Contexto: Uma Nova Geração do Security Hub
A AWS Security Hub acaba de receber uma renovação significativa. A plataforma agora oferece capacidades expandidas para agregar, correlacionar e contextualizar alertas de segurança em múltiplas contas da Amazon Web Services (AWS). Enquanto isso, a versão anterior recebeu uma nova denominação: AWS Security Hub CSPM, que continua disponível como um serviço especializado focado em gerenciamento de postura de segurança em nuvem e agregação de descobertas.
Ambas as versões compartilham uma funcionalidade importante: as regras de automação. Esse recurso permite atualizar automaticamente campos de descobertas quando critérios específicos são atendidos. Porém, existe um desafio: as regras criadas em uma versão não sincronizam com a outra. Isso significa que usuários migrando do Security Hub CSPM para a nova plataforma precisam recriar suas automações manualmente — ou encontrar uma forma mais eficiente de fazer essa transição.
O Problema de Compatibilidade de Esquemas
Diferenças Fundamentais Entre os Esquemas
O Security Hub CSPM utiliza o AWS Security Finding Format (ASFF) como esquema para suas descobertas. Esse formato é central para como as regras de automação funcionam — elas analisam campos ASFF específicos usando operadores (como igualdade ou contém) para determinar quando ativar ações que modificam outros campos ASFF.
A nova versão do Security Hub, por sua vez, adota o Open Cybersecurity Schema Framework (OCSF), um padrão aberto amplamente adotado no setor de cibersegurança. Essa mudança traz melhorias em interoperabilidade e integração, mas cria um obstáculo para usuários existentes: as regras ASFF não são diretamente compatíveis com OCSF.
Desafios Específicos da Migração
Nem todas as regras podem ser migradas automaticamente. Alguns campos ASFF não possuem correspondentes diretos em OCSF. Por exemplo, campos como Criticality, GeneratorId e RelatedFindingsId não têm mapeamento na nova estrutura. Além disso, algumas ações suportadas no ASFF — como aquelas que modificam Confidence, VerificationState ou UserDefinedFields — também não estão disponíveis no OCSF.
Isso significa que regras existentes podem ser migradas de forma parcial, preservando apenas as ações que têm equivalente no novo esquema, ou podem exigir redesenho completo.
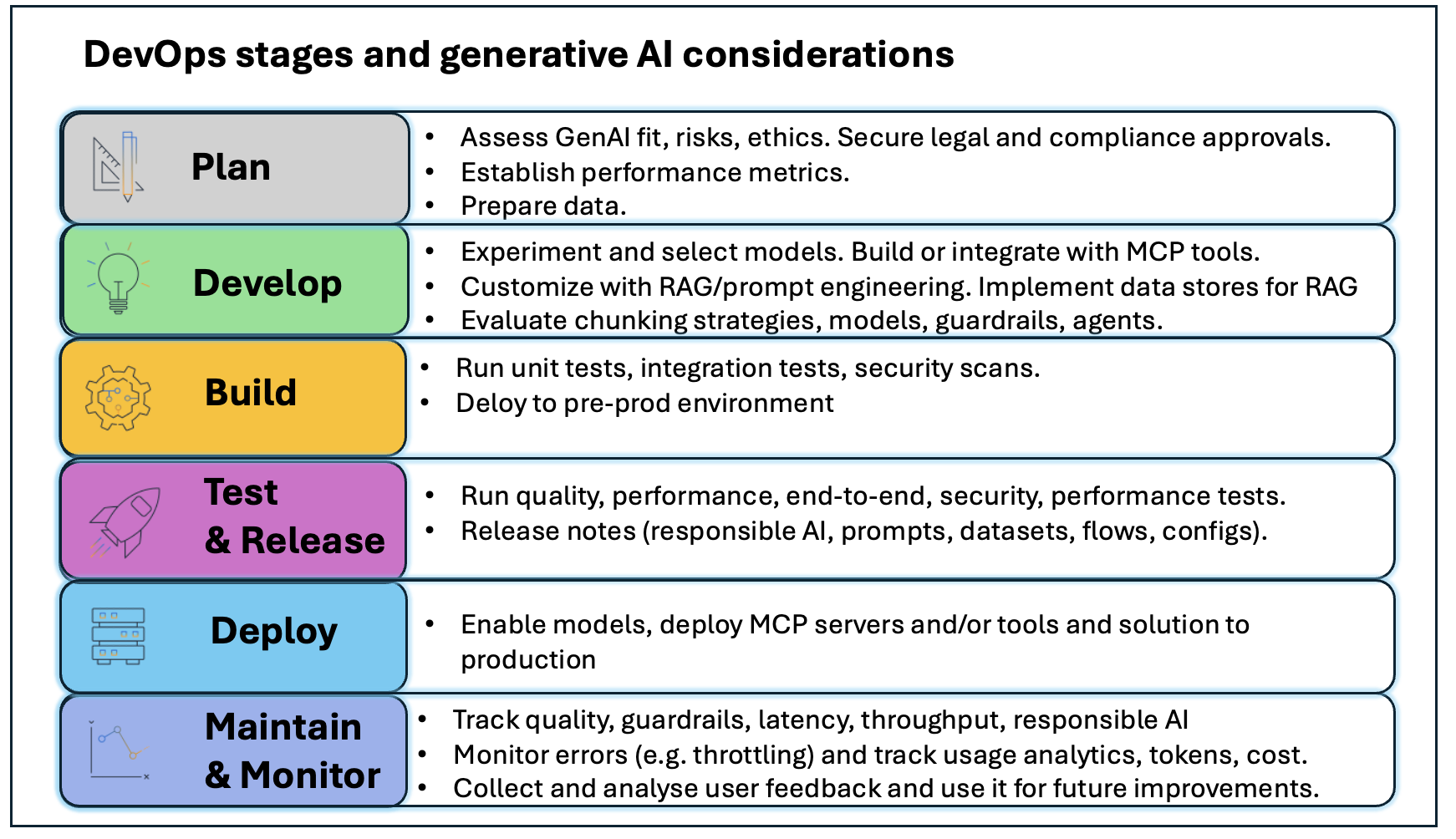
A Solução: Automatizando a Migração
Como Funciona a Ferramenta
A AWS oferece uma solução pronta baseada em scripts Python que automatiza o processo de migração. O fluxo funciona em etapas bem definidas:
Descoberta: A solução escaneia seu ambiente Security Hub CSPM para identificar todas as regras de automação existentes em múltiplas regiões.
Análise: Cada regra é avaliada para determinar se pode ser totalmente migrada, parcialmente migrada ou se exige intervenção manual, baseado na compatibilidade entre campos ASFF e OCSF.
Transformação: Regras compatíveis são convertidas automaticamente de ASFF para OCSF usando mapeamentos pré-definidos.
Geração de Template: A solução cria um template do AWS CloudFormation contendo as regras transformadas, preservando sua ordem original e contexto regional.
Implantação e Validação: O template é revisado e implantado, criando as regras migradas em estado desabilitado por padrão, permitindo testes antes da ativação.

Componentes da Solução
A ferramenta é composta por quatro scripts Python que trabalham de forma coordenada:
Orquestrador: Coordena descoberta, transformação e geração, além de gerenciar relatórios e logs.
Descoberta de Regras: Identifica e extrai regras de automação existentes do Security Hub CSPM em regiões especificadas.
Transformação de Esquema: Converte regras de ASFF para OCSF utilizando o mapeamento de campos.
Geração de Template: Cria templates CloudFormation prontos para implantação.
Mapeamento de Campos: ASFF para OCSF
Para entender o escopo da migração, é importante conhecer como os campos se relacionam. Campos ASFF usados como critérios em regras mapeiam para seus equivalentes OCSF da seguinte forma:
Campos como AwsAccountId, ComplianceStatus, Confidence, CreatedAt, Description, SeverityLabel e Title possuem correspondentes diretos. Porém, Criticality, GeneratorId, NoteText, ResourceApplicationArn, UserDefinedFields e VerificationState são marcados como indisponíveis (N/A) e não podem ser migrados automaticamente.
Regras que dependem desses campos precisam ser redesenhadas manualmente na nova plataforma.
Da mesma forma, ações suportadas como modificação de Severity e atualização de Status são totalmente compatíveis. Porém, ações que envolvem Confidence, Criticality, RelatedFindings e VerificationState não possuem equivalente e precisarão ser recriadas ou removidas.
Conceitos-Chave Para a Migração
Estado Padrão das Regras Migradas
Por segurança, todas as regras migradas são criadas em estado desabilitado. Isso permite que você as revise, valide o comportamento e só então as ative. A solução pode opcionalmente criar regras já habilitadas, mas essa abordagem não é recomendada.
Ordem e Prioridade de Regras
Tanto no Security Hub CSPM quanto no novo Security Hub, a ordem de execução das regras importa — especialmente quando múltiplas regras podem afetar os mesmos campos. A solução preserva a ordem original de suas regras. Se você já possui regras no Security Hub novo, as regras migradas começam sua numeração após as existentes.
Quando múltiplas regiões estão envolvidas em um cenário de Região Base (home region), a ordem é preservada por região e agrupada na sequência final. Por exemplo: primeiramente todas as regras da Região 1, depois da Região 2, e assim por diante.
Regiões: Base vs. Individual
O Security Hub CSPM opera com regras baseadas em regiões — uma regra criada em uma região afeta apenas as descobertas geradas naquela região, mesmo se você usa uma região base para agregação central.
O novo Security Hub funciona de forma diferente: regras definidas na região base são aplicadas a todas as regiões vinculadas. Regras não podem ser criadas em regiões vinculadas, apenas em regiões não vinculadas, onde afetarão apenas suas descobertas locais.
A solução oferece dois modos de implantação para lidar com essas diferenças:
Modo Região Base: Usa regiões especificadas e recria as regras na região base, adicionando um critério extra que preserva o contexto regional original. Um único template CloudFormation é gerado.
Modo Região-por-Região: Gera um template separado para cada região, preservando o comportamento regional das regras originais. Templates são implantados individualmente.
Se você usa uma região base com algumas regiões vinculadas e outras não, execute o Modo Região Base para a região base e regiões vinculadas, depois o Modo Região-por-Região para regiões não vinculadas.
Pré-Requisitos e Configuração
Softwares Necessários
Antes de iniciar, você precisa de:
- AWS Command Line Interface (AWS CLI) na versão mais recente
- Python 3.12 ou posterior
- Pacotes Python: boto3 (versão mais recente) e pyyaml (versão mais recente)
Permissões Necessárias
Sua conta AWS precisa ter permissões para:
Descoberta e transformação: securityhub:ListAutomationRules, securityhub:BatchGetAutomationRules, securityhub:GetFindingAggregator, securityhub:DescribeHub, securityhub:ListAutomationRulesV2.
Implantação de template: cloudformation:CreateStack, cloudformation:UpdateStack, cloudformation:DescribeStacks, cloudformation:CreateChangeSet, cloudformation:DescribeChangeSet, cloudformation:ExecuteChangeSet, cloudformation:GetTemplateSummary, securityhub:CreateAutomationRuleV2, securityhub:UpdateAutomationRuleV2, securityhub:DeleteAutomationRuleV2, securityhub:GetAutomationRuleV2, securityhub:TagResource, securityhub:ListTagsForResource.
Configuração da Conta AWS
O Security Hub suporta um modelo de administrador delegado quando usado com AWS Organizations. Nesse modelo, um administrador delegado centraliza a gestão de descobertas e configuração de segurança em toda a organização.
Regras de automação devem ser criadas na conta do administrador delegado, na região base e em regiões não vinculadas. Contas membro não podem criar suas próprias regras.
A recomendação é usar a mesma conta como administrador delegado tanto para Security Hub CSPM quanto para o novo Security Hub, garantindo consistência. Configure sua AWS CLI com credenciais dessa conta antes de executar a migração.
Embora a solução seja principalmente para deployments com administrador delegado, também funciona com implementações de Security Hub em conta única.
Passo a Passo: Executando a Migração
Preparação e Execução
Para iniciar o processo de migração:
Primeiro, clone o repositório da ferramenta de migração. Acesse o repositório de amostras da AWS no GitHub e execute:
git clone https://github.com/aws-samples/sample-SecurityHub-Automation-Rule-Migration.gitEm seguida, consulte o arquivo README do repositório para obter as instruções de implementação mais atualizadas. Siga os passos especificados para executar os scripts. O processo gerará um template CloudFormation com suas regras de automação transformadas.
Implante o template usando a AWS CLI ou o console. Veja como criar uma stack no console do CloudFormation para detalhes completos.
Validação e Ativação das Regras
Após a implantação, acesse o console do Security Hub para revisar suas regras migradas. Lembre-se: elas começam desabilitadas por padrão.
Para cada regra migrada:
- Acesse a seção de Automações no Security Hub
- Selecione a regra e escolha Editar
- Revise seus critérios e ações com cuidado
- Use a opção de visualizar descobertas correspondentes para validar o comportamento esperado
- Se tudo estiver correto, ative a regra
Preste atenção especial às regras marcadas como “parcialmente migradas” em sua descrição. Isso significa que uma ou mais ações da regra original não têm equivalente no novo Security Hub. Essas regras podem se comportar diferentemente do que você espera e precisarão de revisão.
A solução também gera um relatório detalhando quais regras foram parcialmente migradas e especificando quais ações não puderam ser replicadas. Revise esse relatório cuidadosamente antes de habilitar essas regras.
Conclusão
A nova geração do AWS Security Hub oferece capacidades significativamente melhoradas para agregar, correlacionar e contextualizar descobertas de segurança. Embora a mudança de esquema de ASFF para OCSF traga benefícios em termos de interoperabilidade e integrações com parceiros, ela também exige que regras de automação existentes sejam transformadas.
A solução de migração automatizada simplifica esse processo, executando a descoberta, transformação e geração de templates de forma coordenada. Ao seguir as melhores práticas recomendadas — revisar o relatório de migração, testar regras em estado desabilitado, validar correspondências e ativar gradualmente — você consegue manter seus fluxos de trabalho de automação de segurança funcionando sem interrupções.
Para mais informações sobre o Security Hub e suas capacidades ampliadas, consulte a documentação oficial do Security Hub.
Fonte
Security Hub CSPM automation rule migration to Security Hub (https://aws.amazon.com/blogs/security/security-hub-cspm-automation-rule-migration-to-security-hub/)