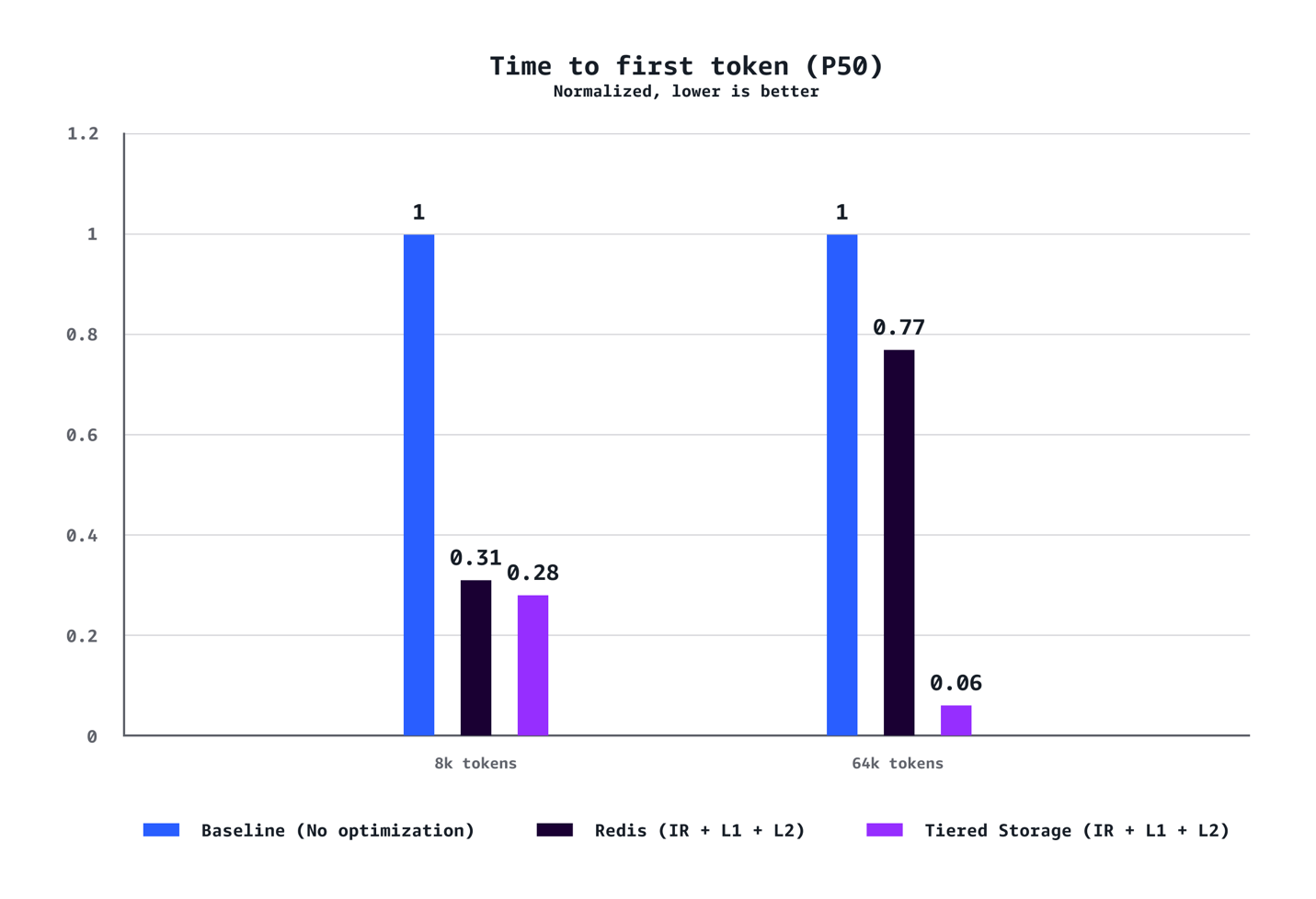
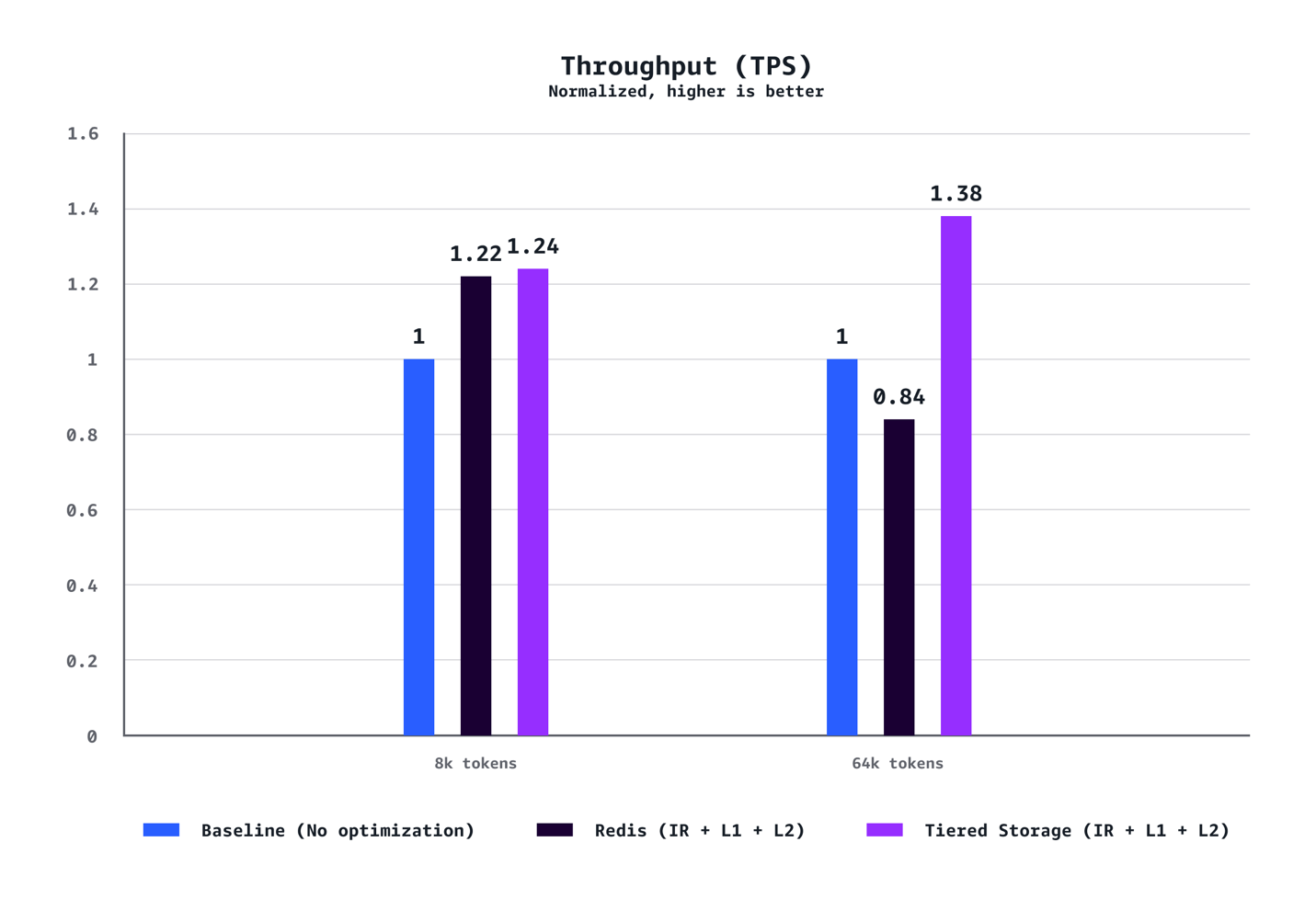
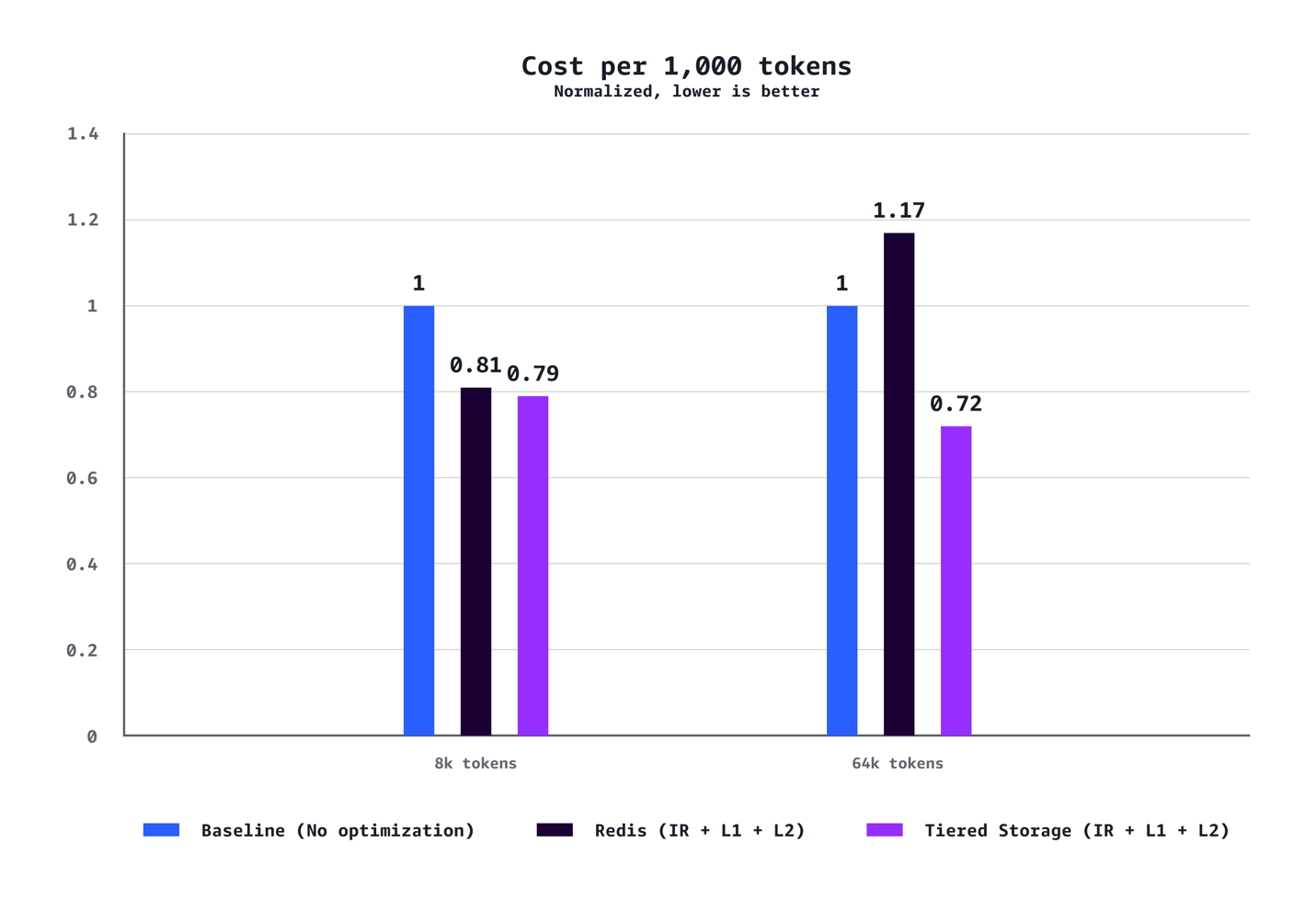
Redução de tempo até o primeiro token no percentil P90. Imagem original — fonte: AwsRedução de tempo até o primeiro token no percentil P50. Imagem original — fonte: AwsAumento de taxa de transferência em transações por segundo. Imagem original — fonte: AwsRedução de custo por 1.000 tokens. Imagem original — fonte: Aws
Para contextos médios (8k tokens): O sistema alcançou redução de 40% no tempo até o primeiro token no P90, redução de 72% no P50, aumento de 24% na taxa de transferência e redução de 21% em custos comparado às configurações baseline sem otimização.
Para cargas de trabalho com contextos longos (64k tokens): Os benefícios são ainda mais pronunciados, com redução de 35% no TTFT no P90, redução de 94% no P50, aumento de 38% na taxa de transferência e economia de 28% em custos.
Os ganhos em otimização aumentam dramaticamente com o comprimento do contexto. Enquanto cenários de 8k tokens demonstram melhorias sólidas em todas as métricas, cargas de trabalho de 64k tokens experimentam ganhos transformadores que fundamentalmente mudam a experiência do usuário.
Os testes também confirmaram que o armazenamento em camadas gerenciado pela AWS superou consistentemente o cache L2 baseado em Redis em todos os cenários. O backend de armazenamento em camadas ofereceu melhor latência e taxa de transferência sem o overhead operacional de gerenciar infraestrutura Redis separada, tornando-o a escolha recomendada para a maioria das implantações.
Diferentemente de otimizações tradicionais que exigem compromissos entre custo e velocidade, essa solução oferece ambos simultaneamente.